[Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一、介绍
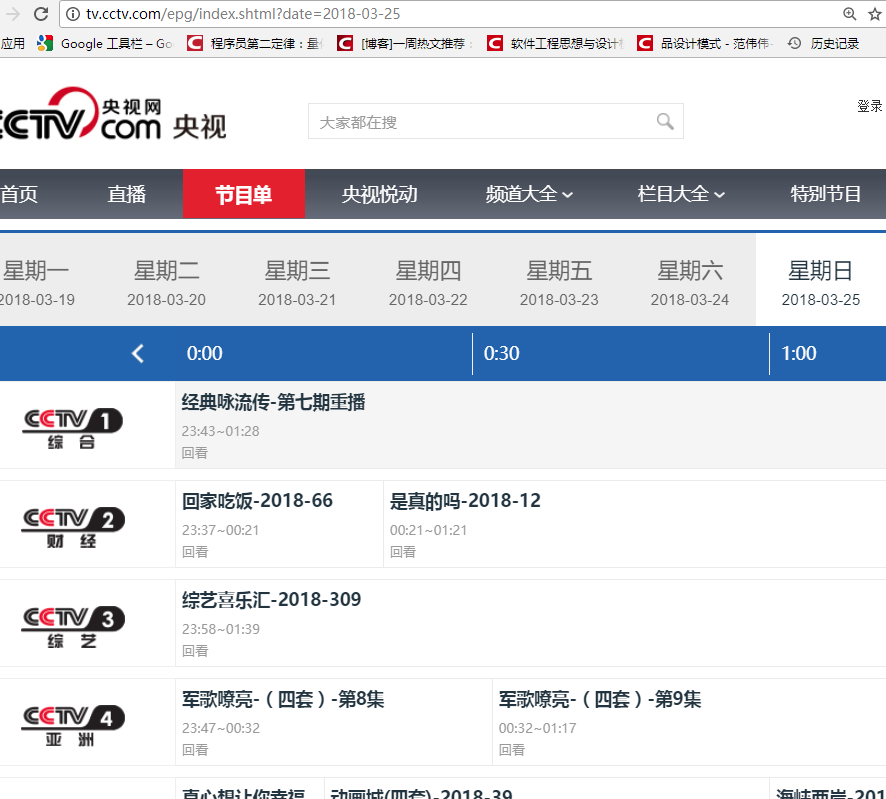
本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息
二、网站信息
三、数据抓取
针对上面的网站信息,来进行抓取
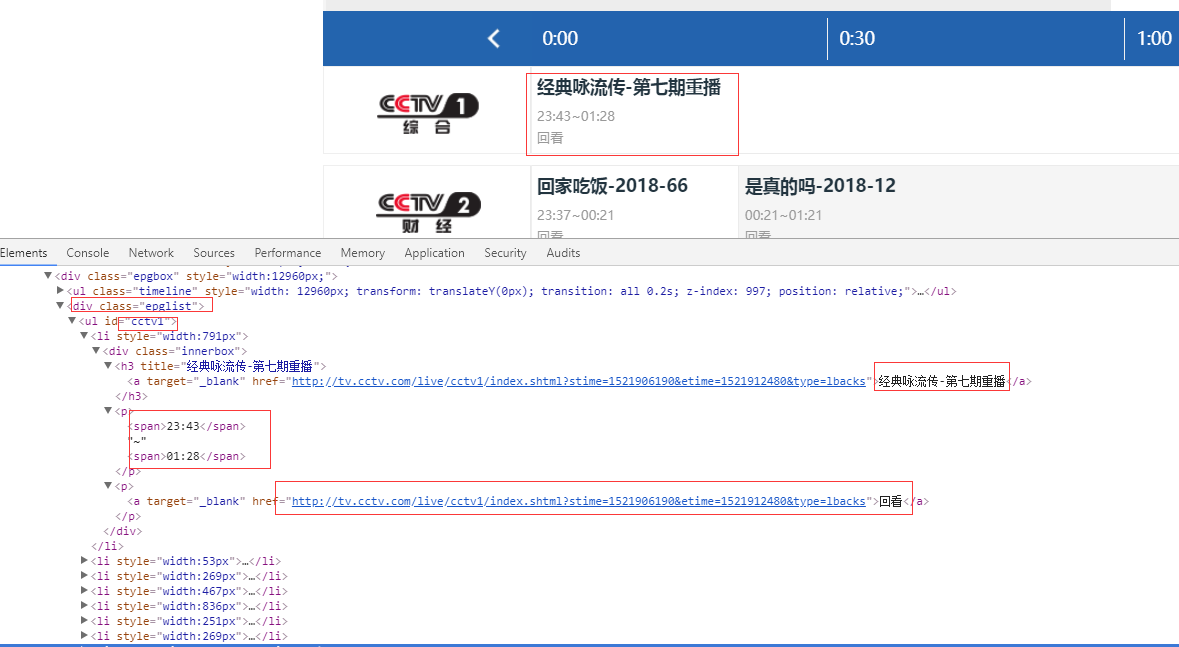
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="epglist"]').find('ul')
2、节目名称,链接,时间
title = subEle('div[class="innerbox"]').find('h3').text().encode('utf8')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8')
四,实现代码
# coding=utf-8
import os
import re
from selenium import webdriver
from datetime import datetime,timedelta
import selenium.webdriver.support.ui as ui
import time
from pyquery import PyQuery as pq
class cctvDriver: def __init__(self,startDate,endDate):
#通过配置文件获取IEDriverServer.exe路径
self.urls = self.getUrlsFromStartEndDate(startDate,endDate)
IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
self.driver = webdriver.Ie(IEDriverServer)
self.driver.maximize_window()
self.fileName = time.strftime('%Y-%m-%d') def compareDate(self, startDate, endDate):
start_Date = time.strptime(startDate, "%Y-%m-%d")
end_Date = time.strptime(endDate, "%Y-%m-%d")
totalSeconds = (end_Date - start_Date).total_seconds()
if totalSeconds >= 0:
print endDate
return True
else:
print startDate
return False def compareTime(self, startTime, endTime):
st = int(startTime.replace(':',""))
et = int(endTime.replace(':',""))
if st>et:
return True
else:
return False def getUrlsFromStartEndDate(self,startDate,endDate): urls = []
start_Date = datetime.strptime(startDate, "%Y-%m-%d")
end_date = datetime.strptime(endDate, "%Y-%m-%d")
ts = end_date-start_Date days = ts.days + 1
index = 0
for d in xrange(0,days):
date = start_Date + timedelta(days=index)
urls.append('http://tv.cctv.com/epg/index.shtml?date='+date.strftime("%Y-%m-%d"))
index += 1
return urls def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'cctvInfo/'+date + '.txt')
with open(fileName, 'a') as f:
f.write(message) def CatchData(self):
className = "//div[@class='epglist']/ul"
for url in self.urls:
date = url.split('=')[1]
start_Date = datetime.strptime(date, "%Y-%m-%d") + timedelta(days=-1)
predate = start_Date.strftime("%Y-%m-%d")
self.driver.get(url)
time.sleep(5)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
Elements = doc('div[class="epglist"]').find('ul')
message = ''
recount = 0
