web scraper——简单的爬取数据【二】
在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧。
http://top.baidu.com/buzz?b=1&fr=20811
文本太长,大部分是图片,所以上下操作视频吧,视频爬取的是昵称不是百度热点数据
链接:https://pan.baidu.com/s/1W-8kGDznZZjoQIk1e6ikfQ
提取码:3dj7
爬取步骤
创建站点
打开百度热点,ctrl+shit+i进入检测工具,打开web scraper创建站点
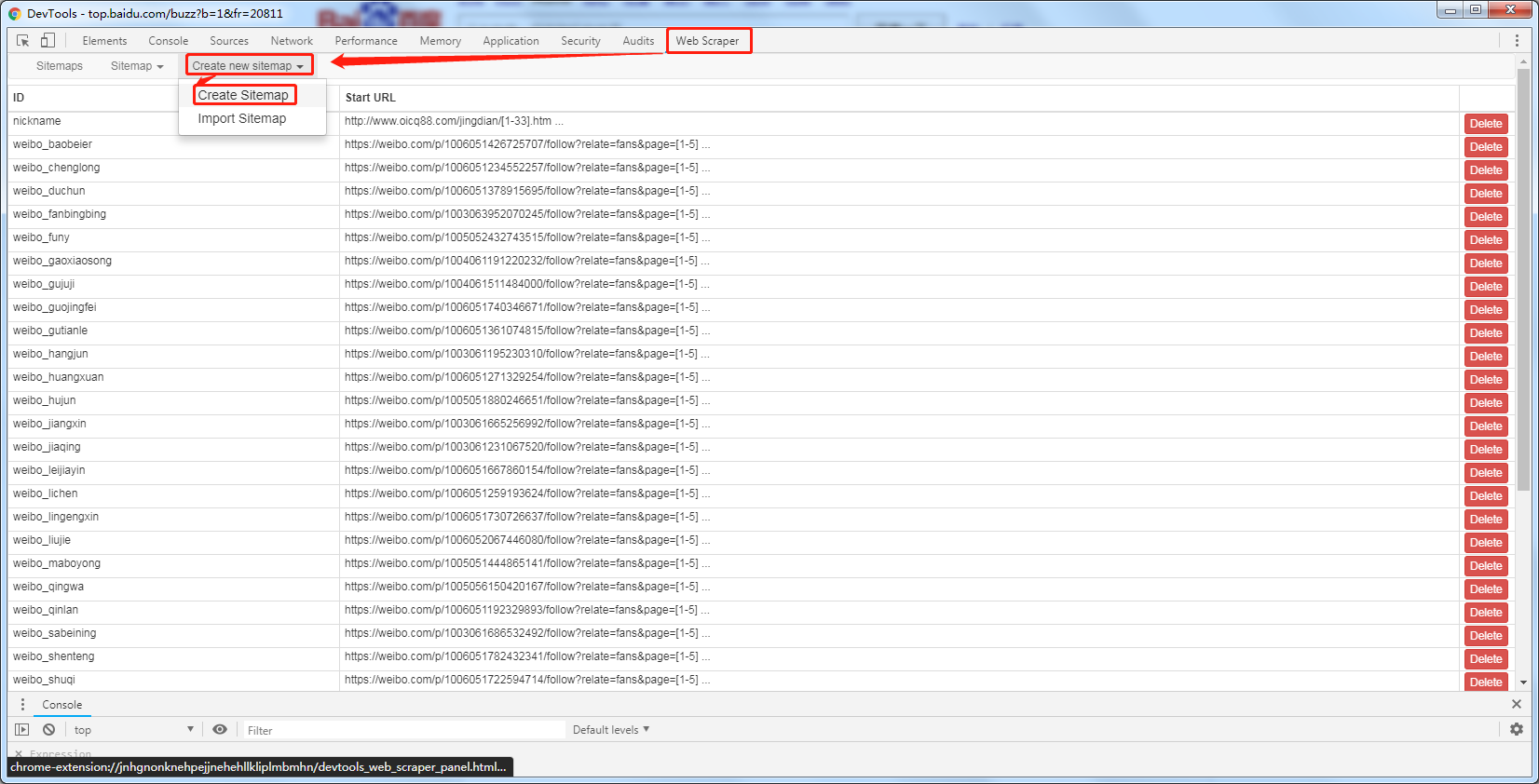
进入 创建站点页面 站点名称和爬取地址点击创建站点即可
如果要爬取分页数据那就将参数写成范围的如:
