如何利用Xpath抓取京东网商品信息

前几小编分别利用Python正则表达式和BeautifulSoup爬取了京东网商品信息,今天小编利用Xpath来为大家演示一下如何实现京东商品信息的精准匹配~~
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
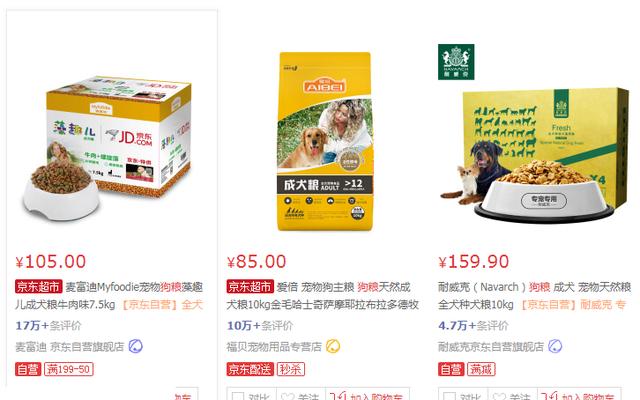
京东网狗粮商品
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:
https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用bs4选择器进行下一步的数据采集。
商品信息在京东官网上的部分网页源码如下图所示:

狗粮信息在京东官网上的网页源码
仔细观察源码,可以发现我们所需的目标信息是存在<li data-sku="/*/*/*/*/*" class="gl-item">标签下的,那么接下来我们就像剥洋葱一样,一层一层的去获取我们想要的信息。
通常URL编码的方式是把需要编码的字符转化为%xx的形式,一般来说URL的编码是基于UTF-8的,当然也有的于浏览器平台有关。在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
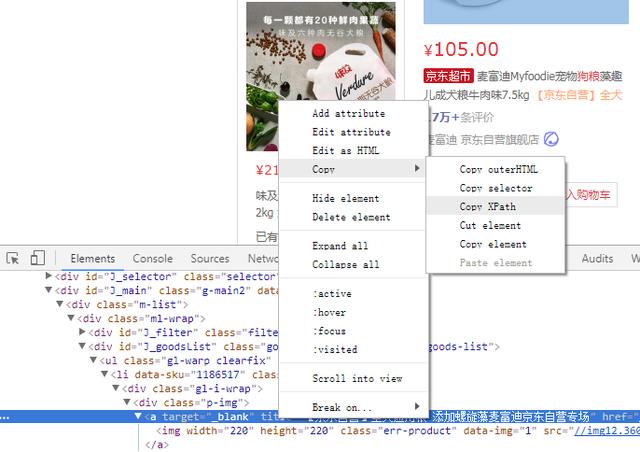
在线复制Xpath表达式
很多小伙伴都觉得Xpath表达式很难写,其实掌握了基本的用法也就不难了。在线复制Xpath表达式如上图所示,可以很方便的复制Xpath表达式。但是通过该方法得到的Xpath表达式放在程序中一般不能用,而且长的没法看。所以Xpath表达式一般还是要自己亲自上手。
直接上代码,利用Xpath去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:
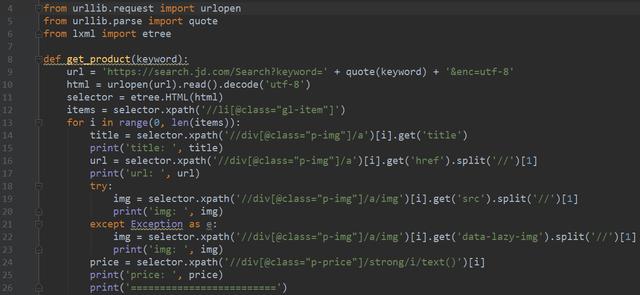
爬虫代码
在这里,小编告诉大家一个Xpath表达式匹配技巧。之前看过好几篇文章,大佬们都推荐Xpath表达式使用嵌套匹配的方式。在本例中,首先定义items,如下所示:
items = selector.xpath('//li[@class="gl-item"]')
之后通过range函数,逐个从网页中进行匹配目标信息,而不是直接通过复制Xpath表达式的方式一步到位。希望小伙伴们以后都可以少入这个坑~~
最后得到的效果图如下所示:
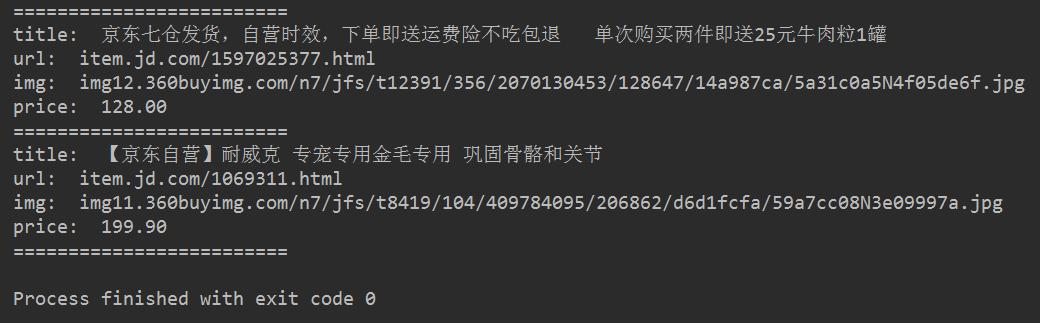
最终效果图
新鲜的狗粮再一次出炉咯~~~
小伙伴们,有没有发现利用Xpath来获取目标信息比正则表达式要简单一些呢?
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
如何利用Xpath抓取京东网商品信息的更多相关文章
- 如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式.BeautifulSoup.Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~ CSS选择器 目前 ...
- 如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了.不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
