python---Scrapy模块的使用(一)
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
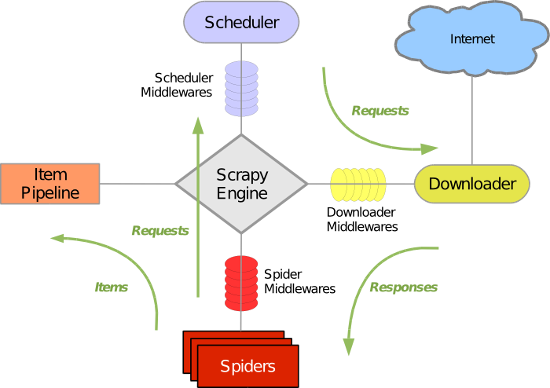
各个组件:
Scrapy引擎:
是框架核心,用来处理调度整个系统的数据流处理
Scheduler调度器:
用来接收引擎发送过来的请求,压入队列中,并在引擎再次请求时返回,就是在我们所要爬取的url全部放入一个优先队列中,由它来决定下一个处理的url是什么,同时他会自动将重复的url去除
注意:我们在创建一个项目时,在spider中会存在一个start_urls = ['http://dig.chouti.com/'],他将是我们的初始url,会在项目启动后被引擎放入调度器中开始处理
Downloader下载器:
用于下载网页内容,并将网页内容返回给蜘蛛(下载器是基于twisted实现)
Item解析器:
设置数据存储模板,用于结构化数据。为下一步的持久化数据做处理,类似于Django中的models,设置存储字段等数据,解析数据
Pipeline项目管道
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
Downloader Middlewares下载器中间件
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
Spider Middlewares爬虫中间件
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
Scheduler Middewares调度中间件
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程
1.引擎从调度器中取出一个连接URL,用于接下来的抓取
2.引擎将URL封装为一个请求Request传给下载器
3.下载器将资源下载,封装为应答包Response
4.爬虫解析Response
5.解析出实体Item,将实体通过管道解析持久化操作
6.若是解析出URL,将其放入调度器中等待抓取
注意:第一步之前,是先去爬虫start_url中获取初始网址,进行操作
项目创建的基本命令
1.创建项目
scrapy startproject 项目名
scrapy startproject scrapyPro
2.进入项目,创建爬虫
cd 项目名
scrapy genspider 项目列表名 初始url(后面可以修改)
cd scrapyPro
scrapy genspider chouti chouti.com
3.展示爬虫应用列表
scrapy list
chouti
4.运行爬虫应用
scrapy crawl 爬虫应用名称
scrapy crawl chouti --nolog #--nolog不打印日志
项目结构
project_name/
scrapy.cfg #项目的主配置文件
project_name/
__init__.py
items.py #设置数据存储模板,用于结构化数据:类似于Django中models
pipelines.py #数据处理行为:如数据的持久化
settings.py #配置文件:递归层数,并发数等
spiders/ #爬虫目录,我们可以创建多个爬虫在此
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py
简单实例应用(获取抽屉的新闻标题和URL,并将其保存到文件,实现持久化操作)
chouti爬虫的编写
import scrapy,hashlib
from scrapy.selector import Selector,HtmlXPathSelector
from scrapy.http import Request
import sys,io
from ..items import ChoutiItem sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #设置原因:在windows下,我们需要在cmd命令行下启动项目,而cmd默认是gbk编码,而py3是utf-8为了保持编码一致,避免乱码,我们需要修改 class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com'] #允许采集的域名
start_urls = ['http://dig.chouti.com/'] #初始url def parse(self, response): #response.url/text/body/meta含有访问深度
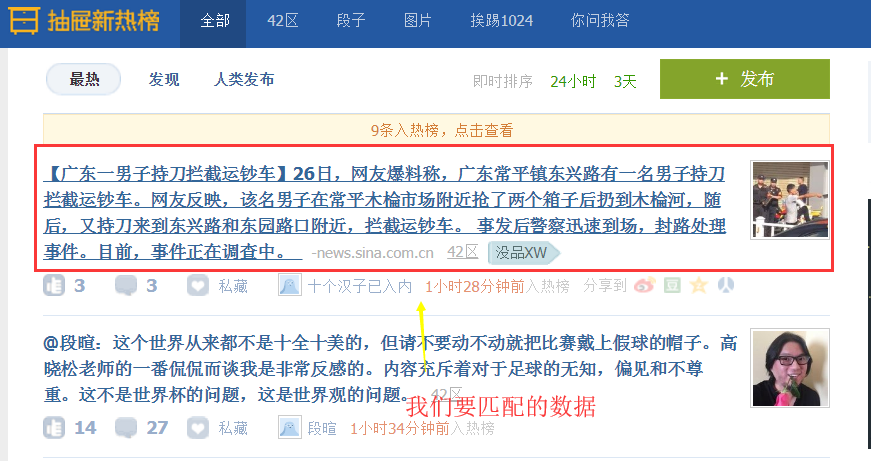
item_objs = Selector(response=response).xpath("//div[@class='item']//a[@class='show-content color-chag']") #注意这里过滤class不能只选用一个,必须将全部的class加上
for item in item_objs:
title = item.xpath("text()").extract_first().strip()
href = item.xpath("@href").extract_first()
#想要将数据持久化,必须在Item中设置数据字段
item_obj = ChoutiItem(title=title,href=href)
# 将item对象传递给pipeline
yield item_obj
items.py文件的编写:设置数据存储模板,之后才能够实现持久化处理
# -*- coding: utf- -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass class ChoutiItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
href = scrapy.Field()
pipeline.py文件编写:实现数据持久化操作
# -*- coding: utf- -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class ScrapyproPipeline(object):
def process_item(self, item, spider): #写入文件中去
tpl = "%s\n%s\n\n"%(item['href'],item['title'])
with open("news.josn",'a',encoding="utf-8") as fp: #注意文件编码
