python3爬取淘宝商品(失效)
最近有人反映淘宝的搜索功能要登录才能用,原先的直接爬取的方法挂了。稍微把之前的代码修改了一下,登录采用最简单的复制cookie来解决。
顺便说一下,这只是根据搜索的的索引界面获取的信息,并未深入的获取每个具体商品的信息。为了以后有拓展空间,便于爬取详细的商品信息,我顺便把详情页的URL拿下来了。
淘宝的页面其实并未做多大改变(吐槽一下:淘宝的程序员也挺懒的),之前的代码只要加上登录功能就能使用。
直接上代码:
import requests
from bs4 import BeautifulSoup
import re
from xlwt import Workbook
import xlrd
import sys R = requests.Session()
URL = "https://s.taobao.com/search?q=" """
Get_Html()函数功能:根据搜索的关键字和页数信息,获取包含数据的HTML源码
参数:
keyword:字符串,搜索的关键字
page:字符串,页数
返回值:
text:字符串,包含数据的HTML源码
"""
def Get_Html(keyword,page):
url = URL+keyword+"&ie=utf8&s="+str(page)
cookies = {}
raw_cookies = #这里copy你的cookie,我自然不可能放我的
for lies in raw_cookies.split(';'):
key,word = lies.split('=',1)
cookies[key] = word res = R.get(url,cookies = cookies)
text = res.text
return text """
Get_Data()函数功能:从包含数据的HTML源码中解析出需要的数据
参数:
text:字符串,是一些包含数据的HTML源码
返回值:
data:字符串,包含需要数据的json字符串
"""
def Get_Data( text):
reg = r',"data":{"spus":\[({.+?)\]}},"header":'
reg = re.compile(reg)
data = re.findall(reg, text)[0]
return data """
Download_Data()函数功能:将获取的数据选择一部分写入excel表格,如果想写入数据库,这部分代码需要自己写
参数:
data:包含数据的json字符串
N:写入excel表的第几行
sheet:excel表的一张表的句柄
"""
def Download_Data( data, N, sheet ):
Date = eval(data) for d in Date:
sheet.write(N,0,d['title'])
sheet.write(N,1,d['price'])
sheet.write(N,2," ".join([t['tag'] for t in d['tag_info']]))
sheet.write(N,3,d['url'][2:])
N = N + 1
return N """
主调函数,函数工作流程大致如下:
1.创建存储数据需要的sheet表格,目前只获取四个个特征:手机名、价格、特点和商品链接
2.按照关键字进行搜索,然后将获得的数据全部存入创建好的sheet中。
参数:
keyword:要搜索的关键字
"""
def main(keyword):
book = Workbook()
sheet = book.add_sheet(keyword)
sheet.write(0,0,'品牌')
sheet.write(0,1,'价格')
sheet.write(0,2,'特点')
sheet.write(0,3,'链接')
book.save('淘宝数据.xls') k = 0
N = 1
i = 0
while(True):
text = Get_Html(keyword,i*48)
try: data = Get_Data(text)
N = Download_Data(data,N,sheet)
except:
break book.save('淘宝数据.xls')
print('下载第' + str(i+1) + '页完成')
i = i + 1 print('全部数据收集完成') if __name__ == '__main__':
