大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先来看下Mapreduce的局限性和Spark如何做的改进.
Spark概述
MapReduce局限性
1 仅支持Map和Reduce两种操作
2 处理效率极低
- Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据;
- 任务调度和启动开销大
- 无法充分利用内存
- Map端和Reduce端均需要排序
3 不适合迭代计算(如机器学习,图计算等),交互处理(数据挖掘)和流式处理(实时日志分析)
4 MapReduce编程不够灵活
Spark的特点
1 高效(比MapReduce快10~100倍)
- 内存计算引擎,提供Cache机制来支持需要反复迭代计算或多次数据共享,减少数据读取的IO开销
- DAG引擎,减少多次计算之间中间结果写到HDFS的开销
- 使用多线程模型来减少task启动开销,shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
2 易用
提供了丰富的API,支持Java, Scala, Python和R四中语言
代码量比MapReduce少2~5倍
3 与Hadoop集成
- 读写HDFS/Hbase
- 与YARN集成
小结
IO和内存上: MapReduce数据从Map产出会写本地磁盘,并且排序, Reduce读取Map产出的数据计算后再产出到HDFS. 所以MapReduce的IO需要的多,并且数据来回在内存中加载释放. 而Spark把数据加载到内存中之后(DAG计算引擎)直到计算出结果才产出到HDFS(如果数据量超过内存量,也会溢写到磁盘).
调度上: Spark的每个Executor都有一个线程池(有一个线程公用的cache,省去进程频繁启停的开销),每一个task占用其中一个线程.
API上:MapReduce只有Map和Reduce操作, Spark有丰富的API使编程非常方便灵活.
Spark核心概念
RDD(Resilient Distributed Datasets)
弹性分布式数据集
- 分布在集群中的只读对象集合(由多个Partition构成)
- 可以存储在磁盘或内存中(多种存储级别)
- 通过并行“转换”操作构造
- 失效后自动重构
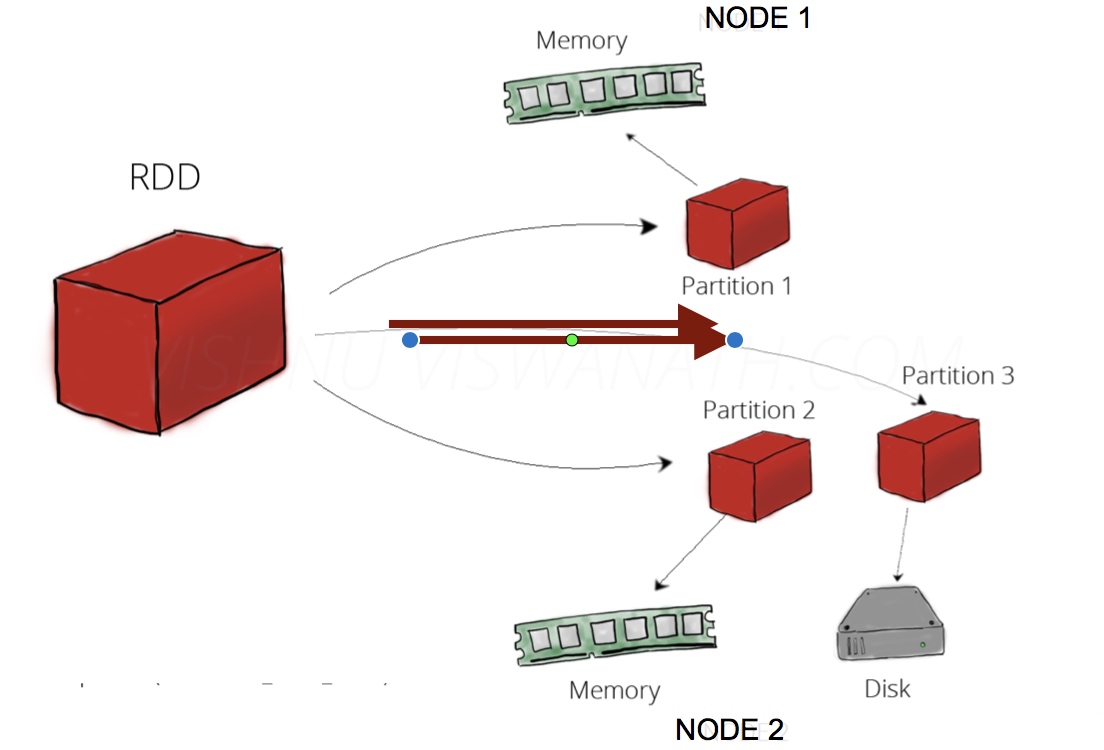 

RDD可以理解为一份数据在集群上的抽象, 被分为多个分区, 每个分区分布在集群不同的节点上(如上图), 从而让RDD中的数据可以被并行操作(分布式数据集).
RDD有一个重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition, 因为节点故障 导致数据丢了, 那么RDD会自动通过自己的数据来源重新计算该partition.