fp.write(tpl)
注意:我们要使使用Item解析实体和pipeline持久化关联,需要修改setting配置文件
ITEM_PIPELINES = {
'scrapyPro.pipelines.ScrapyproPipeline': , #后面300代表优先级
}
补充:Selector的操作
Selector(response=response).xpath('//a') #解析当前响应response下的所有子孙a标签
Selector(response=response).xpath('//a[2]') #获取所有的a标签下的第二个标签
Selector(response=response).xpath('//a[@id="i1"]') #获取属性id为il的标签 @后面跟属性
Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]') #多个标签的连续筛选
Selector(response=response).xpath('//a[starts-with(@href, "link")]') #属性以指定的字符串开头
Selector(response=response).xpath('//a[contains(@href, "link")]') #属性中包含有指定字符串
Selector(response=response).xpath('//a[re:test(@id, "i\d+")]') #正则匹配数据
Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()') #获取匹配标签下的文本数据
Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href') #获取匹配标签的属性值
上面获取的都是解析对象,要想获取具体数据(字符串),我们需要使用
Selector(response=response).xpath('/html/body/ul/li/a/@href').extract() #提取所有的,是个列表
Selector(response=response).xpath('//body/ul/li/a/@href').extract_first() #提取第一个
注意:'//'代表子孙标签,'/'代表子标签,另外'./'代表当前标签下寻找
简单实例应用:获取抽屉页码
import scrapy,hashlib
from scrapy.selector import Selector,HtmlXPathSelector
from scrapy.http import Request class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['http://dig.chouti.com/']
visited_urls = set() #用于存放我们获取的url的md5值,而且是集合去重 def md5(self,url): #将url转md5
ha_obj = hashlib.md5()
ha_obj.update(bytes(url,encoding="utf-8"))
key = ha_obj.hexdigest()
return key def parse(self, response):
page_objs = Selector(response=response).xpath("//div[@id='dig_lcpage']//a[@class='ct_pagepa']") #解析实体
for page in page_objs:
href = page.xpath("@href").extract_first()
ha_href = self.md5(href)
if ha_href in self.visited_urls:
pass
else:
self.visited_urls.add(ha_href) #将获取的url添加到集合
new_url = "https://dig.chouti.com%s"%href
yield Request(url=new_url,callback=self.parse) #请求新的url,获取下面的url 对于阻塞操作使用yield切换,实现异步
注意:默认是获取所有的页面100多页,我们可以在setting文件设置解析深度
DEPTH_LIMIT = 1 #深度为1,表示在当前页面向下再次解析一次


这是第二次,只会解析到14页
简单实例应用:获取校花网的图片和姓名,按照姓名进行持久化文件归类
xiaohua.py
# -*- coding: utf- -*-
import scrapy
import hashlib
from scrapy.http.request import Request
from scrapy.selector import Selector,HtmlXPathSelector
import scrapy.http.response.html
from ..items import XiaohuaItem class XiaohuaSpider(scrapy.Spider):
name = 'xiaohua'
allowed_domains = ['xiaohua.com']
start_urls = ['http://www.xiaohuar.com/']
visited_url = set()
visited_url_img = {}
visited_url_title = {} def md5(self,url):
hash_obj = hashlib.md5()
hash_obj.update(bytes(url,encoding="utf-8"))
return hash_obj.hexdigest() def parse(self, response):
#获取首页中所有的人物的下一级url,过滤掉校草
xh_a = Selector(response=response).xpath("//ul[@class='twoline']/li")
for xh in xh_a:
a_url = xh.xpath("./a[@class='xhpic']/@href").extract_first()
a_title = xh.xpath("./a/span/text()").extract_first()
if a_title.find("校草") != -:
continue
if not a_url.startswith("http"):
a_url = "http://www.xiaohuar.com%s" % a_url
ha_url = self.md5(a_url)
