Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1、Scrapy使用流程
1-1、使用Terminal终端创建工程,输入指令:scrapy startproject ProName

1-2、进入工程目录:cd ProName

1-3、创建爬虫文件(此篇介绍使用spider下的Crawlspider 派生类新建爬虫文件 ),scrapy genspider -t craw spiderFile www.xxx.com

1-4、执行工程,scrapy crawl spiderFile (待编程结束执行此命名)
需到新建工程下执行

2、创建爬虫并编写代码
2-1、编写items.py
import scrapy
# title及状态类、时间
class MsproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 来信标题
AcceptTime = scrapy.Field() # 受理时间
status = scrapy.Field() # 受理状态
# 详情受理单位及内容
class DetailItem(scrapy.Item):
detailTitle = scrapy.Field() # 详情页标题
reviseUnit = scrapy.Field() # 受理单位
FromTime = scrapy.Field() # 来信时间
content = scrapy.Field() # 来信内容
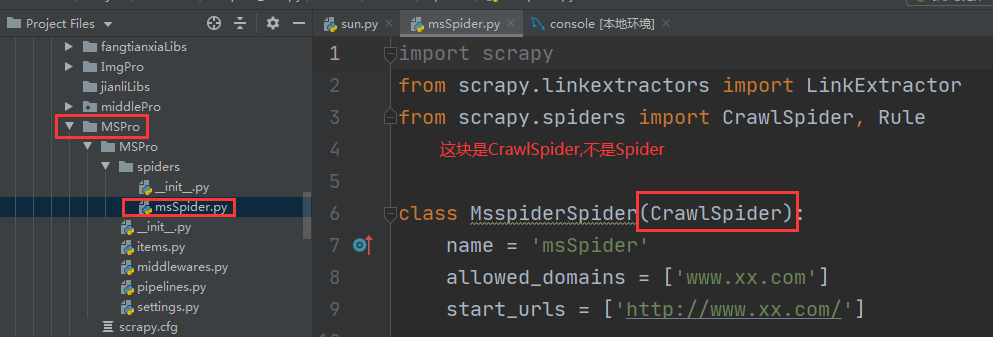
2-2、编写Spider/msSpider.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from MSPro.items import MsproItem,DetailItem
class MsspiderSpider(CrawlSpider):
name = 'msSpider'
# allowed_domains = ['www.xx.com']
start_urls = ['http://wlwz.huizhou.gov.cn/wlwzlist.shtml?method=letters4bsznList3&reload=true&pager.offset=0']
# 链接提取器:根据指定规则(allow='正则')提取指定链接提取
link = LinkExtractor(allow=r'&pager.offset=\d+')
# 提取详情页的链接
linkDetail = LinkExtractor(allow=r'&lid=\d+')
# 规则提取器:将链接提取器提取的规则来进行callback解析操作
rules = (
Rule(link, callback='parse_item', follow=True),
# follow作用:可以继续将链接提取器作用到连接提取到所对应的页面中
Rule(linkDetail, callback='parse_detail')
)
# 如下两个请求方法中是不可以使用请求传参scrapy.Request
# 如何将两个方法解析的数据存储到item中,需实现两个存储items
# 在此方法中可以解析标题,受理状态
def parse_item(self, response):
# 注意:xpath中不可以存在tbody标签
trlist = response.xpath('/html/body/table//tr/td/table//tr[2]/td/table[2]//tr')
for tr in trlist:
# 标题
title = tr.xpath('./td[2]/a//text()').extract_first()
title = "".join(title).strip()
# 受理时间
AcceptTime = tr.xpath('./td[4]//text()').extract_first()
AcceptTime = "".join(AcceptTime).strip()
# 受理状态
status = tr.xpath('./td[5]//text()').extract_first().strip()
# print("来信标题:", title)
# print("受理状态:", status)
item = MsproItem()
item['title'] = title,
item['AcceptTime'] = AcceptTime,
item['status'] = status
# 提交item到管道
yield item
# 此方法解析详情页的内容及受理单位
def parse_detail(self, response):
tbodylist = response.xpath('/html/body/table//tr[2]/td/table//tr[2]/td/table[1]')
for tbody in tbodylist:
# 详情页来信主题
detailTitle = tbody.xpath('.//tr[2]/td[2]//text()').extract()
# 字符串拼接及去掉前后空格
detailTitle = "".join(detailTitle).strip()
