Scrapy-多层爬取天堂图片网
1.根据图片分类对爬取的图片进行分类

开发者选项 --> 找到分类地址

爬取每个分类的地址通过回调函数传入下一层
name = 'sky'
start_urls = ['http://ivsky.com/']
def parse(self, response):
selector = Selector(response)
# print(response.text)
types = selector.xpath("//div[@class='kw']/a")
for type in types:
typeUrl = type.xpath("@href").extract()[0] #分类地址
typeName = type.xpath("text()").extract()[0] #分类名称
# print(typeUrl+" "+typeName)
yield Request(self.start_urls[0]+typeUrl,callback=self.parseTotalPage,meta={'typeName':typeName})
2.点击进入一个类型 --> 开发者选项 --> 找到分页代码段

爬取每一个分页的地址也是通过回调函数传入下一层进行处理
def parseTotalPage(self,response):
typeName = response.meta["typeName"]
# print(typeName)
selector = Selector(response)
# print(response.text)
pageList = selector.xpath("//div[@class='pagelist']//a//@href").extract() #每一页的地址
for page in pageList:
yield Request(self.start_urls[0]+page,callback=self.parseGetImg,meta={'typeName':typeName})
3.获取一类图地址 --> 开发者选项 --> 找到相同类图的地址

爬取这类图的地址通过回调函数传入下一层进行处理
def parseGetImg(self,response):
typeName = response.meta["typeName"]
selector = Selector(response)
imgs = selector.xpath("//div[@class='il_img']//a")
for img in imgs:
imgUrl = img.xpath("@href").extract()[0] #一类图的地址
# print(imgUrl+" "+imgName)
yield Request(self.start_urls[0]+imgUrl,callback=self.parseGetMoreImg)
4.查看每张图片的html代码 --> 找到图片的地址
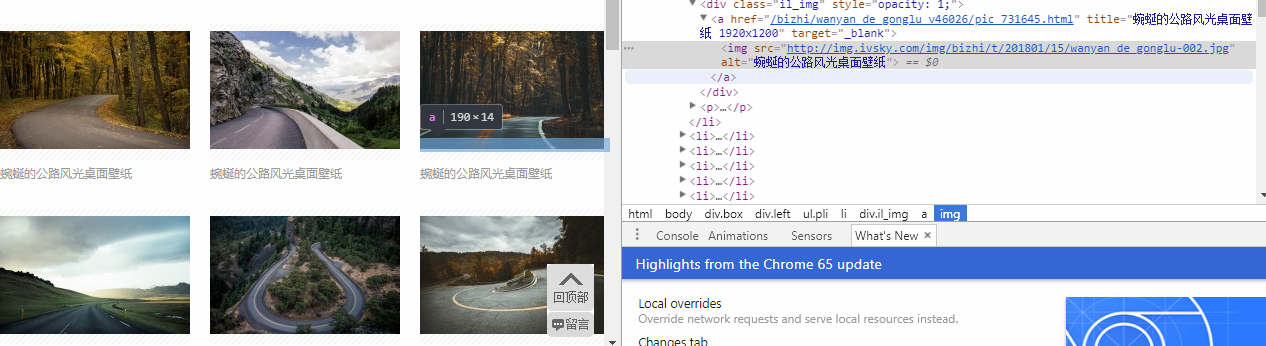
爬取每张图的地址
def parseGetMoreImg(self,response):
# / html / body / div[3] / div[4] / ul / li[3] / div / a / img
selector = Selector(response)
# print(response.text)
items = IvskyItem()
items["imgName"] = response.meta["imgName"]
items["imgUrl"] = selector.xpath("//div[@class='il_img']//a//img//@src").extract()
# print(items)
yield items
最后将图片传入pipelines.py 进行下载处理,要先在setting.py 设置,否则无法进入pipelines.py
ITEM_PIPELINES = {
'ivsky.pipelines.IvskyPipeline': 300,
}
代码地址:https://github.com/WitW/ivsky
Scrapy-多层爬取天堂图片网的更多相关文章
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- scrapy实例:爬取中国天气网
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\ScrapyProject> scrapy startproject weather # w ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Python的scrapy之爬取妹子图片
闲来无事,做的一个小爬虫项目 爬虫主程序: import scrapy from ..items import MeiziItem class MztSpider(scrapy.Spider): na ...
- 使用scrapy爬虫,爬取起点小说网的案例
爬取的页面为https://book.qidian.com/info/1010734492#Catalog 爬取的小说为凡人修仙之仙界篇,这边小说很不错. 正文的章节如下图所示 其中下面的章节为加密部 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法二
楼主准备爬取此页面的小说,此页面一共有125章 我们点击进去第一章和第一百二十五章发现了一个规律 我们看到此链接的 http://www.17k.com/chapter/271047/6336386 ...
- Python爬虫【实战篇】scrapy 框架爬取某招聘网存入mongodb
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.p ...
随机推荐
- CentOS 7安装Tomcat8
一.安装环境 tomcat的安装依赖于Java JDK,需要先安装配置正确的JDK http://www.cnblogs.com/VoiceOfDreams/p/8376978.html 二.安装包准 ...
- 一分钟搭建Vue2.0+Webpack2.0多页面项目
想要自己一步步搭建的比较麻烦,不是很推荐,最少也要使用vue-cli,在其基础上开始搭建,今天我的主题是一分钟搭建,那么常规方法肯定不能满足的, 而我用的方法也很简单,就是使用已经配置完成的demo模 ...
- 自定义jstl fn函数fns
1.引入函数声明: jsp页面需要引入自定义fns函数声明:<%@ taglib prefix="fns" uri="/WEB-INF/tlds/fns.tld&q ...
- iptables nat及端口映射
iptables nat及端口映射 发布: 2010-6-11 15:05 | 作者: admin | 来源: SF NetWork 门户网站 iptables 应用初探(nat+三层访问控制) ip ...
- DS18B20温度传感器知识点总结
2018-01-1818:20:48 感觉自己最近有点凌乱,一个很简单的问题都能困扰自己很久.以前能很好使用和调试的DS18B20温度传感器,今天愣是搞了很久,妈卖批. 仅仅一个上拉电阻就困扰了我很久 ...
- python_7_列表
什么是列表? --一种数据类型 -- 形式:[值1,值2,[值a,值b],值3] --可以嵌套 #!/usr/bin/python3 list_a = [1, 2, [3, 'a']] 对于 ...
- linkin大话面向对象--构造器详解
对象的产生格式:类名称 对象名 = new 类名称(); 因为有(),所以是方法,实际上它就是构造方法,并且是非私有的构造方法.如:CellPhone cp = new CellPhone( ...
- jdk源码->集合->ArrayList
类的属性 public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomA ...
- c++ singleton单例模式
方法1:加锁的经典懒汉实现: class singleton { public: static pthread_mutex_t mutex; static singleton* initance(); ...
- 定时任务schedule(spring boot )
1. 定时任务实现方式:SpringBoot自带的Scheduled,可以将它看成一个轻量级的Quartz,而且使用起来比Quartz简单许多,本文主要介绍. 执行方式:单线程(串行)多线程(并行) ...