Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
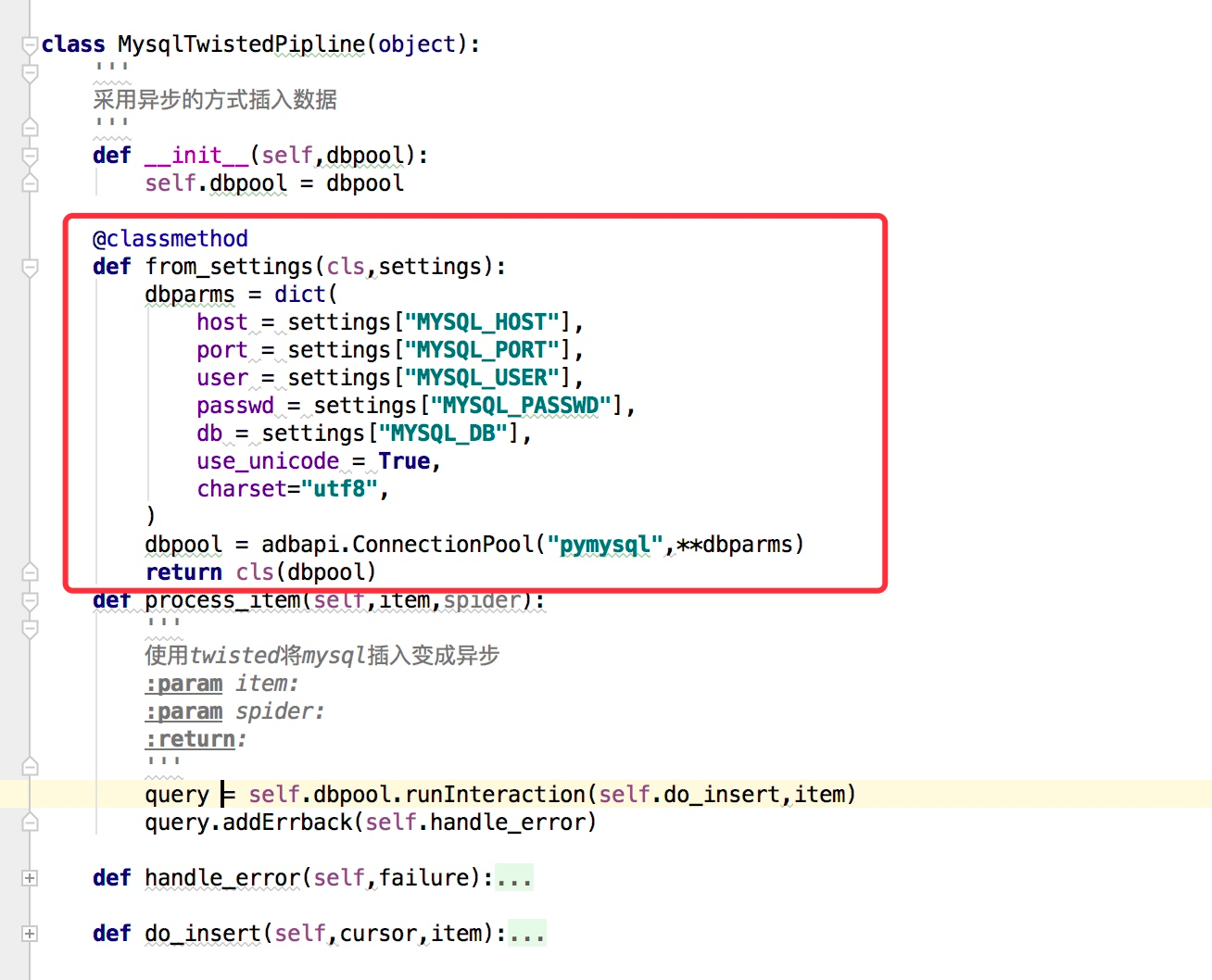
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法的更多相关文章
- Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- Python之爬虫(十九) Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫开发【第1篇】【Scrapy框架】
Scrapy 框架介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架. Srapy框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
随机推荐
- source install sshpass in aix
1.源码下载: wget https://nchc.dl.sourceforge.net/project/sshpass/sshpass/1.06/sshpass-1.06.tar.gz 2.解压 ...
- 一天搞定CSS:层级(z-index)--18
因为定位的出现,所以有了元素重叠的情况,此时就出现了显示谁的情况.在多层布局时,容易出现这种情况 定位position见:http://blog.csdn.net/baidu_37107022/art ...
- Mybatis中如何查询时间段内的数据
最后一个是正确的,前边的三个是可能遇到的坑,给大家展示一下,如果不需要的,可以直接跳到最后看: 有时候我们需要查询一张表内一段时间内操作的数据,大家很容易就想到了 between ? and ? 这个 ...
- MySQL优化之表结构优化的5大建议(数据类型选择讲的很好)
殊不知,在N年前被奉为"圣经"的数据库设计3范式早就已经不完全适用了.这里我整理了一些比较常见的数据库表结构设计方面的优化技巧,希望对大家有用. 由于MySQL数据库是基于行(Ro ...
- (转)对Http协议的长连接和短连接新的认识
转载来自:http://www.cnblogs.com/zuoxiaolong/p/life49.html一直对长连接短连接模模糊糊,看着该博主的文章,豁然开朗~ 引言 最近刚到公司不到一个月,正处于 ...
- memcached配置
首先是安装libevent库,执行如下的命令 tar vzxf libevent-2.0.21-stable.tar.gz cd libevent-2.0.21-stable ./configure ...
- eclipse tomcat add时提示The Tomcat server configuration at \Servers\Tomcat v6.0 Server at localhost-
原因为左侧项目中把对于网络应用的servers项目给关闭或删除了,导致相应的localhost-config无法定位,所以才发生的错误. 解决办法:删除servers下的tomcat 重新添加serv ...
- 微信小程序代开发
微信申请第三方之后可以获取授权方的很多权限,主要的是生码和待开发,生码的第三方授权之前已经写了一篇文章,最近做了小程序待开发,总结一下写下来供大家参考 注意事项:如果在调试过程中返回了错误码请到小程序 ...
- v9更新栏目缓存提示PHP has encountered a Stack overflow解决方法
原因: 客户在把一些栏目删除或者新增栏目时没更新栏目缓存导致v9_category表里有原来的垃圾信息,多余的表. 解决方法:通过phpmyadmin找到栏目表出错的条目,修改错误信息. 具体步骤: ...
- 提高驾驶技术:用GAN去除(爱情)动作片中的马赛克和衣服
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/27199954 作为一名久经片场的老司机,早就想写一些探讨驾驶技术的文章.这篇就介绍利用生成式对抗网络(GAN)的两个基 ...