# 受理单位
reviseUnit = tbody.xpath('.//tr[3]/td[2]//text()').extract()
# 字符串拼接及去掉前后空格
reviseUnit = "".join(reviseUnit).strip()
# 来信时间
FromTime = tbody.xpath('.//tr[3]/td[4]//text()').extract_first()
# 字符串拼接及去掉前后空格
FromTime = "".join(FromTime).strip()
# 来信内容
content = tbody.xpath('.//tr[5]/td[2]//text()').extract()
# 字符串拼接及去掉前后空格
content = "".join(content).strip()
# print("受文单位:",reviseUnit)
# print("来信内容:",content)
item = DetailItem()
item['detailTitle'] = detailTitle,
item['reviseUnit'] = reviseUnit,
item['FromTime'] = FromTime,
item['content'] = content
# 提交item到管道
yield item
2-3、编写pipelines.py
import pymysql
class MsproPipeline:
def process_item(self, item, spider):
# 如何判断item的类型
if item.__class__.__name__ == 'MsproItem':
print(item['title'][0],item['AcceptTime'][0],item['status'])
else:
print(item['detailTitle'][0],item['FromTime'][0],item['reviseUnit'][0],item['content'])
return item
# 数据写入到数据库中
class MysqlSpiderPipeline:
def __init__(self):
self.conn = None
self.cursor = None
def process_item(self, item, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password="123456", db='qsbk',
charset='utf8')
self.cursor = self.conn.cursor()
try:
if item.__class__.__name__ == 'SunproItem':
sql = "insert into info(Title,Status,AcceptTime) values (%s,%s,%s)"
params = [(item['title'][0], item['status'], item['AcceptTime'][0])]
# 执行Sql
self.cursor.executemany(sql, params)
# 提交事物
self.conn.commit()
else:
sql = "UPDATE info Set ReviseUnit = %s,Content = %s, FromTime = %s where title = %s"
params = [(item['reviseUnit'][0],item['content'],item['FromTime'][0],item['detailTitle'][0])]
# 执行Sql
self.cursor.executemany(sql,params)
# 提交事物
self.conn.commit()
except Exception as msg:
print("插入数据失败:case%s" % msg)
self.conn.rollback()
finally:
return item
def close_sipder(self, spider):
# 关闭游标
self.cursor.close()
# 关闭数据库
self.conn.close()
2-4、编写settings文件
BOT_NAME = 'MSPro'
SPIDER_MODULES = ['MSPro.spiders']
NEWSPIDER_MODULE = 'MSPro.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
LOG_LEVEL = 'ERROR'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#开启管道~ 写入本地或写入数据库中
ITEM_PIPELINES = {
'MSPro.pipelines.MsproPipeline': 300,
'MSPro.pipelines.MysqlSpiderPipeline': 301,
}
3、使用Pycharm连接MySQL数据库
3-1、连接数据库
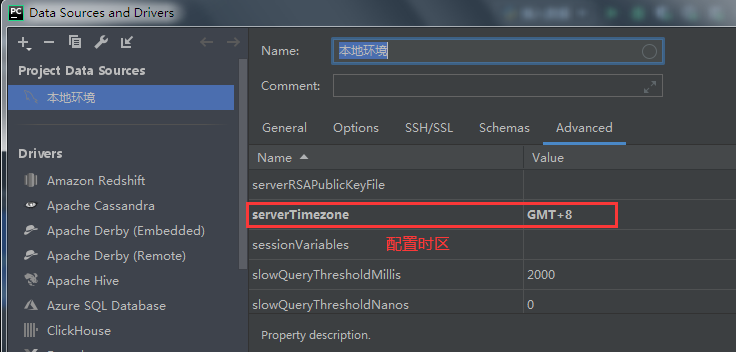
3-2、连接数据库界面操作

