spark累加器、广播变量
一言以蔽之:
累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成
广播变量是只读变量 正常的话我们在driver定义一个变量 需要序列化 才能在excutor端使用 而且是每个task都需要传输一次 这样如果我们定义的对象很大的话 就会产生大量的IO 如果你把这个大对象定义成广播变量的话 我们只需要每个excutor发送一份就可以 如果task需要时 只需要从excutor拉取就可以了。可以减轻集群driver和executor间的通信压力,节省集群资源。
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator),广播变量常用来高效分发较大的对象,而累加器用来对信息进行聚合。
共享变量出现的原因:通常在向 Spark 传递函数时,比如使用map或reduce传条件或变量时,在driver端定义变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值driver端的对应变量并不会随之更新。Spark 的两个共享变量,广播变量与累加器分别为变量提供广播与聚合功能,突破了变量不能共享的限制。

2、广播变量的使用原则
不能将RDD用做变量广播出去,RDD是不存储数据的,可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义,Executor端只能使用。
广播变量的值只能在Driver端修改,在Executor端不能修改
3、广播变量使用方法
(1) 通过SparkContext.Broadcast[T] 创建一个变量v,并进行广播,广播变量以序列化形式缓存。
如scala方式:val broadCast = sc.broadcast(T) 对T进行广播,T可以是任何能被序列化的类型
(2) 通过 broadCast.value 属性访问该对象的值,而不能直接访问T
(3) 当要更新广播变量时候,通过broadCast.unpersist()方法清除广播变量,之后可重新广播
4、广播变量使用场景
日常工作中对来访url、ip等过滤业务,就可以使用广播变量
112.168.102.71
19.18.172.75
12.16.72.20
100.20.13.4
8.8.8.8
102.168.17.205
202.102.12.74
114.114.114.114
object FilterIP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("broadcast");
conf.setMaster("local");
val sc = new SparkContext(conf);
val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取
//使用广播变量时,driver第一次向executor发送task时候,发送blackList,缓存到blockmanager,以后不会再发送
val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取
//在driver端进行广播blackList
val broadCast = sc.broadcast(blackList);
//在executor端用broadCast.value获取blackList的值
val filterRdd =lineRdd.filter(ip =>{ !broadCast.value.contains(ip)})
filterRdd.foreach(ip =>{
println(ip)
//处理其他业务
})
}
}
112.168.102.71
19.18.172.75
12.16.72.20
100.20.13.4
102.168.17.205
202.102.12.74
使用spark广播变量时候,在输出结果是看不到有什么变化,但这种变化是内在的,可以减轻集群driver和executor间的通信压力,节省集群资源。
Spark累加器
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object FilterIP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("broadcast");
conf.setMaster("local"); val sc = new SparkContext(conf); val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取
var sum = ;
val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取
//在driver端进行广播blackList
val broadCast = sc.broadcast(blackList);
val filterRdd =lineRdd.filter(ip =>{ broadCast.value.contains(ip)})
filterRdd.foreach(ip =>{
sum+=;
println("executor sum="+sum)
})
//打印出非法ip的访问数量
println("driver sum="+sum)
}
}
输出:
executor sum=
executor sum= driver sum=
可以看到在driver端sum仍然是0,这并不是我们想要的结果。原来sum在各个节点的executor中累加的同时,driver端的sum最后并不会更新,导致sum最终仍然是0。
spark的累加器就是解决此类问题而出现的,其提供了聚合功能,把各个节点上的executor对变量的累加结果聚合到driver端, 最终统计出我们想要的结果。spark的累加器充分彰显的分布式计算的特性。
2、累加器使用原则
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
3、累加器的使用方法
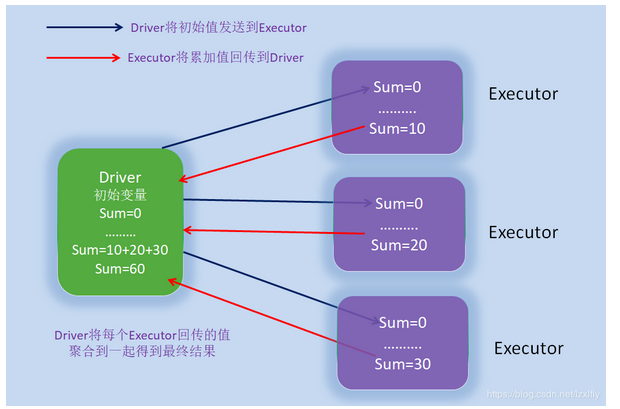
(1) 通过sparkContext.longAccumulator()或sparkContext.doubleAccumulator()来累积long或double类型的值来创建数字累加器
如scala方式:var accumulator=sc.longAccumulator("accumulator");
(2) 在executor端通过accumulator.add(1)进行累加后并回传到driver
4、累加器的使用场景
如对非法来访Ip的统计
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object FilterIP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("broadcast");
conf.setMaster("local"); val sc = new SparkContext(conf); val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取
