kafka Auto offset commit faild reblance
今天在使用python消费kafka时遇到了一些问题, 特记录一下。
场景一、
特殊情况: 单独写程序只用来生产消费数据
开始时间: 10:42
Topic: t_facedec
Partition: 1
程序启动: 168 启动consumer, 158启动consumer, windows机器producer推数据
运行时长: 15分钟
结果:
1、168的consume暂停,158的consumer一直消费
2、10:46分producer停止后重启推数, 158停止消费又开始消费
3、10:49分停止168、158的consumer并按顺序重启, 168消费一些数据之后158开始一直消费
4、后启动的consumer在消费数据
场景二、
特殊场景: 上线程序, 包含人脸识别处理
开始时间: 11:00
Topic: t_facedec
Partition: 1
1、11:46 启动168的conumer消费, 6分钟后日志如下, 未见异常信息
场景二、
特殊场景: 上线程序, 包含人脸识别处理
开始时间: 11:00
Topic: t_facedec
Partition: 1
1、11:46 启动168的conumer消费, 6分钟后日志如下, 未见异常信息
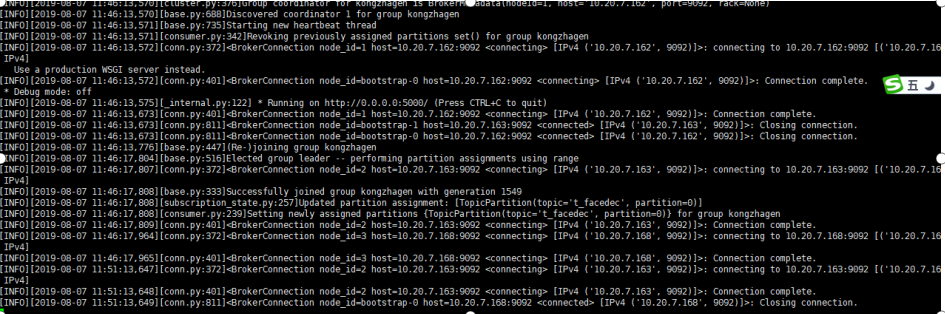
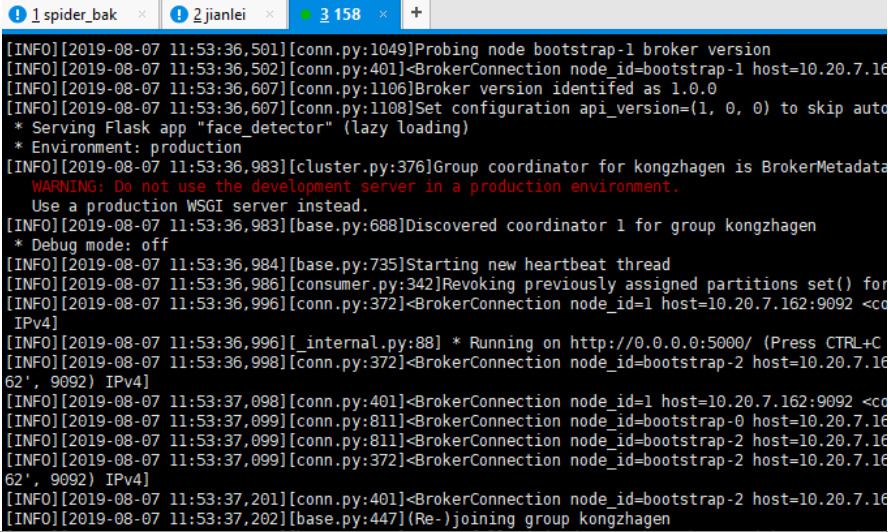
2、 11:53启动158的consumer, 日志如下, 未见异常, 158的consumer加入了组kongzhagen