4、创建爬虫项目对应表及执行爬虫工程
4-1、创建数据库表

drop table MSBasic;
CREATE TABLE `MSBasic`
(
`id` int(100) NOT NULL AUTO_INCREMENT,
`Title` varchar(200) DEFAULT NULL,
`Status` varchar(100) DEFAULT NULL,
`ReviseUnit` varchar(200) DEFAULT NULL,
`Content` text(0) DEFAULT NULL,
`FromTime` varchar(100) DEFAULT NULL,
`AcceptTime` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) engine = InnoDB
default charset = utf8mb4;
4-2、执行爬虫文件

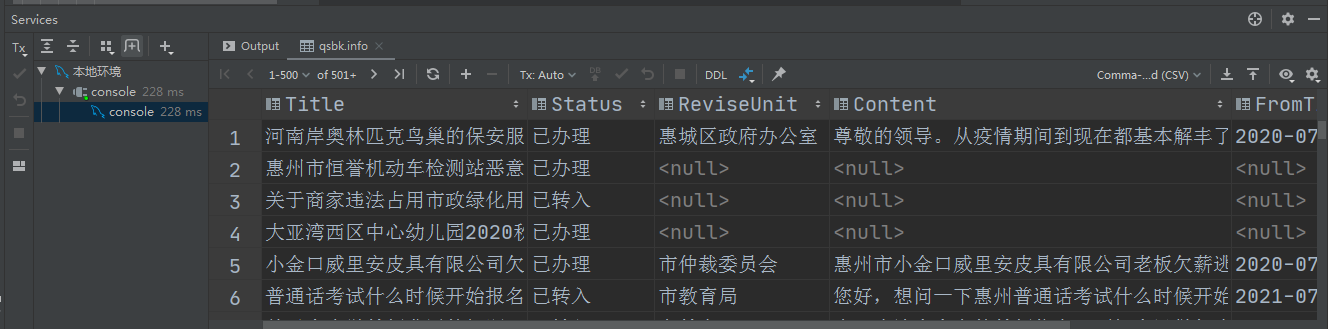
4-3、验证爬虫结果
Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库的更多相关文章
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- 爬虫必知必会(6)_提升scrapy框架爬取数据的效率之配置篇
如何提升scrapy爬取数据的效率:只需要将如下五个步骤配置在配置文件中即可 增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_ ...
- python模拟浏览器爬取数据
爬虫新手大坑:爬取数据的时候一定要设置header伪装成浏览器!!!! 在爬取某财经网站数据时由于没有设置Header信息,直接被封掉了ip 后来设置了Accept.Connection.User-A ...
- Scrapy框架——使用CrawlSpider爬取数据
引言 本篇介绍Crawlspider,相比于Spider,Crawlspider更适用于批量爬取网页 Crawlspider Crawlspider适用于对网站爬取批量网页,相对比Spider类,Cr ...
- 提升Scrapy框架爬取数据效率的五种方式
1.增加并发线程开启数量 settings配置文件中,修改CONCURRENT_REQUESTS = 100,默认为32,可适当增加: 2.降低日志级别 运行scrapy时会产生大量日志占用CPU,为 ...
- python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书
1.初衷:想在网上批量下载点听书.脱口秀之类,资源匮乏,大家可以一试 2.技术:wireshark scrapy jsonMonogoDB 3.思路:wireshark分析移动APP返回的各种连接分类 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
随机推荐
- fiddler选项卡-Filters(过滤)
Filter filter的意思是过滤,在fiddler中,它可以用来过滤请求,使得session列表能够更加精准的展现抓到的数据流,而不是杂乱的一堆. 1.filter的界面 2.界面详解 1.Us ...
- 【逆向&编程实战】Metasploit安卓载荷运行流程分析_复现meterpreter模块接管shell
/QQ:3496925334 作者:MG193.7 CNBLOG博客号:ALDYS4 未经许可,禁止转载/ 关于metasploit的安卓模块,前几次的博客我已经写了相应的分析和工具 [Android ...
- Docker系列——Grafana+Prometheus+Node-exporter钉钉推送(四)
近期搭建的服务器监控平台,来进行一个总结.主要分为监控平台的搭建.告警中心的配置以及消息的推送.推送的话,支持多种终端.具体详细可查看之前的博文,在这里罗列下,方便查看. Docker系列--Graf ...
- Transformers for Graph Representation
Do Transformers Really Perform Badfor Graph Representation? microsoft/Graphormer: This is the offici ...
- 消息队列面试题、RabbitMQ面试题、Kafka面试题、RocketMQ面试题 (史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- Kubernetes集群安装
一.环境介绍 主机名 IP地址 master 192.168.0.100 node1 192.168.0.101 node2 192.168.0.102 1.1.操作系统: CensOS8.4.210 ...
- 小Z的袜子(hose) &&作业 (莫队)
莫队:一种非常优雅的暴力,时间复杂度一般情况下是n*根号n,还是很优秀的. 今天水了三道莫队题,对普通莫队有了些了解 1.莫队l和r为指针,维护当前区间的某些信息,一般可以是当前区间不同权值的个数,( ...
- NOIP模拟测试14「旋转子段·走格子·柱状图」
旋转子段 连60分都没想,考试一直肝t3,t2,没想到t1最简单 我一直以为t1很难,看了题解发现也就那样 题解 性质1 一个包含a[i]旋转区间值域范围最多为min(a[i],i)----max(a ...
- go语言结构体内存对齐
cpu要想从内存读取数据,需要通过地址总线,把地址传输给内存,内存准备好数据,输出到数据总线,交给cpu,如果地址总线只有8根,那这个地址就只有8位可以表示[0,255]256个地址,因为表示不了更多 ...
- 2.QT浏览器控件设置“透明颜色”
使用样式表或者设置背景颜色,使用 background-color:transparent 但,使用透明的颜色是不可行的: QColor(255,0,0,0)