想要爬取微博某博主关注列表的1-5页的粉丝信息,通过url的跳转发现微博关注列表和<number>数字有关
https://weibo.com/p/1003061752021340/follow?relate=fans&page=<number>
所以只要把<number>写成一个范围的即可
https://weibo.com/p/1006051234552257/follow?relate=fans&page=[1-5]
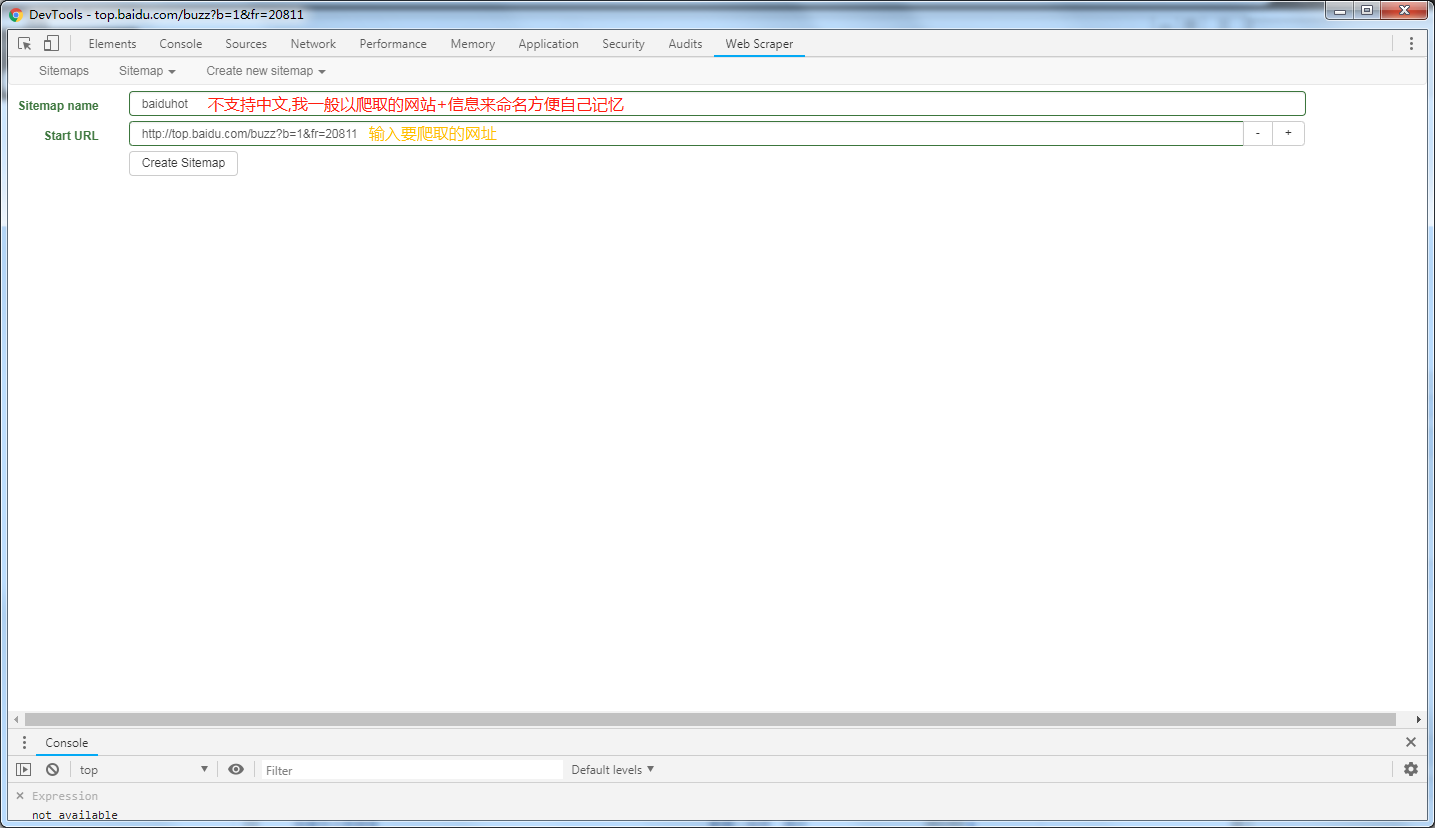
爬取数据
首先创建一个element的select
创建element信息
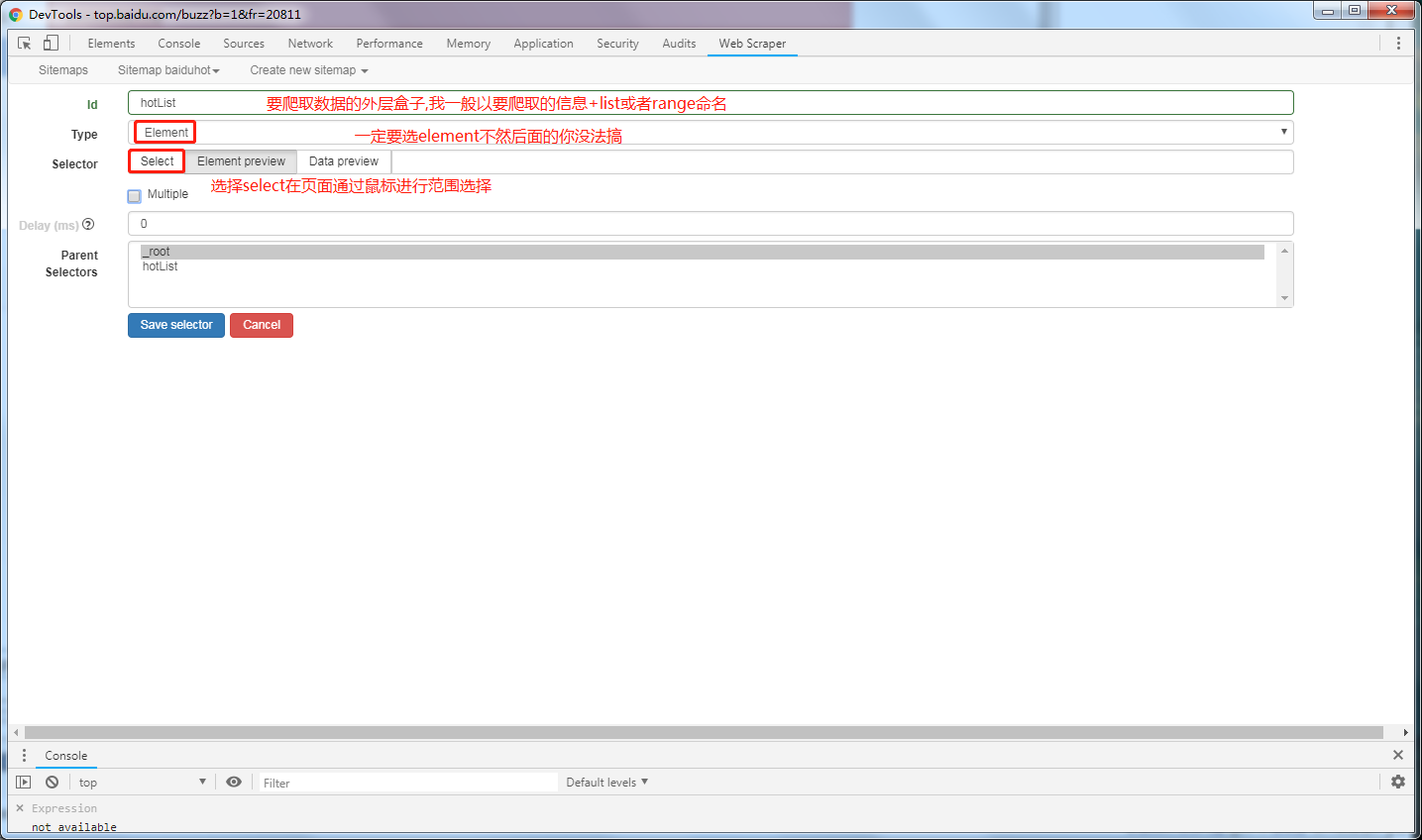
select选择最外层的盒子,确认无误后点击Done selecting!