keyword = sys.argv[1]
main(keyword)
只要把上面的Get_HTML()函数中的 raw_cookies 修改成你的 cookie 就可以了,至于怎么获取 cookie ,Google吧!
下面是我以"华为手机"为关键字的部分搜索结果: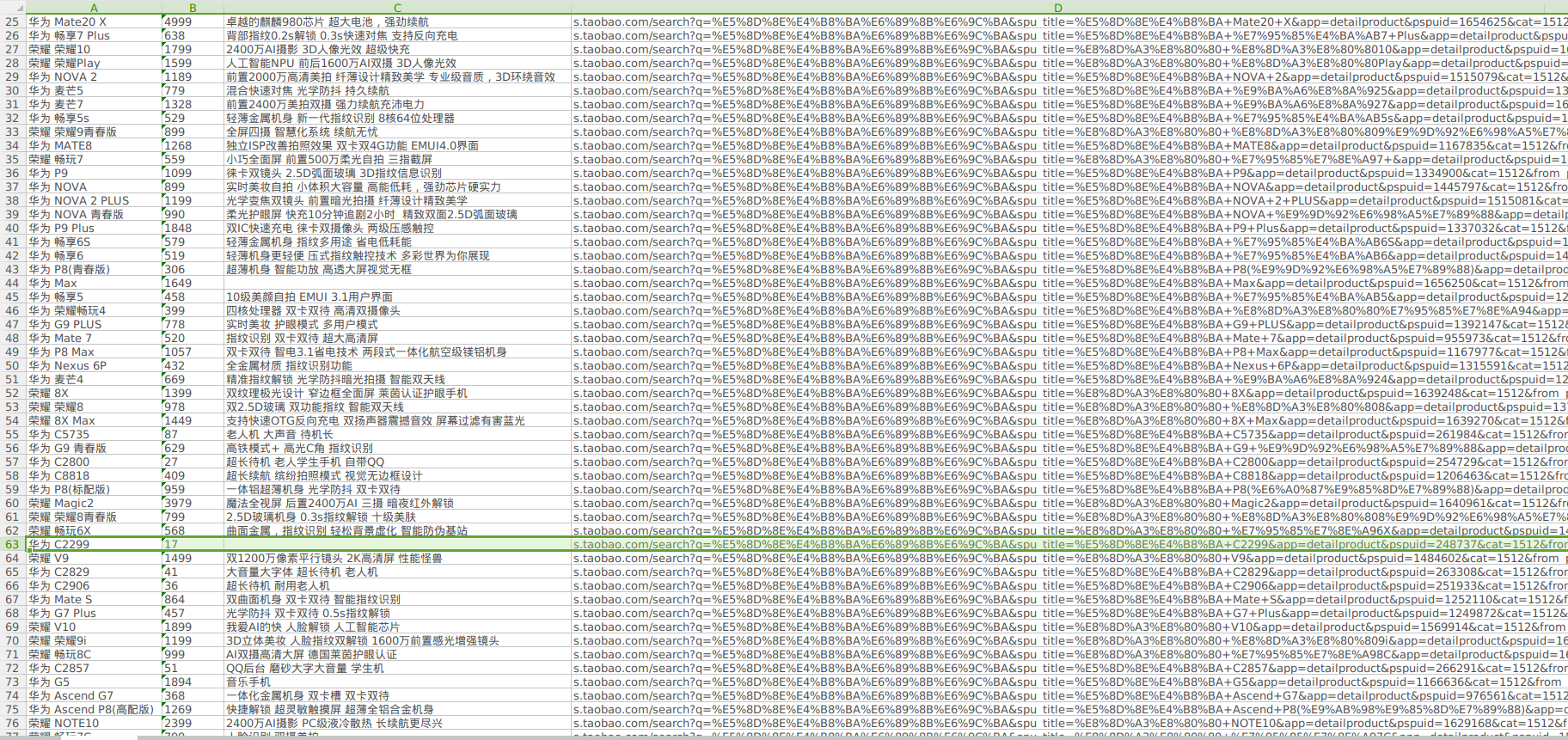
发现了一个17块的华为手机,复制链接一看:
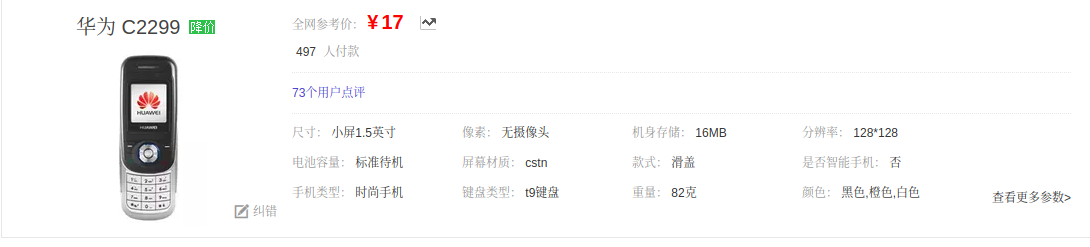
果然...
上面这个页面的信息和评论信息才是更有用的数据,以后有时间再看弄不弄吧!
python3爬取淘宝商品(失效)的更多相关文章
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
- 爬取淘宝商品信息,放到html页面展示
爬取淘宝商品信息 import pymysql import requests import re def getHTMLText(url): kv = {'cookie':'thw=cn; hng= ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- 使用Selenium爬取淘宝商品
import pymongo from selenium import webdriver from selenium.common.exceptions import TimeoutExceptio ...
随机推荐
- [Linux-CentOS7]安装Telnet
# yum install telnet Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile Resolv ...
- 浮动和包含框的关系,伪元素after解决高度塌陷
浮动会使元素尽量向左或向右移动,直到碰到包含框或另外一个浮动元素的盒子模型的边缘 包含框并不会改变里面浮动元素的宽高,浮动元素宽高不会限制在包含块以内 <!DOCTYPE html> &l ...
- 五分钟了解抽象语法树(AST)babel是如何转换的?
抽象语法树 什么是抽象语法树? It is a hierarchical program representation that presents source code structure acco ...
- MySQL 数据库的提速器-写缓存(Change Buffer)
写缓存(Change Buffer) 是一种特殊的数据结构,用于在对数据变更时,如果数据所在的数据页没有在 buffer pool 中的话,在不影响数据一致性的前提下,InnoDB 引擎会将对数据的操 ...
- C#设计模式学习笔记:(18)状态模式
本笔记摘抄自:https://www.cnblogs.com/PatrickLiu/p/8032683.html,记录一下学习过程以备后续查用. 一.引言 今天我们要讲行为型设计模式的第六个模式--状 ...
- java设计模式4——原型模式
java设计模式4--原型模式 1.写在前面 本节内容与C++语言的复制构造函数.浅拷贝.深拷贝极为相似,因此建议学习者可以先了解C++的该部分的相关知识,或者学习完本节内容后,也去了解C++的相应内 ...
- 使用MuMu模拟器调试AndroidStudio项目
1.安装一款安卓模拟器 本例使用网易MuMu模拟器,因为目前网络上这类模拟器只有mumu的安卓版本是最新的,为6.0,安卓自带的Virtual Device虽然有很新的版本,但如果pc配置不是很高 ...
- MySQL的JDBC驱动(8.0版本)
1.引用外部库 mysql-connector-java-8.0.版本的jar 2.jdbc驱动类:com.mysql.jdbc.Driver 改成 com.mysql.cj.jdbc.Drive ...
- Everspin串口串行mram演示软件分析
Everspin在磁存储器设计,制造和交付给相关应用方面的知识和经验在半导体行业中是独一无二的.在平面内和垂直磁隧道结(MTJ)STT-MRAM位单元的开发方面处于市场领先地位.包括40nm,28nm ...
- 什么是kafka,怎么使用? (3)
上次我因为在windows上解压一个.gz的包没有解压出来,故需要在linux使用kafka,而且这kafka的快速开始上有个zookeeper的文件配置 所以我感觉有必要把dubbo-zookeep ...