for element in Elements.items():
channel = element.attr('id')
subElements = element.find("li") for subEle in subElements.items():
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8').strip().replace(
'回看', '').replace('直播','')
if strTime:
title = subEle('div[class="innerbox"]').find('h3').text().encode(
'utf8').strip().replace(
',', ',')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
if self.compareTime(strTime.split('~')[0],strTime.split('~')[1]):
starttime = predate + " " + strTime.split('~')[0]
else:
starttime = date + " " + strTime.split('~')[0]
endtime = date + " " + strTime.split('~')[1] mess = '\r\n{0},{1},{2},{3},{4}'.format(channel, title, starttime, endtime, link)
# print mess
message += mess
recount+=1
if len(message)>10:
self.WriteLog(message.strip(),date)
print recount
self.driver.close()
self.driver.quit() # #测试抓取微博数据
obj = cctvDriver('2018-01-01','2018-03-01')
obj.CatchData()
[Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息的更多相关文章
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- shell读取nginx配置文件中nginx的端口
#!/bin/shport=`nl /usr/local/openresty/nginx/conf/nginx.conf | sed -n '/listen/p' | awk 'NR==1{print ...
- 解决错误:此用户名包含无效字符,请输入有效的用户名。wordpress不能注册中文用户名的问题
wordpress在默认情况下不支持中文用户名,就是在后台添加用户的时候,如果用户名包含中文,则显示”错误:此用户名包含无效字符,请输入有效的用户名.”如何解决这个问题呢? 不用插件的话就需要修改一个 ...
- Eclipse中快速 打出 main方法的签名
有时,我们创建一个空白类,需要打出main方法 public static void main(String [] args){ } 在Eclipse先敲main字符,然后按住ALT+/,再按回车即可 ...
- Trie树【UVA11362】Phone List
Description 给定\(n\)个长度不超过\(10\)的数字串,判断是否有两个字符串\(A\)和\(B\),满足\(A\)是\(B\)的前缀,若有,输出NO,若没有,输出YES. 一道\(Tr ...
- 3000大洋,自己配置i5主机
自用的HP笔记本已经“七年之痒”了,所以在2016年新年之前,换了台新电脑.主要用来娱乐(电影),但是也要能够满足工作学习(本人从事IT行业)的需要. 遵循本人一贯的高冷装X的习惯,决定自己买配件攒机 ...
- Redux 和 Redux thunk 理解
1: state 就像 model { todos: [{ text: 'Eat food', completed: true }, { text: 'Exercise', completed: fa ...
- Mixins 改成使用高阶组件调用
把组件放在另外一个组件的 render 方法里面, 并且利用了 {...this.props} {...this.state} 这些 JSX 展开属性 对比下2种代码: 原始方式: <!DOC ...
- Java 线程池的实现
http://blog.csdn.net/iterzebra/article/details/6758481 http://blog.sina.com.cn/s/blog_4914a33b010118 ...
- ASP.NET总结——更改后
这篇重新整理的总结,我做了很久,也在草稿箱中放了很久,一直感觉没有达到和老师谈话后的水平,感觉还是需要增加一些修改,希望读者能提出宝贵意见.既这篇博客之前,我发表了一篇ASP.net的总结,在结构上, ...
- 20162318 2016-2017-2《Java程序设计》课堂实践项目
20162318 2016-2017-2<Java程序设计>课堂实践项目 String类的使用 在String类中有一种split的方法.它可以把字符串分割为好几个小的字符串. 实践内容: ...