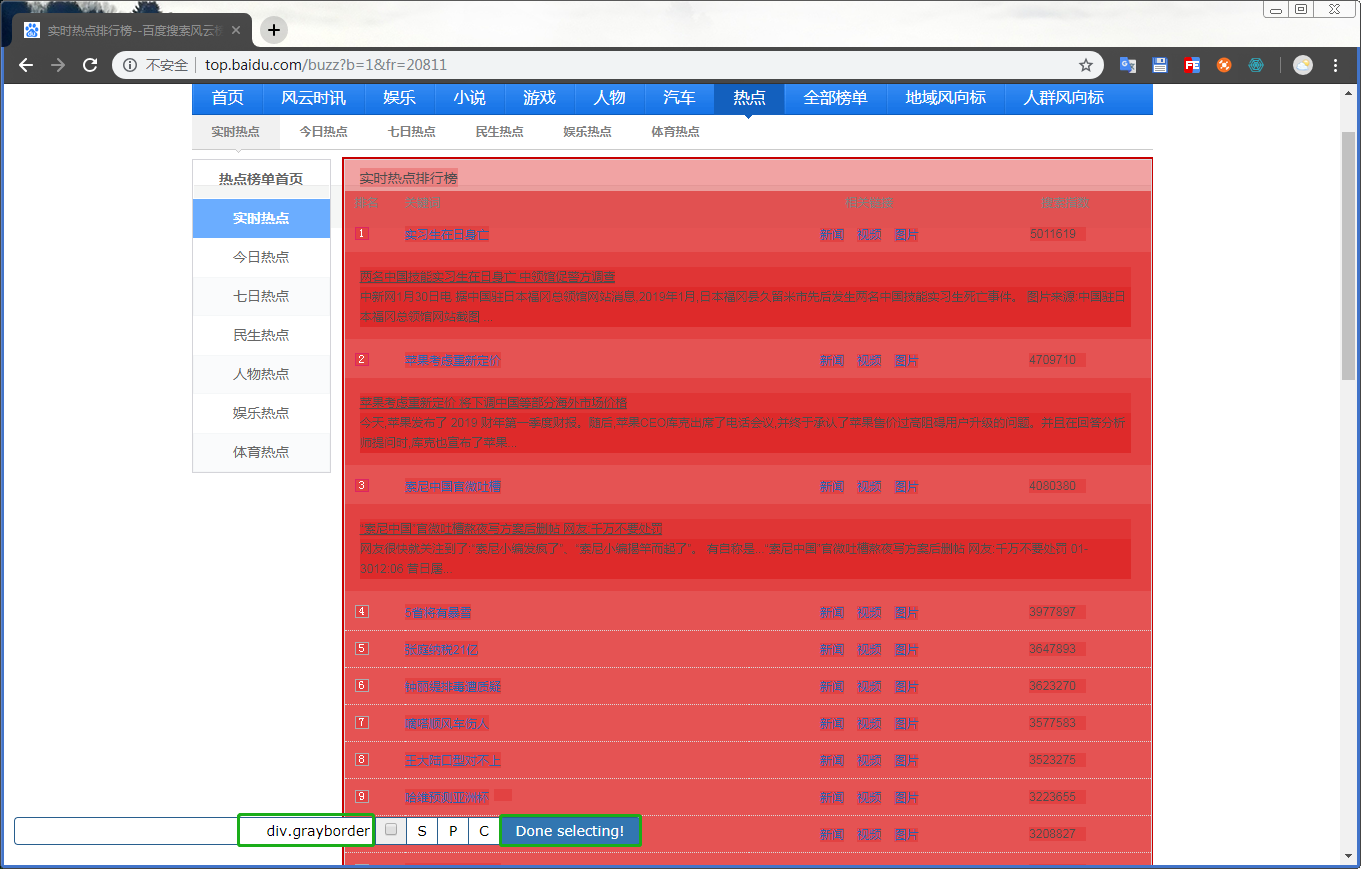
然后回到web scraper控制台,查看信息无误后勾选multiple确认无误后,创建element的select

爬取自己想要的信息,点击进入hotList里面,然后继续创建select选择
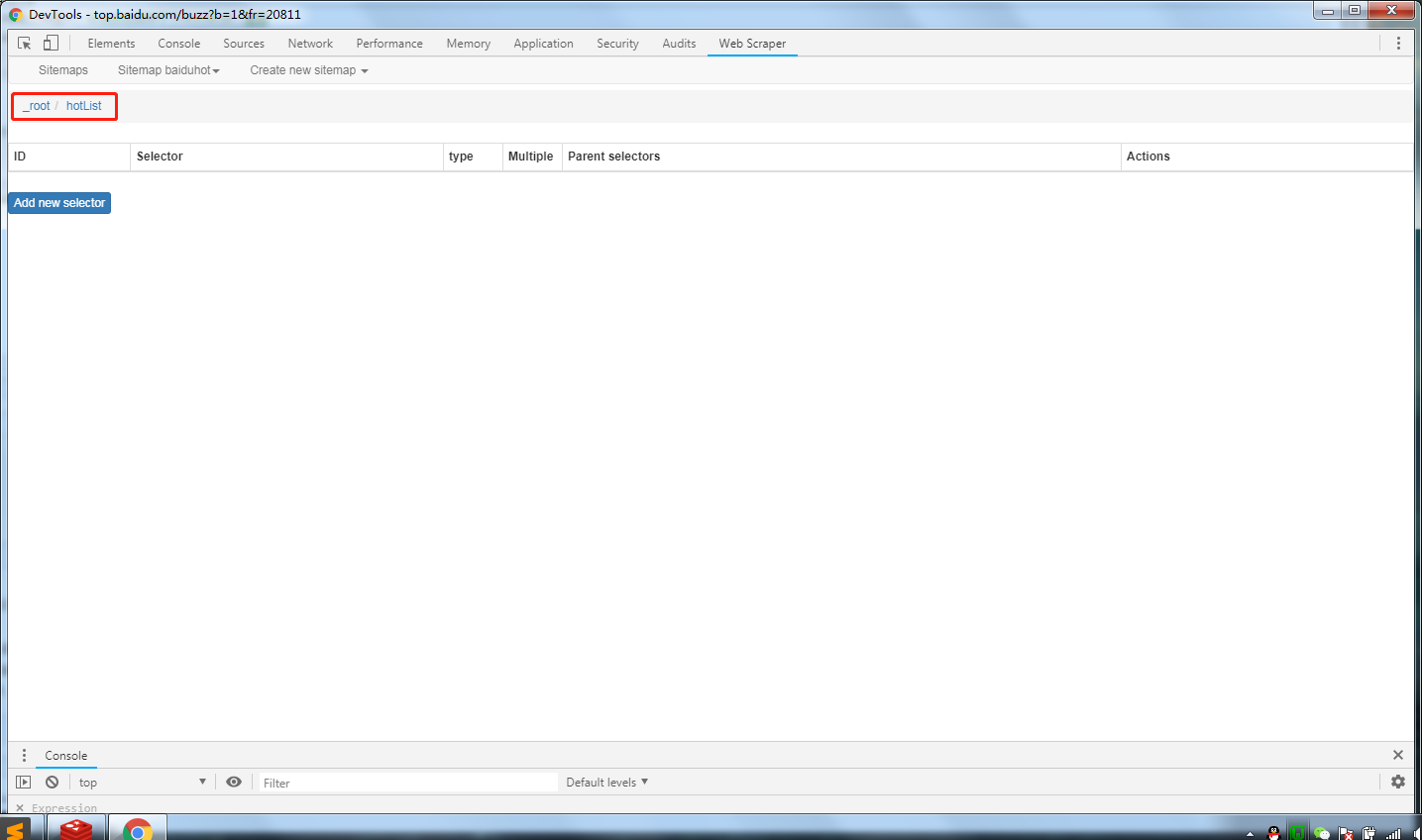
填写具体的select信息,并继续通过select来进行选择需要的数据