RDD的基本操作
RDD有两种基本操作:Transformation 和 Action
Transformation
- 通过Scala集合或者Hadoop数据集构造一个新的RDD
- 通过已有的RDD产生新的RDD(RDD不可修改)
比如:
构造数据集:
val rdd1 = SparkContext.textFile("hdfs://xxx")
val rdd2 = sc.parallelize( Array(1,2,3,4,5))
Transformation:
// map(输入一行,产出一行)
val a = sc.parallelize(1 to 9, 3)
val b = a.map(x => x*2)
a.collect = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
b.collect = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
//上述例子中把原RDD中每个元素都乘以2来产生一个新的RDD //filter(过滤条件)
val c = a.filter(x => x>5)
c.collect = Array(6, 7, 8, 9)
//上述例子中过滤支取了a中>5的值 //flatMap(输入一行,产出多行)
val d = a.flatMap(x=> Array(x, x*10))
d.collect = Array(1, 10, 2, 20, 3, 30, 4, 40, 5, 50, 6, 60, 7, 70, 8, 80, 9, 90)
//上述例子中,把a中的一个元素变成了 a 和 a的10倍 2个元素.
Action
- 通过RDD计算得到一个或者一组值
比如:
//collect(把结果拿到driver端)
//比如transformation中的collect用法 //count(计算行数)
scala> a.count
res5:Long = 9 //reduce(reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止)
a.collect
res6: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
a.reduce((x, y) => x + y)
res7: Int = 45
小结
接口定义方式不同
- Transformation: RDD[x] -> RDD[y]
- Action: RDD[x] -> Z (Z不是一个RDD,可能是基本类型,数组等)
惰性执行(Lazy Exception)
- Transformation 只会记录RDD转换关系,并不会触发计算
- Action是出发程序分布式执行的算子
SparkRDD cache/persist
允许将RDD缓存到内存或者磁盘上,以便于重用
Spark提供了多种缓存级别,以便于用户根据实际需求进行调整
 

RDD cache的使用
val data = sc.textFile(“hdfs://nn:8020/input”)
data.cache() //实际上是data.persist(StorageLevel.MEMORY_ONLY)
//data.persist(StorageLevel.DISK_ONLY_2)
原文链接:
大话Spark(1)-Spark概述与核心概念
大话Spark(1)-Spark概述与核心概念的更多相关文章
- 003-spring-data-elasticsearch 3.0.0.0使用【一】-spring-data之概述、核心概念、查询方法、定义Repository接口
零.概述 Spring Data Elasticsearch项目提供了与Elasticsearch搜索引擎的集成.Spring Data Elasticsearch的关键功能区域是一个POJO中心模型 ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Spark SQL源代码分析之核心流程
/** Spark SQL源代码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几 ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- 科普Spark,Spark核心是什么,如何使用Spark(1)
科普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html 阅读本文章可以带着下面问题:1.Spark基于 ...
- Spark入门,概述,部署,以及学习(Spark是一种快速、通用、可扩展的大数据分析引擎)
1:Spark的官方网址:http://spark.apache.org/ Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL.Spark Streaming.Graph ...
- Spark Streaming揭秘 Day2-五大核心特征
Spark Streaming揭秘 Day2 五大核心特征 引子 书接上回,Streaming更像Spark上的一个应用程序,会有多个Job的配合,是最复杂的Spark应用程序.让我们先从特征角度进行 ...
随机推荐
- 洛谷3243 [HNOI2015]菜肴制作
题目戳这里 Solution 错误的想法:正向建图,然后从入度为0的点选出最小u的开始输出,然后找出u连接的点v,并把v的度数减一,再次把入度为0的点加入小根堆,这样显然有错,因为只能局部保证最小,后 ...
- android 服务与多线程
android服务是执行在UI主线程的.一下是代码demo: package com.example.testservice; import android.os.Bundle; import and ...
- MySql索引建立规则
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引.本小节将向读者介绍一些索引的设计原则. 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确 ...
- DataGridView自定义RichTextBox列
https://www.codeproject.com/Articles/31823/RichTextBox-Cell-in-a-DataGridView-2 RichText是用图片显示的,当Sel ...
- Ruby 文件 FILE
FileUtils.makedirs(LOCAL_DIR) unless File.exists?LOCAL_DIR require 'fileutils' Dir.mkdir(DATA_DIR) u ...
- line -1: Validation of SOAP-Encoded messages not supported
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd=" ...
- FastJson 输出值 首字母大小写问题
解决方案: 1. 如果你的项目由多个模块且为分布式部署, 则可考虑使用设置System.property 2. 一般只是极少数的代码出现此情况, 那么建议直接在你的单例Service初始化时, 在静态 ...
- 深入理解JVM - Java内存区域与内存溢出异常 - 第二章
一 运行时数据区域 JVM在执行Java程序的过程中会把它管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以及创建和销毁的时间. 程序计数器 程序计数器(Program Counter ...
- RQNOJ 514 字串距离:dp & 字符串
题目链接:https://www.rqnoj.cn/problem/514 题意: 设有字符串X,我们称在X的头尾及中间插入任意多个空格后构成的新字符串为X的扩展串,如字符串X为”abcbcd”,则字 ...
- 关于MVC模板渲染的一点小事type="text/template"
先上一个demo,简单粗暴,请自便 <!DOCTYPE html> <html> <head lang="en"> <meta chars ...