[Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一、介绍
本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
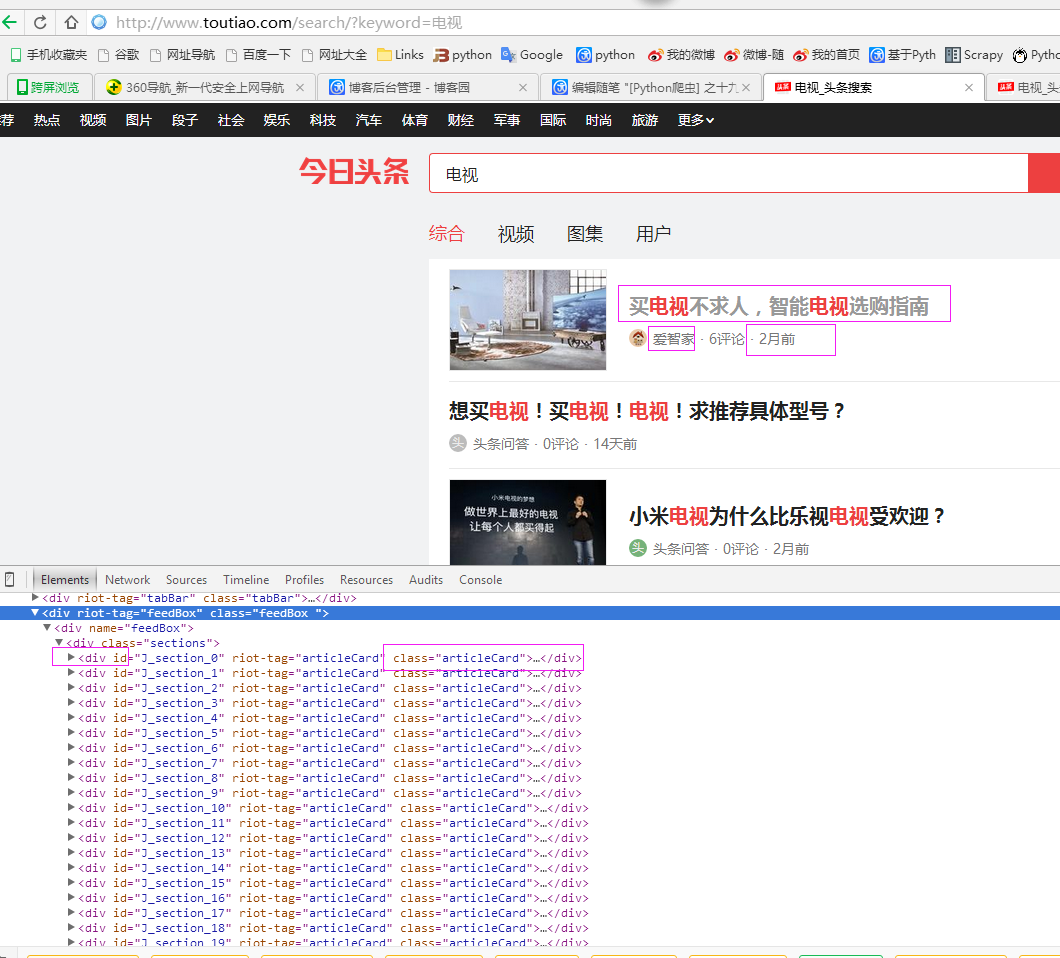
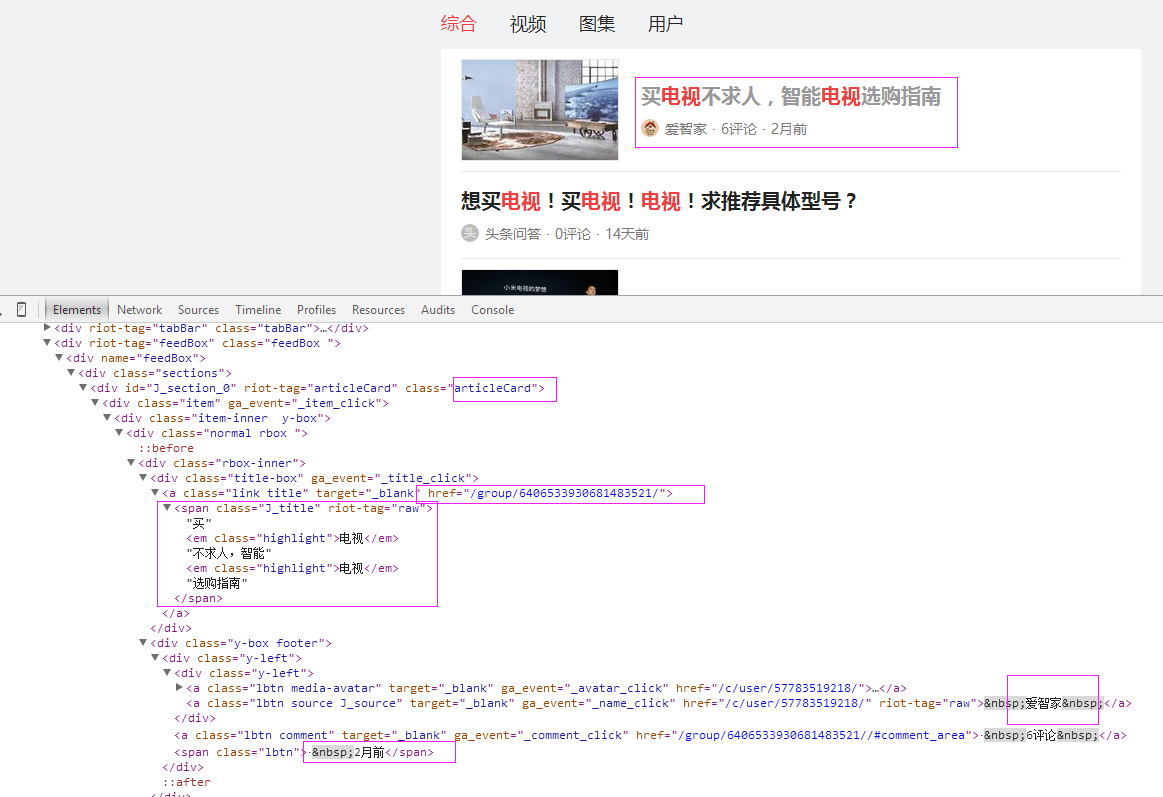
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="articleCard"]')
2、抓取标题
抓取代码:title = element('a[class="link title"]').find('span').text().encode('utf8').replace(' ', '')
3、抓取链接
抓取代码:url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
4、抓取日期
抓取代码:strdate = element('span[class="lbtn"]').text().encode('utf8').strip()
5、抓取来源
抓取代码:source = element('a[class="lbtn source J_source"]').text().encode('utf8').replace(' ', '')
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from datetime import datetime
import IniFile
# from threading import Thread
from pyquery import PyQuery as pq
import LogFile
import mongoDB
import urllib
class toutiaoSpider(object):
def __init__(self): logfile = os.path.join(os.path.dirname(os.getcwd()), time.strftime('%Y-%m-%d') + '.txt')
self.log = LogFile.LogFile(logfile)
configfile = os.path.join(os.path.dirname(os.getcwd()), 'setting.conf')
cf = IniFile.ConfigFile(configfile)
webSearchUrl = cf.GetValue("toutiao", "webSearchUrl")
self.keyword_list = cf.GetValue("section", "information_keywords").split(';')
self.db = mongoDB.mongoDbBase()
self.start_urls = [] for word in self.keyword_list:
self.start_urls.append(webSearchUrl + urllib.quote(word)) self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.driver, 2)
self.driver.maximize_window() def scroll_foot(self):
'''
滚动条拉到底部
:return:
'''
js = ""
# 如何利用chrome驱动或phantomjs抓取
if self.driver.name == "chrome" or self.driver.name == 'phantomjs':
js = "var q=document.body.scrollTop=10000"
# 如何利用IE驱动抓取
elif self.driver.name == 'internet explorer':
js = "var q=document.documentElement.scrollTop=10000"
return self.driver.execute_script(js) def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