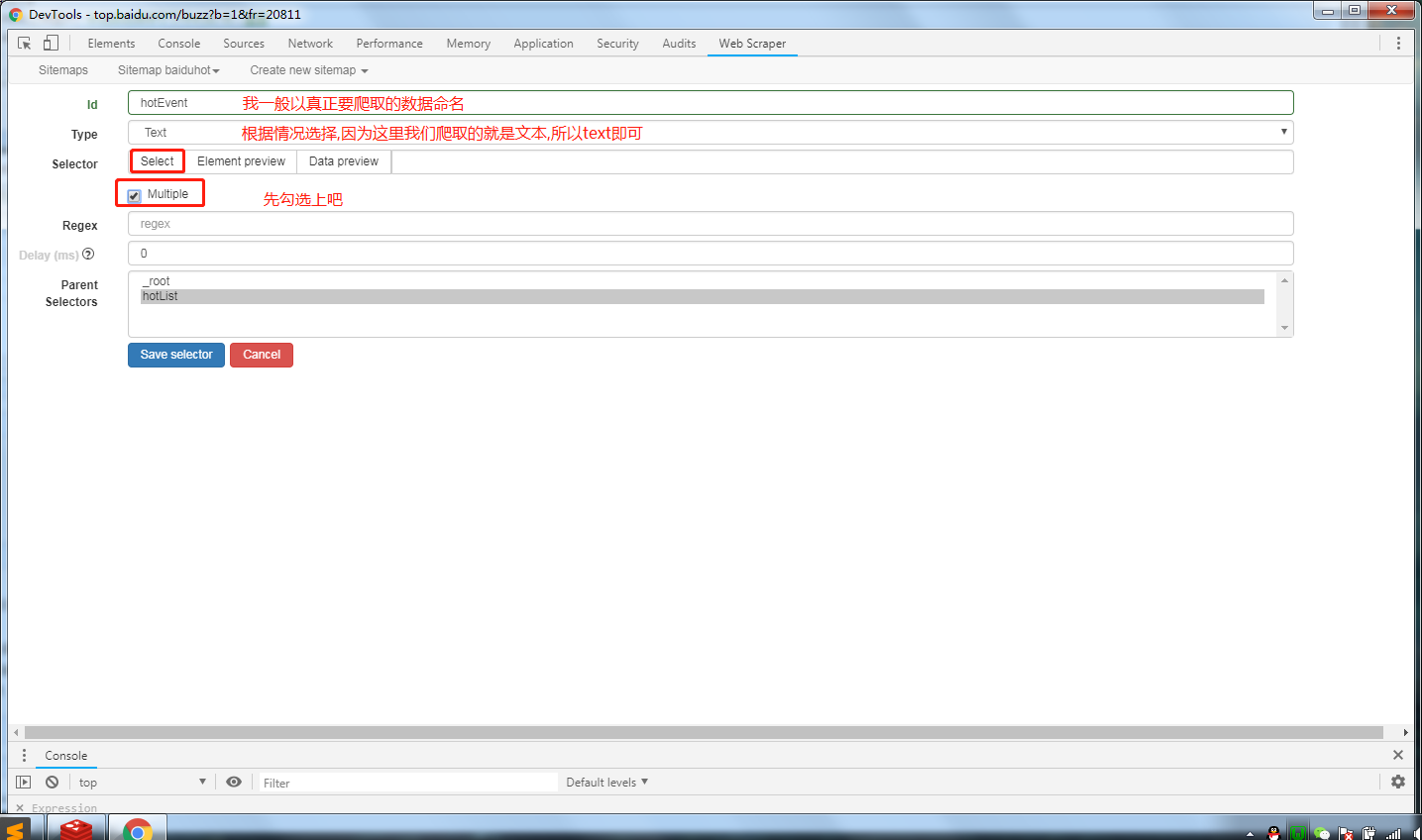
这时候页面的范围会变为黄色,鼠标移动到自己需要的信息处会有绿框将信息圈出来
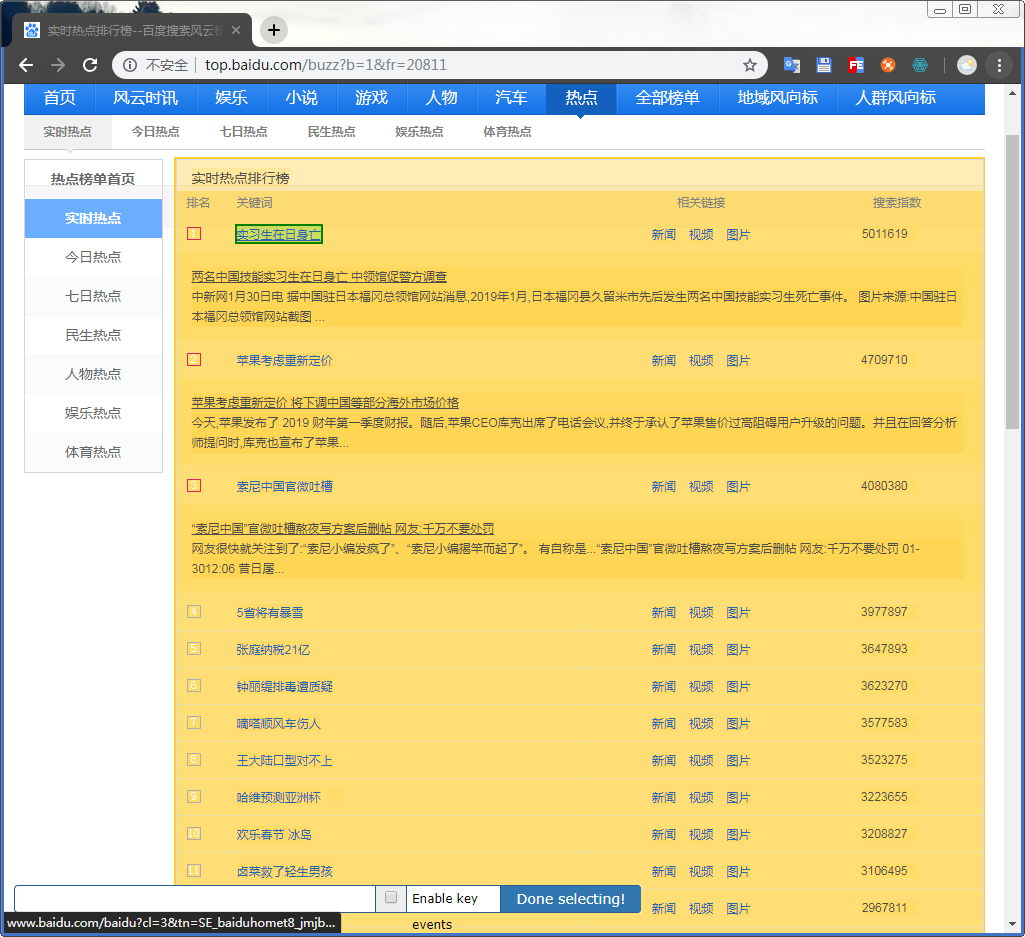
点击确认后会变为红色的,再次选择相同的会自动识别将同样标签下的包围起来,确认是自己需要的信息后直接Done selecting!