if ha_url in self.visited_url:
pass
else:
self.visited_url.add(ha_url)
self.visited_url_title[ha_url]=a_title yield scrapy.Request(url=a_url,callback=self.parse,dont_filter=True) #下面是所有人物下一级url中去查找所有照片,注意:部分小照片和大照片的区别在于前面多了small,大照片只取前32位即可
#/d/file//small062adbed4692d28b77a45e269d8f19031512203361.jpg 小照片
#/d/file// 062adbed4692d28b77a45e269d8f1903.jpg 大照片 xh_img = Selector(response=response).xpath("//div[@class='post_entry']")
xh_img_a = xh_img.xpath("./ul//img/@src") if len(xh_img) == :
xh_img = Selector(response=response).xpath("//div[@class='photo-Middle']/div")
if len(xh_img) != :
xh_img = xh_img[]
else:
xh_img = Selector(response=response).xpath("//div[@class='photo-m']/div")[]
xh_img_a = xh_img.xpath("./table//img/@src") # 上面找到标签,下面开始对标签进行循环,获取所有照片url for xh_img_item in xh_img_a:
xh_img_url = xh_img_item.extract() if xh_img_url.find("small"):
tmp_list = xh_img_url.rsplit("/",)
tmp_name_list = tmp_list[].replace("small","").split(".")
xh_img_url = "/".join([tmp_list[],".".join([tmp_name_list[][:],tmp_name_list[]])])
if not xh_img_url.startswith("http"):
xh_img_url = "http://www.xiaohuar.com%s" % xh_img_url
#将所有照片加入字典 url:名字
self.visited_url_img[xh_img_url] = self.visited_url_title[self.md5(response.url)] #若是收集完成,那么两者的长度是一致的,开始进行持久化
if len(set(self.visited_url_img.values())) == len(self.visited_url) and len(self.visited_url) != :
for xh_url in self.visited_url_img.items():
item_obj = XiaohuaItem(title=xh_url[],img_url=xh_url[])
yield item_obj
items.py
import scrapy class XiaohuaItem(scrapy.Item):
title = scrapy.Field()
img_url = scrapy.Field()
pipelines.py
import requests,os
class XiaohuaPipeline(object):
def process_item(self, item, spider):
'''
title
img_url
'''
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'upload',item['title'])
if not os.path.isdir(file_path):
os.makedirs(file_path) response = requests.get(item['img_url'],stream=False)
with open(os.path.join(file_path,item['img_url'].rsplit("/",)[]),"wb") as fp:
fp.write(response.content) return item
settings.py
ITEM_PIPELINES = {
'scrapyPro.pipelines.ScrapyproPipeline': ,
'scrapyPro.pipelines.XiaohuaPipeline': ,
}
补充:request的回调函数不执行
原因:可能是我在设置allowed_domains允许域名中所设置的域名不是我们所爬取的网站域名
allowed_domains = ['xiaohua.com'] #域名不对,是xiaohuar.com
start_urls = ['http://www.xiaohuar.com/']
设置allowed_domains的原因:
因为在网站中可能有外联,我们只是需要去访问该网站,而不是他的外联网站,所以设置allowed_domains是必须的,可以过滤掉外联的网站,要是希望获取外联网站,我们在该列表中添加上即可。
上面出错原因:
我们所爬取的网站时xiaohuar.com,而设置的域名是xiaohua.com所以爬取失败,在request中请求被拒绝
解决方法:(两者)
1.修改allowed_domains(推荐)
allowed_domains = ['xiaohuar.com']
2.在request中设置dont_filter(不对url进行过滤)
yield scrapy.Request(url=a_url,callback=self.parse,dont_filter=True)
推荐使用第一种:
我们可以在自定义类BaseDupeFilter(用于过滤url)中设置去重,数据收集等操作,使用dont_filter可能会有所影响
python---Scrapy模块的使用(一)的更多相关文章
- Python.Scrapy.14-scrapy-source-code-analysis-part-4
Scrapy 源代码分析系列-4 scrapy.commands 子包 子包scrapy.commands定义了在命令scrapy中使用的子命令(subcommand): bench, check, ...