if strDateText.find('分钟前') > 0 or strDateText.find('刚刚') > -1:
return True, currentDate
elif strDateText.find('小时前') > 0:
datePattern = re.compile(r'\d{1,2}')
ch = int(time.strftime('%H')) # 当前小时数
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if int(strDate[0]) <= ch: # 只有小于当前小时数,才认为是今天
return True, currentDate
return False, '' def log_print(self, msg):
'''
# 日志函数
# :param msg: 日志信息
# :return:
# '''
print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg) def scrapy_date(self):
strsplit = '------------------------------------------------------------------------------------'
index = 0
for link in self.start_urls:
self.driver.get(link) keyword = self.keyword_list[index]
index = index + 1
time.sleep(1) #数据比较多,延迟下,否则会出现查不到数据的情况 selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = []
self.log.WriteLog(strsplit)
self.log_print(strsplit) Elements = doc('div[class="articleCard"]') for element in Elements.items():
strdate = element('span[class="lbtn"]').text().encode('utf8').strip()
flag, date = self.date_isValid(strdate)
if flag:
title = element('a[class="link title"]').find('span').text().encode('utf8').replace(' ', '')
if title.find(keyword) > -1:
url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
source = element('a[class="lbtn source J_source"]').text().encode('utf8').replace(' ', '') dictM = {'title': title, 'date': date,
'url': url, 'keyword': keyword, 'introduction': title, 'source': source}
infoList.append(dictM)
# self.log.WriteLog('title:%s' % title)
# self.log.WriteLog('url:%s' % url)
# self.log.WriteLog('source:%s' % source)
# self.log.WriteLog('kword:%s' % keyword)
# self.log.WriteLog(strsplit) self.log_print('title:%s' % dictM['title'])
self.log_print('url:%s' % dictM['url'])
self.log_print('date:%s' % dictM['date'])
self.log_print('source:%s' % dictM['source'])
self.log_print('kword:%s' % dictM['keyword'])