//spark2.0.0中sc.accumulator(0)不被推荐,用如下方式初始值,默认0
val accumulator=sc.longAccumulator("accumulator"); val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取
//在driver端进行广播blackList
val broadCast = sc.broadcast(blackList);
val filterRdd =lineRdd.filter(ip =>{ broadCast.value.contains(ip)})
filterRdd.foreach(ip =>{
accumulator.add();
})
//打印出非法ip的访问数量
println("driver sum="+accumulator.value)
}
}
输出:
driver sum=

————————————————
版权声明:本文为CSDN博主「LiryZlian」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lzxlfly/article/details/86366722
————————————————
版权声明:本文为CSDN博主「LiryZlian」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lzxlfly/article/details/86366722
import org.apache.spark.SparkConfimport org.apache.spark.SparkContext object FilterIP { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("broadcast"); conf.setMaster("local"); val sc = new SparkContext(conf); val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取 //spark2.0.0中sc.accumulator(0)不被推荐,用如下方式初始值,默认0 val accumulator=sc.longAccumulator("accumulator"); val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取 //在driver端进行广播blackList val broadCast = sc.broadcast(blackList); val filterRdd =lineRdd.filter(ip =>{ broadCast.value.contains(ip)}) filterRdd.foreach(ip =>{ accumulator.add(1); }) //打印出非法ip的访问数量 println("driver sum="+accumulator.value) }}
spark累加器、广播变量的更多相关文章
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
- Spark学习之路 (四)Spark的广播变量和累加器[转]
概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上,并 ...
- Spark的广播变量模块
有人问我,如果让我设计广播变量该怎么设计,我想了想说,为啥不用zookeeper呢? 对啊,为啥不用zookeeper,也许spark的最初设计哲学就是尽量不使用别的组件,他有自己分布式内存文件系统, ...
- spark的广播变量
直接上代码:包含了,map,filter,persist,mapPartitions等函数 String master = "spark://192.168.2.279:7077" ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- 【Spark-core学习之七】 Spark广播变量、累加器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
随机推荐
- 树莓派4B基本配置
一.系统安装 官网下载好系统解压,使用SD Card Formatter格式化内存卡 # 查看内存卡状态,通过内存卡大小判断是哪个 df -lh # 卸载内存卡 diskutil unmount /d ...
- groovy常用语法及实战
groovy语言简介 一种基于JVM的敏捷开发语言,作为编程语言可编译成java字节码,也可以作为脚本语言解释执行. 结合了Python.Ruby和Smalltalk的许多强大的特性 支持面向对象编程 ...
- framework7 Autocomplete (自动完成) 具体使用
官网地址:https://framework7.io/docs/autocomplete.html#autocomplete-parameters 效果图: <meta charset=&quo ...
- .net core mvc启动顺序以及主要部件3-Startup
前面分享了.net core Program类的启动过程已经源代码介绍,这里将继续讲Startup类中的两个约定方法,一个是ConfigureServices,这个方法是用来写我们应用程序所依赖的组件 ...
- Delphi面向对象的编程思想
第一章.建立面向对象的新思维 1.1.1历史背景 目前对象技术的前沿课题包括设计模式.分布式对象系统.和基于网络的对象应用等 目前面向对象的语言包含4个基本的分支: 1.基于Smalltalk的:包括 ...
- 【SQL】各取所需 | SQL JOIN连接查询各种用法总结
前面 在实际应用中,大多的查询都是需要多表连接查询的,但很多初学SQL的小伙伴总对各种JOIN有些迷糊.回想一下,初期很长一段时间,我常用的似乎也就是等值连接 WHERE 后面加等号,对各种JOIN也 ...
- Django--母版
目录 母版 语法 案例 在之前的两个小程序中,可以发现在写html页面的时候有很多重复的代码 而在python中,为了避免写重复代码,我们通过函数.模块或者类来进行实现,所以在Django里面也有这样 ...
- .NET CORE 动态加载 DLL 的问题
有个系统, 需要适应不同类型的数据库(同时只使用其中一种),如果把数据库操作层提取出来,然后针对不同的数据库使用不同的 DLL, 再根据不同的项目使用不同的库, 在以前的 ASP.NET 中, 直接把 ...
- 如何显示IntelliJ IDEA工具的Run Dashboard功能(转)
从 JetBrains released IntelliJ IDEA 2017.2.1 版本之后,新出的功能‘Run Dashboard,它能非常方便的提供开发人员查看本地springboot服务运行 ...
- Java语言的介绍
1. 计算机语言 语言:沟通交流的方式 计算机语言:人与计算机之间的交流方式 java是一门计算机编程语言,也是意大利自行车品牌 软件工程师,java开发工程师 <--------------- ...