使用scrapy爬虫,爬取起点小说网的案例
爬取的页面为https://book.qidian.com/info/1010734492#Catalog
爬取的小说为凡人修仙之仙界篇,这边小说很不错。
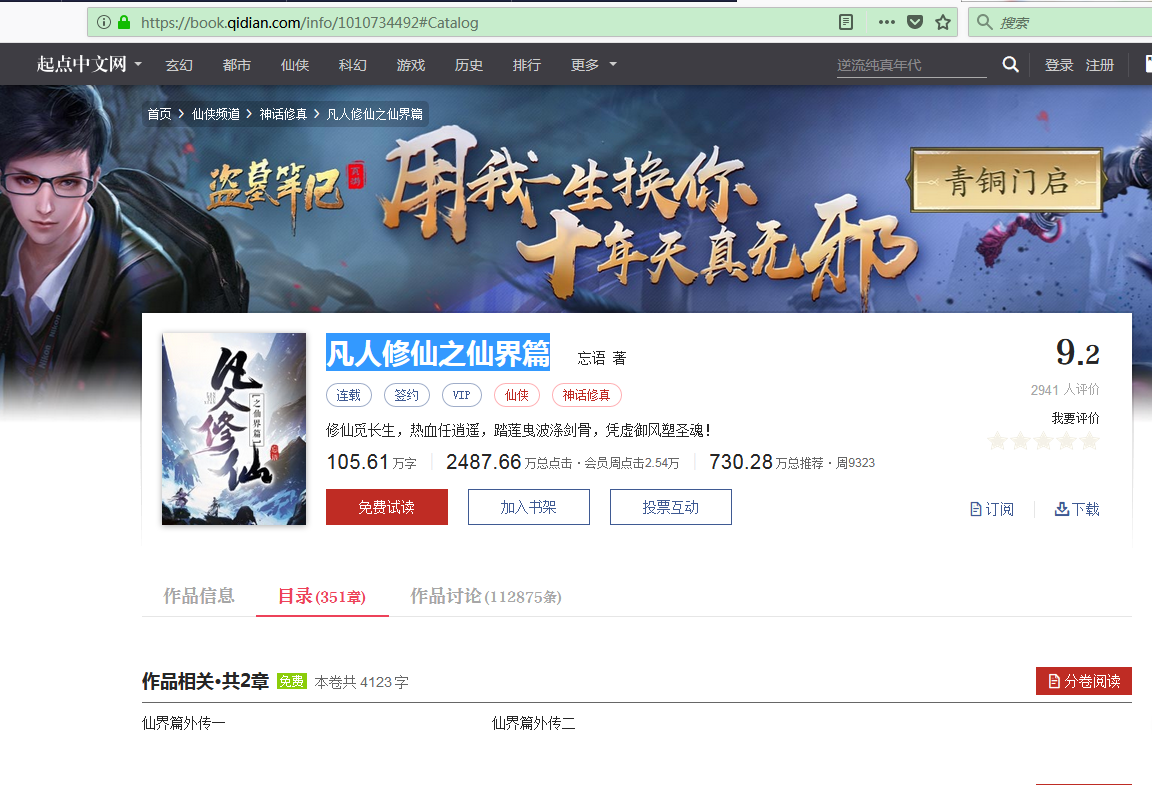
正文的章节如下图所示
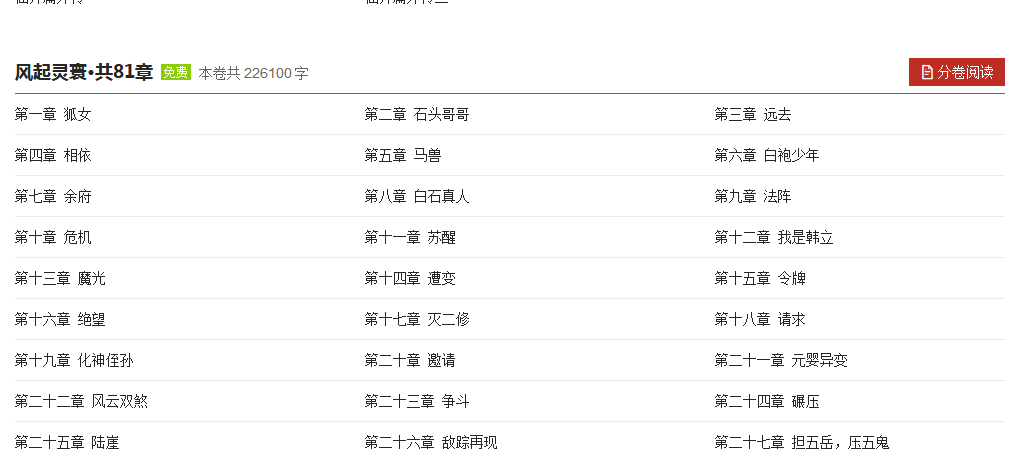
其中下面的章节为加密部分,现在暂时无法破解加密的部分。ε=(´ο`*)))唉..