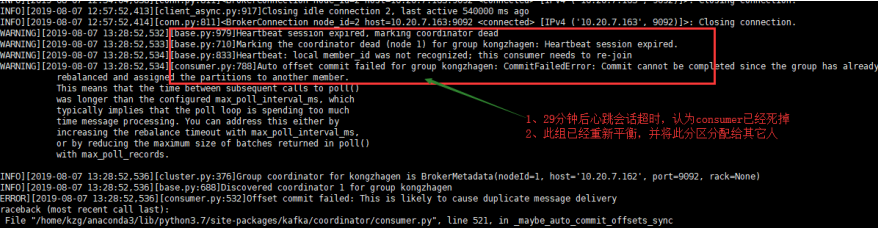
3、168的consumer发出警告, 心跳失败,因组正在重新平衡

4、windows端启动producer, 168的consumer开始消费数据, 158的consumer没有消费数据
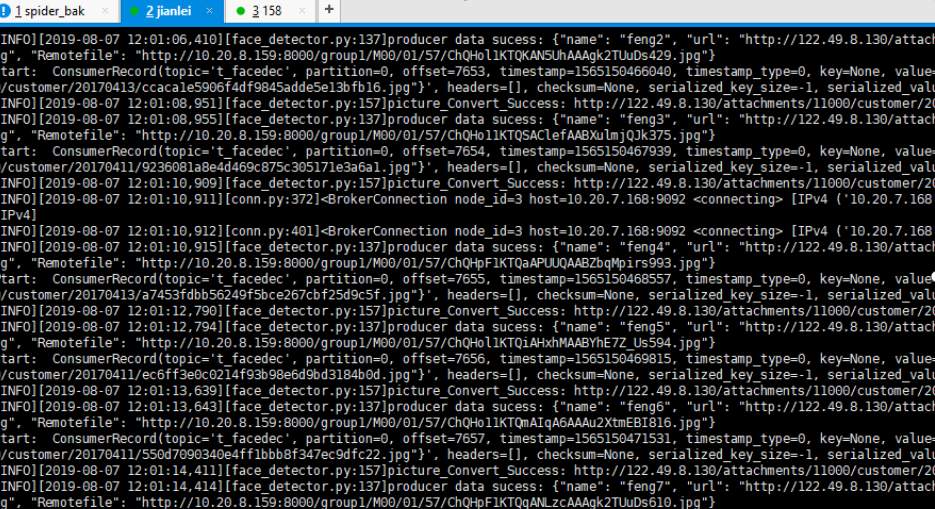
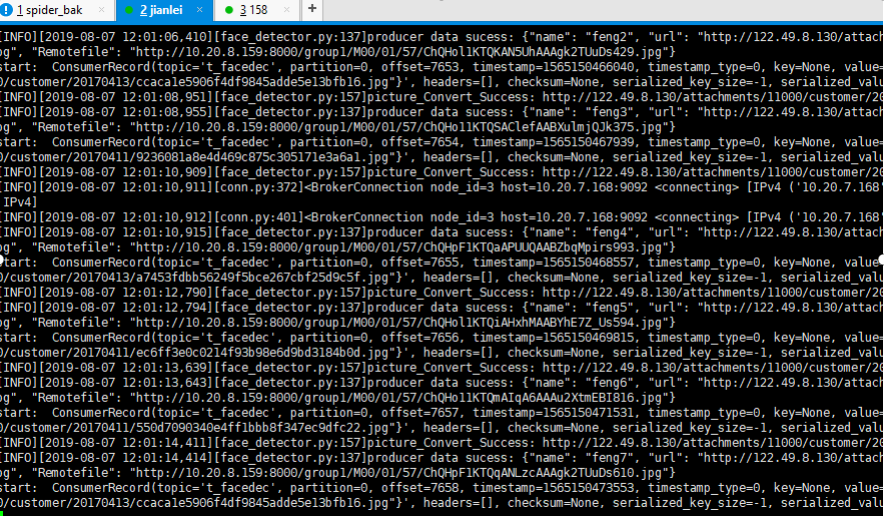
结论: 先启动的consumer会消费数据, 168的consumer关闭后, 158的consumer开始消费
5、半小时后
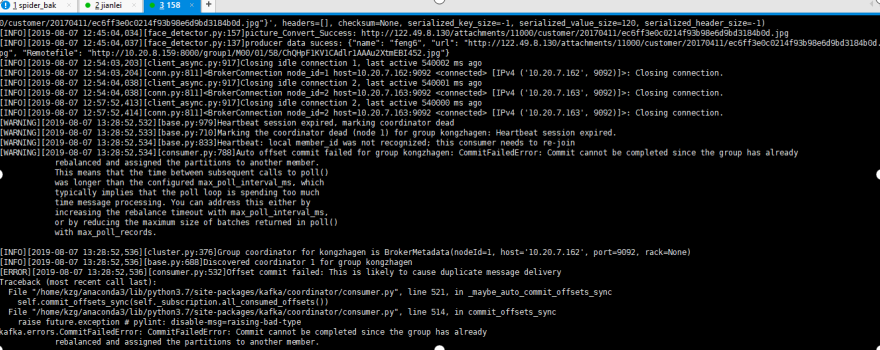
分解错误图:
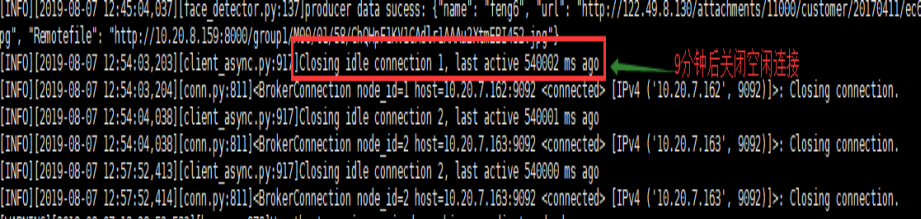
9分钟后空连接时间到'connections_max_idle_ms': 540000,
'max_poll_records': 500, 'heartbeat_interval_ms': 3000, 'session_timeout_ms': 30000,
后续:
14:32开始继续生产数据, 数据开始被消费