- Python.Scrapy.11-scrapy-source-code-analysis-part-1
Scrapy 源代码分析系列-1 spider, spidermanager, crawler, cmdline, command 分析的源代码版本是0.24.6, url: https://gith ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- 二 web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip install Scrapy 手动源码安装,比较麻烦要自己手动安 ...
- scrapy模块之分页处理,post请求,cookies处理,请求传参
一.scrapy分页处理 1.分页处理 如上篇博客,初步使用了scrapy框架了,但是只能爬取一页,或者手动的把要爬取的网址手动添加到start_url中,太麻烦接下来介绍该如何去处理分页,手动发起分 ...
- 爬虫scrapy模块
首先下载scrapy模块 这里有惊喜 https://www.cnblogs.com/bobo-zhang/p/10068997.html 创建一个scrapy文件 首先在终端找到一个文件夹 输入 s ...
- Python Scrapy 实战
Python Scrapy 什么是爬虫? 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人.其目的一般为编纂网络索引. Python 爬虫 ...
- Scrapy模块使用出错,出现builtins.ImportError: DLL load failed: 找不到指定的程序
问题描述:初次学习scrapy,使用scrapy官方文档创建爬虫项目出错, 出现builtins.ImportError: DLL load failed: 找不到指定的程序, ImportError ...
随机推荐
- Fiber Network ZOJ 1967(Floyd+二进制状态压缩)
Description Several startup companies have decided to build a better Internet, called the "Fibe ...
- 从入门到不放弃——OO第一次作业总结
写在最前面: 我是一个这学期之前从未接触过java的小白,对面向对象的理解可能也只是停留在大一python讲过几节课的面向对象.幸运的是,可能由于前三次作业难度还是较低,并未给我造成太大的困难,接下来 ...
- 领悟JavaScript面向对象
JavaScript 是面向对象的.但是不少人对这一点理解得并不全面. 在 JavaScript 中,对象分为两种.一种可以称为“普通对象”,就是我们所普遍理解的那些:数字.日期.用户自定义的对象(如 ...
- Spring配置声明
<... xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="htt ...
- hdu-题目1421:搬寝室
http://acm.hdu.edu.cn/showproblem.php?pid=1421 搬寝室 Time Limit: 2000/1000 MS (Java/Others) Memory ...
- python判断字符串是否包含子字符串
python的string对象没有contains方法,不可以使用string.contains的方法判断是否包含子字符串,但是python有更简单的方法来替换contains函数 python的st ...
- 第123天:移动web开发中的常见问题
一.函数库 underscoreJS _.template: <ol class="carousel-indicators"> <!--渲染的HTML字符串--& ...
- 第87天:HTML5中新选择器querySelector的使用
一.HTML5新选择器 1.document.querySelector("selector");selector:根据CSS选择器返回第一个匹配到的元素,如果没有匹配到,则返回n ...
- bzoj1318[spoj 744] Longest Permutation
题意 给出一个长度为n的,所有元素大小在[1,n]的整数数列,要求选出一个尽量长的区间使得区间内所有元素组成一个1到区间长度k的排列,输出k的最大值 n<=1e5 分析 不会做,好菜啊.jpg ...
- Collection接口框架
1. Collection接口 其主要的UML类图: Collection接口继承自Iterable接口.Iterable接口中定义了Iterable方法,该方法会返回一个迭代器,用于遍历合集中的元素 ...