下面直接上最核心的代码(位于spiders中的核心代码)
# -*- coding: utf-8 -*-
import scrapy from qidian.items import QidianItem
import enum
class Qidian1Spider(scrapy.Spider):
name = 'qidian1'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010734492#Catalog']
def parse(self, response):
#div[@class="volume"][1或者2或者3或者4]中的数值,这些数值自定义一个变量替代,目前一共是4个部分,随着后续章节的增加,会出现第五部分或者第六部分 依次累加
###div[@class="volume"]["num"] ,num是自定义的变量,你可以换成自己想要的abc或者bb等变量,把这些变量放进去,就能得到所有章节的title??(不知道为什么)
for aa in response.xpath(
'//div[@class="volume-wrap"]/div[@class="volume"]["'
'这里填啥都行,不填就报错,或者去掉class=volume后面的这个中括号就得不到a标签中的标题,我也不知道什么原因!!!"]'
'/ul[@class="cf"]/li'): title=aa.xpath("a/text()").extract()
link=aa.xpath("a/@href").extract()
for new_link in link:
new_links="https:"+str(new_link)
yield scrapy.Request(new_links, callback=self.parse_content) def parse_content(self,response):
for bb in response.xpath('//div[@class="main-text-wrap"]'):
title=bb.xpath('//div[@class="text-head"]/h3[@class="j_chapterName"]/text()').extract()
content = bb.xpath('//div[@class="read-content j_readContent"]/p/text()').extract()
kong_list=list(''.join(title))
item=QidianItem()
item['title']=title
item['content']=content
yield item
在items.py中的核心代码为
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QidianItem(scrapy.Item): title = scrapy.Field()
link = scrapy.Field()
content = scrapy.Field()
在pipelines.py中的核心代码为
# -*- coding: utf-8 -*- import json
class QidianPipeline(object):
def process_item(self, item, spider):
return item
#初始化时指定要操作的文件
def __init__(self):
self.file = open('item.json', 'w', encoding='utf-8')
# 存储数据,将 Item 实例作为 json 数据写入到文件中
def process_item(self, item, spider): lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(lines)
return item
# 处理结束后关闭 文件 IO 流
def close_spider(self, spider):
self.file.close()
我们最后得到的结果为像这种的。
 ........
........
使用scrapy爬虫,爬取起点小说网的案例的更多相关文章
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法二
楼主准备爬取此页面的小说,此页面一共有125章 我们点击进去第一章和第一百二十五章发现了一个规律 我们看到此链接的 http://www.17k.com/chapter/271047/6336386 ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- python3爬虫-使用requests爬取起点小说
import requests from lxml import etree from urllib import parse import os, time def get_page_html(ur ...
- scrapy实例:爬取中国天气网
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\ScrapyProject> scrapy startproject weather # w ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- python利用scrapy框架爬取起点
先上自己做完之后回顾细节和思路的东西,之后代码一起上. 1.Mongodb 建立一个叫QiDian的库,然后建立了一个叫Novelclass(小说类别表)Novelclass(可以把一级类别二级类别都 ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
随机推荐
- Vue中循环的反人类设计
今天学习Vue到循环那里,表示真是不能理解Vue的反人类设计 具体看代码吧! <!DOCTYPE html> <html> <head> <meta char ...
- django 之MTV模型
一个小问题: 什么是根目录:就是没有路径,只有域名..url(r'^$') 补充一张关于wsgiref模块的图片 一.MTV模型 Django的MTV分别代表: Model(模型):和数据库相关的,负 ...
- vue配置jquery和bootstarp
jquery: 1.npm install jquery --save-dev 引入jquery. 2.在webpack.base.conf.js中添加如下内容: var webpack = requ ...
- 解决Ajax请求后台Servlet接口拿不到JSON数据问题
前端Ajax请求代码如下: window.onload=function() { var url='http://127.0.0.1:8080/testpj/ErrorlogServlet'; $.a ...
- did not finish being created even after we waited 189 seconds or 61 attempts. And its status is downloading
did not finish being created even after we waited 189 seconds or 61 attempts. And its status is down ...
- opencv + cuda编译
#获取最新代码git clone "https://github.com/opencv/opencv.git" #build目录mkdir buildcd build #使用ccm ...
- BeanShell 教程索引帖
一.BeanShell的基本简介 二.BeanShell环境配置 三.BeanShell语法表达式和常用命令 四.Jmeter-BeanShell使用 五.BeanShell PreProcessor ...
- linux device drivers ch03
ch03.字符设备驱动程序 编写驱动程序的第一步就是定义驱动程序为用户程序提供的能力(机制).接下来以scull(“Simple Character Utility for Loading Local ...
- leveldb实现原理
LevelDb日知录之一:LevelDb 101 说起LevelDb也许您不清楚,但是如果作为IT工程师,不知道下面两位大神级别的工程师,那您的领导估计会Hold不住了:Jeff Dean和Sanja ...
- 分布式协调服务Zookeeper集群搭建
分布式协调服务Zookeeper集群搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装jdk环境 1>.操作环境 [root@node101.yinzhengjie ...