- 利用xpath爬取招聘网的招聘信息
爬取招聘网的招聘信息: import json import random import time import pymongo import re import pandas as pd impor ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- 使用selenium+BeautifulSoup 抓取京东商城手机信息
1.准备工作: chromedriver 传送门:国内:http://npm.taobao.org/mirrors/chromedriver/ vpn: selenium BeautifulSo ...
随机推荐
- Java pdf转高清图片
为什么80%的码农都做不了架构师?>>> package com.hyb.kai.web.controller; import java.awt.image.BufferedIm ...
- C++编程入门--No.6
题目:用*号输出字母C的图案. 程序分析:可先用'*'号在纸上写出字母C,再分行输出. #include <bits/stdc++.h> using namespace std; int ...
- P4430 小猴打架、P4981 父子
prufer编码 当然你也可以理解为 Cayley 公式,其实这个公式就是prufer编码经过一步就能推出的 P4430 小猴打架 P4981 父子 这俩题差不多 先说父子,很显然题目就是让你求\(n ...
- 微软2016校园招聘在线笔试之Magic Box
题目1 : Magic Box 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 The circus clown Sunny has a magic box. When ...
- qt creator源码全方面分析(4-2)
目录 global头文件 global.h xx.h global头文件 插件的本质就是动态链接库,对于库,需要导出符号,供用户导入使用.在qt creator的源码中,存在固定的导入导出模式. gl ...
- Unity 游戏框架搭建 2019 (四十四、四十五) 关于知识库的小结&独立的方法和独立的类
在上一篇,我们完成了一个定时功能,并且接触了 Action 和委托.lambda 表达式这些概念. 到目前为止,我们的库作为知识收录这个功能来说,已经非常好用了,由于使用了 partial 关键字,所 ...
- Codeforces 1332 D. Walk on Matrix(构造矩阵)
怎么构造呢? \(首先我们不可能去构造一个2000*2000的矩阵,那太复杂了\) \(也许我们可以看看2*2的矩阵??\) \[\left[ \begin{matrix} x&y\\ z&a ...
- Pycharm修改HTML模板
- python学习笔记 Day4
1.函数返回值分析 li = [1,2,3,4] li2 = [1,2,3,4] def f1(args): args.append(55) li = f1(li) print(li) f1(li2) ...
- JAVA设计模式之组合模式(composite)
组合模式:树状结构专用模式 代码如下: package com.srr.dp.composite; import java.util.ArrayList; import java.util.List; ...