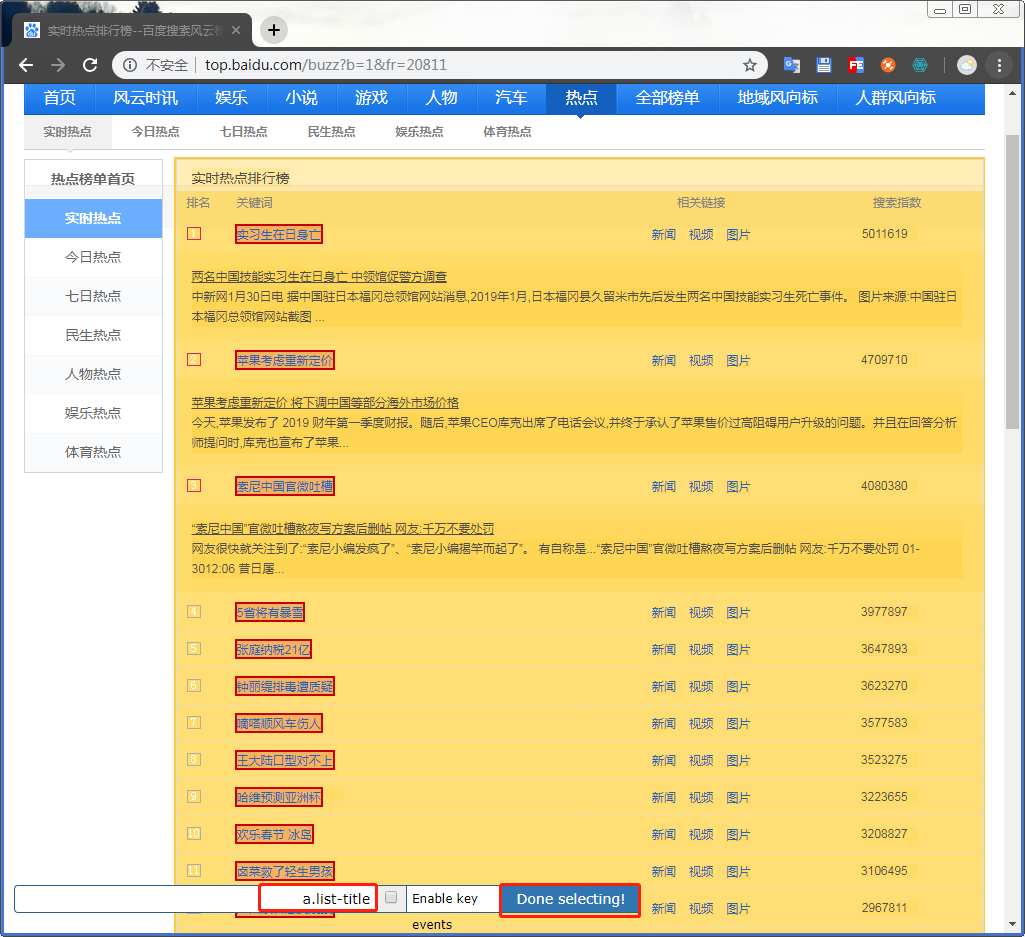
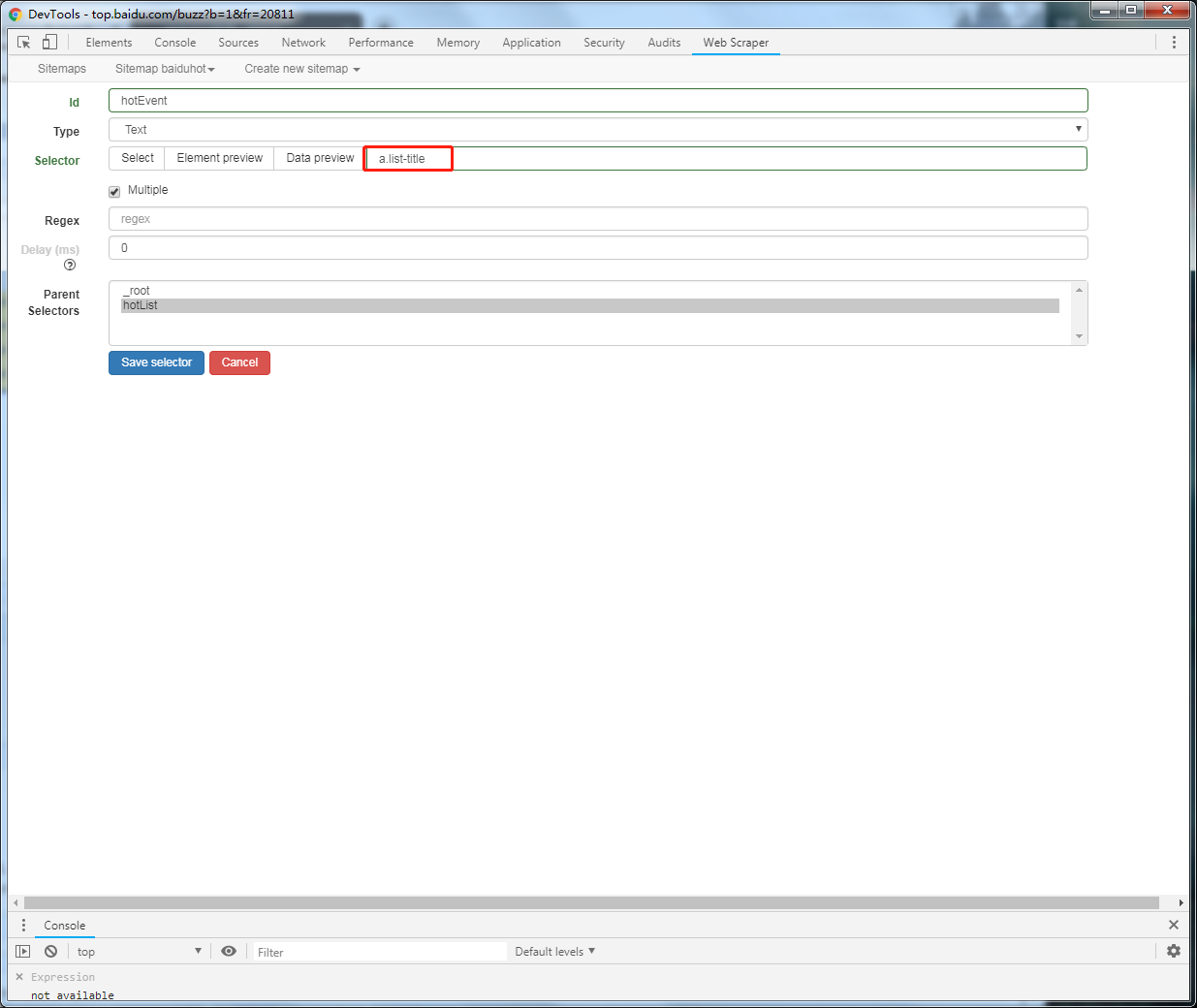
再次转到web scraper的控制台后,确认无误即可保存
运行脚本,进行采集
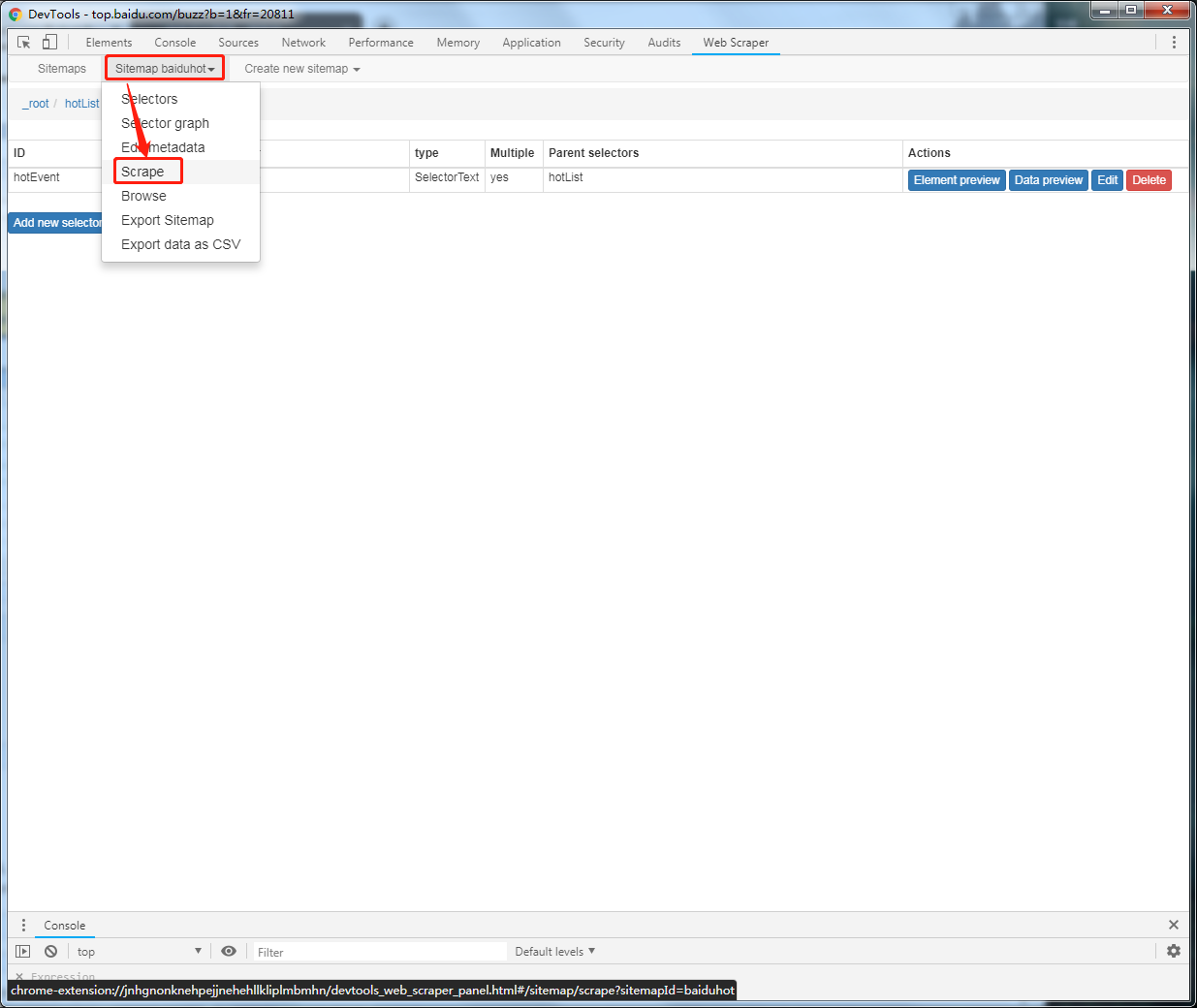
默认配置即可,想修改也可以的,我一般直接默认的

点击开始脚本后,会将采集的页面弹出,采集完成右下角会出现提示,采集过程中点击refresh可以查看采集的数据
采集的数据
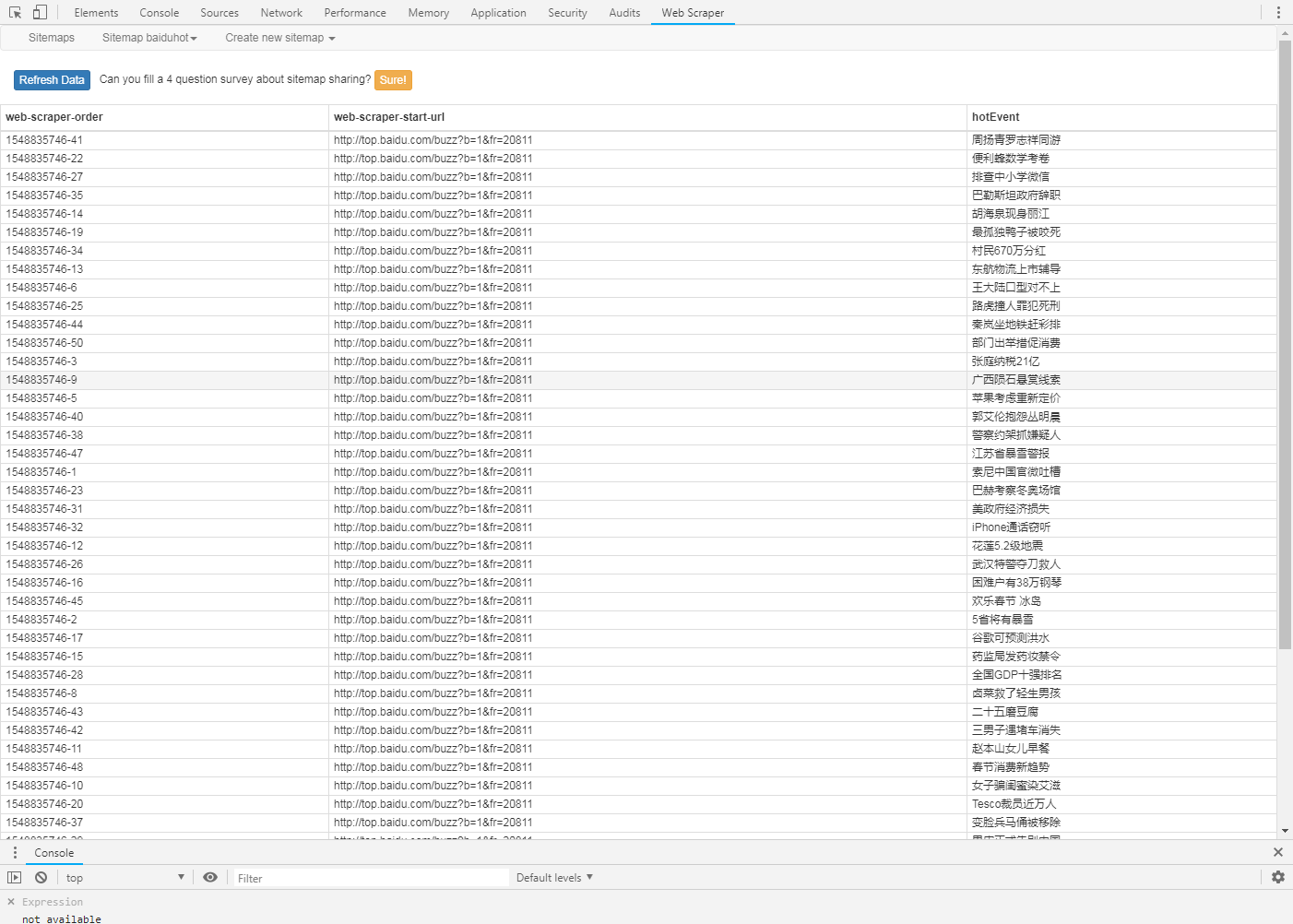
导出数据
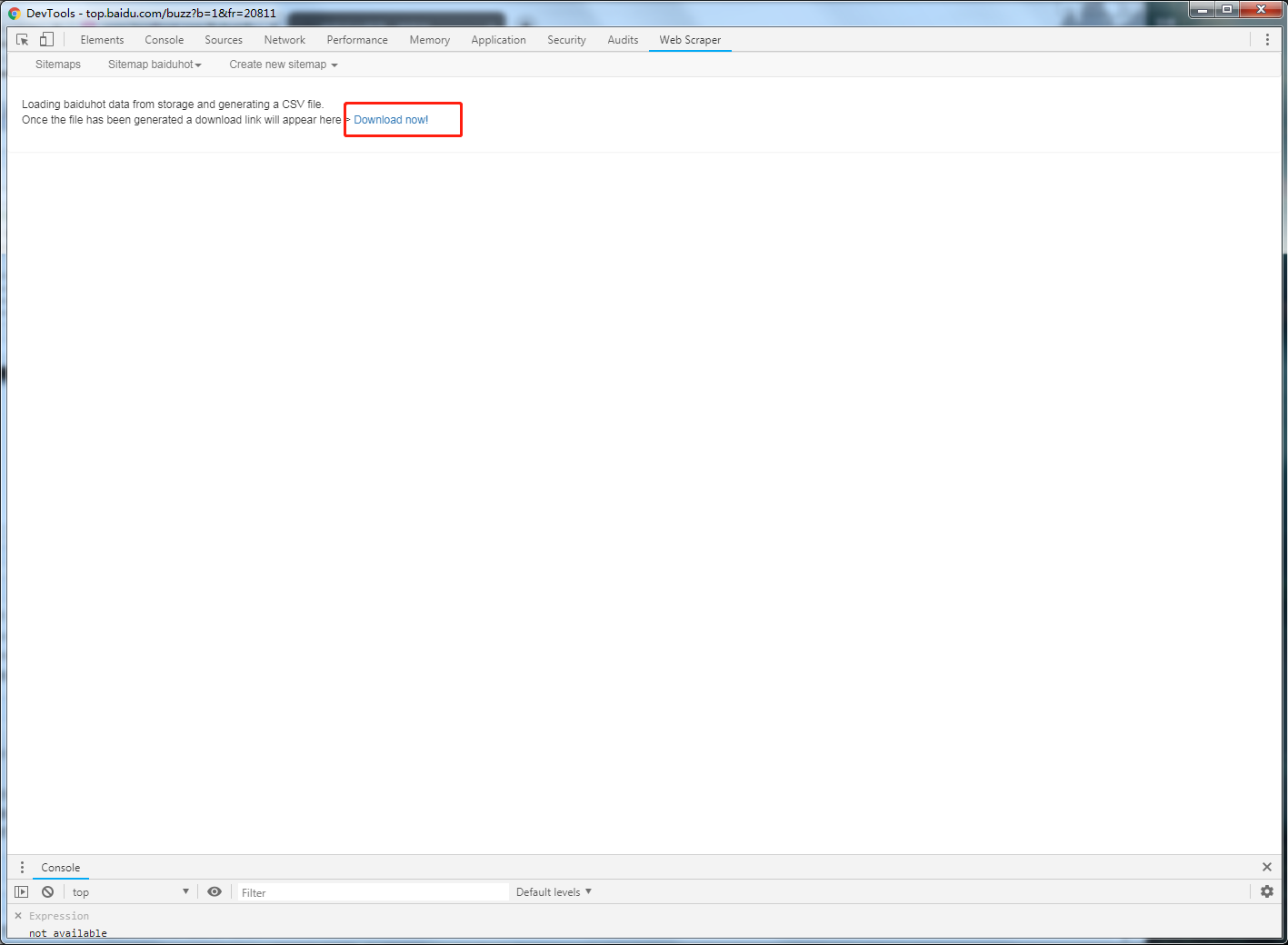
确认数据没有错误,是自己需要的即可,进行下载,以csv格式导出

点击Downolad now!即可下载
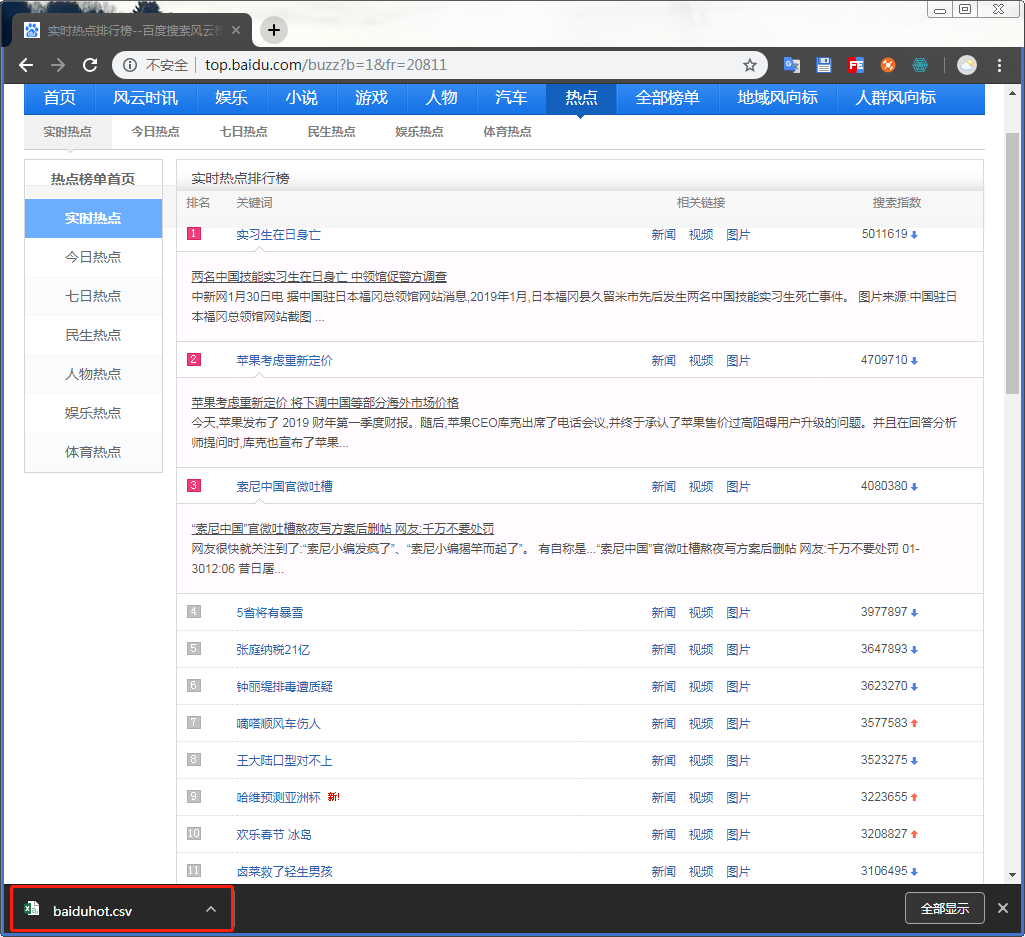
数据内容

到这里使用web scraper进行数据采集就结束了
web scraper——简单的爬取数据【二】的更多相关文章
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- scrapy爬取数据的基本流程及url地址拼接