self.log_print(strsplit) if len(infoList)>0:
self.db.SaveInformations(infoList) self.driver.close()
self.driver.quit() obj = toutiaoSpider()
obj.scrapy_date()
[Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据的更多相关文章
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- [Python爬虫] 之十九:Selenium +phantomjs 利用 pyquery抓取超级TV网数据
一.介绍 本例子用Selenium +phantomjs爬取超级TV(http://www.chaojitv.com/news/index.html)的资讯信息,输入给定关键字抓取资讯信息. 给定关键 ...
- [Python爬虫] 之二十四:Selenium +phantomjs 利用 pyquery抓取中广互联网数据
一.介绍 本例子用Selenium +phantomjs爬取中广互联网(http://www.tvoao.com/select.html)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
随机推荐
- 给tomcat单独配置jdk
在catalina 文件 加这句话,前面加 export JAVA_HOME=/home/apache-tomcat-8.5.8/jdk1.8.0_101
- python 多进程锁Lock和共享内存
多进程锁 lock = multiprocessing.Lock() 创建一个锁 lock.acquire() 获取锁 lock.release() 释放锁 with lock: 自动获取.释放锁 类 ...
- vCard
vCard 在翻阅dottoro的时候,在附录(appendix)的js部分,注意到一个叫vCard的部分,能单独列出来,可能是比较重要的,至少是比较独立的部分,但是以前从未听说或者了解过这一部分,如 ...
- FluentValidation具体使用案例
可以使用NuGet 添加类库 下面是程序: using FluentValidation; using System; using System.Linq; namespace TestFluen ...
- C++类中引用成员和常量成员的初始化(初始化列表)
如果一个类是这样定义的: Class A { public: A(int pram1, int pram2, int pram3); privite: int a; int &b; const ...
- selenium 截图 添加时间戳
在自动化程序中运行的代码报错信息或者是相关日志有可能并无法直观的判断出错信息.因此截图是避免不了的.为了避免因为重复运行或者是图片名称相同导致截图被覆盖. 建议在截图时使用时间戳,保证截图图片名称的唯 ...
- JSONObject常用的API
http://www.cnblogs.com/java-pan/archive/2012/04/07/jsonobject.html 1.介绍基于JSONObject 1.1的API 2.只介绍常用的 ...
- Jquery EasyUI选项卡-Tabs的使用方法
以下是easyUI的tabs的简单实用介绍. var e =$('#main').tabs('exists','accordion'); if(e==true){ $('#main').tabs(' ...
- openssl生成证书链多级证书
操作系统CentOS6.6 注:windows版本的Openssl无法做这个实验,由于所有编译的window版本openssl没有对openssl目录重新定向,导致在windows下找不到pki目录 ...
- 大数据DMP画像系统(转载 简介-龙果学院)
一.目标 1.掌握画像标签开发技巧 2.掌握数据挖掘技巧 3.了解业内画像和DMP系统的架构和开发 4.大数据结合业务场景落地 系统开发要求 涉及的技术要点:spark .elasticsearch. ...