14:48分再次出现平衡超时

15:02分再次出现平衡超时

原因分析:
1、引起timeout的原因是consumer每3秒触发一次心跳, 由于某种原因在30秒内协调者没有收到此consumer的心跳信息, 认为此consumer已经死掉,topic内的分区在group的成员间重新分配(reblance)
2、默认consumer的每次最大poll数据量为500, 如果处理这500条记录的时候超过了最大时间间隔max_poll_interval_ms, consumer也会退出group, 导致reblance的产生
3、如果consumer没有产生消费行为的时间超过最大值connections_max_idle_ms:540000 (9 min)时, 也会导致consumer退出该组。
解决方法:
1、增加心跳会话超时间隔
session_timeout_ms = 300000(从30改为300秒)
2、减少每次获取任务的数量
max_poll_records = 5(从500改为5)
3、增加空闲连接时间
connections_max_idle_ms=5400000(从9min改为90min)
kafka Auto offset commit faild reblance的更多相关文章
- kafka auto.offset.reset参数解析
kafka auto.offset.reset参数解析 1.latest和earliest区别 2.创建topic 3.生产数据和接收生产数据 4.测试代码 auto.offset.reset关乎ka ...
- Kafka auto.offset.reset
要从头消费kafka的数据,可以通过以下参数: Kafka auto.offset.reset = earliest
- kafka之consumer参数auto.offset.reset 0.10+
https://blog.csdn.net/dingding_ting/article/details/84862776 https://blog.csdn.net/xianpanjia4616/ar ...
- kafka的auto.offset.reset详解与测试
1. 取值及定义 auto.offset.reset有以下三个可选值: latest (默认) earliest none 三者均有共同定义: 对于同一个消费者组,若已有提交的offset,则从提交的 ...
- kafka的offset相关知识
Offset存储模型 由于一个partition只能固定的交给一个消费者组中的一个消费者消费,因此Kafka保存offset时并不直接为每个消费者保存,而是以 groupid-topic-partit ...
- 「Kafka」Kafka中offset偏移量提交
在消费Kafka中分区的数据时,我们需要跟踪哪些消息是读取过的.哪些是没有读取过的.这是读取消息不丢失的关键所在. Kafka是通过offset顺序读取事件的.如果一个消费者退出,再重启的时候,它知道 ...
- kafka主题offset各种需求修改方法
简要:开发中,常常因为需要我们要认为修改消费者实例对kafka某个主题消费的偏移量.具体如何修改?为什么可行?其实很容易,有时候只要我们换一种方式思考,如果我自己实现kafka消费者,我该如何让我们的 ...
- Kafka提交offset机制
在kafka的消费者中,有一个非常关键的机制,那就是offset机制.它使得Kafka在消费的过程中即使挂了或者引发再均衡问题重新分配Partation,当下次重新恢复消费时仍然可以知道从哪里开始消费 ...
- kafka_2.11-0.10.2.1中的auto.offset.reset
在使用spark连接kafka消费topic时,发现无论怎么设置,也无法从头开始消费. 查看配置得出auto.offset.reset的以下3种设置及含义: earliest 当各分区下有已提交的of ...
随机推荐
- Js学习03--数据类型
一.数据类型 1.Js中常用的数据类型 简单数据类型 Number 数字类型 String 字符串类型 Boolean 布尔类型 Undefined 变量未初始化 Null 空类型 复杂数据 ...
- eclipse 无法启动,JAVA_HOME 失效
主要是因为JDK和eclipse 版本不兼容导致的,4位jdk配64位eclipse,32位jdk配32位eclipse; Java 设置JAVA_HOME无效 其根本原因是%JAVA_HOME%在p ...
- java程序员必须熟悉的一些操作
1.mysql数据库服务启动命令 /etc/init.d/mysqld start --启动命令 mysql数据库安装方法参考 http://www.blogja ...
- .net core web API使用Identity Server4 身份验证
一.新建一个.net core web项目作为Identity server 4验证服务. 选择更改身份验证,然后再弹出的对话框里面选择个人用户账户. nuget 安装Identity server相 ...
- C# vb .net实现gamma伽玛调整特效滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的gamma伽玛调整特效滤镜呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: ...
- Computational biological hypothesis generation using "-omics" data
Computational biological hypothesis generation using "-omics" data Forming biological hypo ...
- 定时任务 Quarzt
Quartz.Net是一个从java版的Quartz移植过来的定时任务框架,可以实现异常灵活的定时任务. Quartz 有三个概念分别是 计划者(ISchedeler).工作(IJob).触发器(Tr ...
- HTML学习摘要2
DAY 2 HTML 标签可以拥有属性.属性提供了有关 HTML 元素的更多的信息. 属性总是以名称/值对的形式出现,比如:name="value". 属性总是在 HTML 元素的 ...
- C++线程同步之事件
题目要求:点击抢红包后,先将第一个编辑框的值设置为1000,然后创建三个线程,让右边的编辑框值依次设置为1000(用事件完成) // MutexExDlg.h : 头文件 // #pragma onc ...
- Jmeter学习笔记(十三)——xpath断言
1.什么是XPath断言 XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言.XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力. Ap ...