说明:初学者,整理后方便能及时完善,冗余之处请多提建议,感谢! 了解内容: Scrapy :抓取数据的爬虫框架 异步与非阻塞的区别 异步:指的是整个过程,中间如果是非阻塞的,那就是异步 ...
- Python分页爬取数据的分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 向右奔跑 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 借助Chrome和插件爬取数据
工具 Chrome浏览器 TamperMonkey ReRes Chrome浏览器 chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程 ...
- 使用webmagic爬虫对百度百科进行简单的爬取
分析要爬取的网页源码: 1.打开要分析的网页,查看源代码,找到要爬取的内容: (选择网页里的一部分右击审查元素也行) 2.导入jar包,这个就直接去网上下吧: 3.写爬虫: package com.g ...
随机推荐
- A2D JS框架 - loadScript实现
其实这个功能比较小,本着自己造轮子的优良传统....就自己造一个好了 <head> <title></title> <script src="A2D ...
- 从CompletableFuture到异步编程设计
从CompletableFuture到异步编程设计,笔者就分为2部分来分享CompletableFuture异步编程设计,前半部分总结下CompletableFuture使用实践,后半部分分享下Com ...
- hibernate坑边闲话2
threw exception [Request processing failed; nested exception is org.springframework.orm.hibernate5.H ...
- 容器化 — 基于Docker技术容器云
导读:本文介绍了基于Docker技术的企业级应用容器平台,从云的定义.云服务分类,到用友云PaaS基础平台.平台总体架构.架构预览.部署架构.平台核心价值和核心竞争力,阐述PaaS基础平台成为广大传统 ...
- spring datasource jdbc 密码 加解密
spring datasource 密码加密后运行时解密的解决办法 - 一号门-程序员的工作,程序员的生活(java,python,delphi实战)http://www.yihaomen.com/a ...
- css横线中间放图片或者文字
效果图: 先贴代码 HTML: <div class="forshow middle"> <div class="flex"></ ...
- java类库
Java的应用程序接口(API)以包的形式来组织,每个包提供大量的相关类.接口和异常处理类,这些包的集合就是Java的类库. Java类库可以分为两种 包名以java开始的包是Java核心包(Java ...
- Azure系列2.1.4 —— BlobInputStream
(小弟自学Azure,文中有不正确之处,请路过各位大神指正.) 网上azure的资料较少,尤其是API,全是英文的,中文资料更是少之又少.这次由于公司项目需要使用Azure,所以对Azure的一些学习 ...
- 1065. 我的日程安排表 I
描述 实现MyCalendar类来存储您的活动. 如果新添加的活动没有重复,则可以添加. 你的类将有方法book(int start,int end). 这代表左闭右开的间隔[start,end)有了 ...
- zookeeper的安装和启动教程
zookeeper的安装和启动 zookeeper安装包所在目录: 上传文件到虚拟机.现在本地新建一个目录setup,将zookeeper压缩包复制进去. ALT+P打开一个标签,操作如下put命令. ...