Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14

这是简易数据分析系列的第 14 篇文章。
今天我们还来聊聊 Web Scraper 翻页的技巧。
这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之前介绍的分页器翻页方法不管用。我研究了一下才发现我漏讲了一种很常见的翻页场景。
在 web scraper 翻页——分页器翻页的文章里,我们讲了如何利用 Element Click 选择器模拟鼠标点击分页器进行翻页,但是把同样的方法放在豆瓣 TOP 250 上,翻页到第二页时抓取窗口就会自动退出,一条数据都抓不到。
其实主要原因是我没有讲清楚这种方法的适用边界。
通过 Element Click 点击分页器翻页,只适用于网页没有刷新的情况,我在分页器那篇文章里举了蔡徐坤微博评论的例子,翻页时网页是没有刷新的:
仔细看下图,链接发生了变化,但是刷新按钮并没有变化,说明网页并没有刷新,只是内容变了

而在 豆瓣 TOP 250 的网页里,每次翻页都会重新加载网页:
仔细看下图,链接发生变化的同时网页刷新了,有很明显的 loading 转圈动画

其实这个原理从技术规范上很好解释:当一个 URL 链接是 # 字符后数据变化时,网页不会刷新;当链接其他部分变化时,网页会刷新。当然这个只是随口提一下,感兴趣的同学可以去这个链接研究一下,不感兴趣可以直接跳过。
1.创建 Sitemap
本篇文章就来讲解一下,如何利用 Web Scraper 抓取翻页时会刷新网页的分页器网站。
这次的网页我们选用最开始练手 Web Scraper 的网站——豆瓣电影 TOP250,换个姿势练习 Web Scraper 翻页技巧。
像这种类型的网站,我们要借助 Link 选择器来辅助我们翻页。Link 标签我们在上一节介绍过了,我们可以利用这个标签跳转网页,抓取另一个网页的数据。这里我们利用 Link 标签跳转到分页网站的下一页。
首先我们用 Link 选择器选择下一页按钮,具体的配置可以见下图:
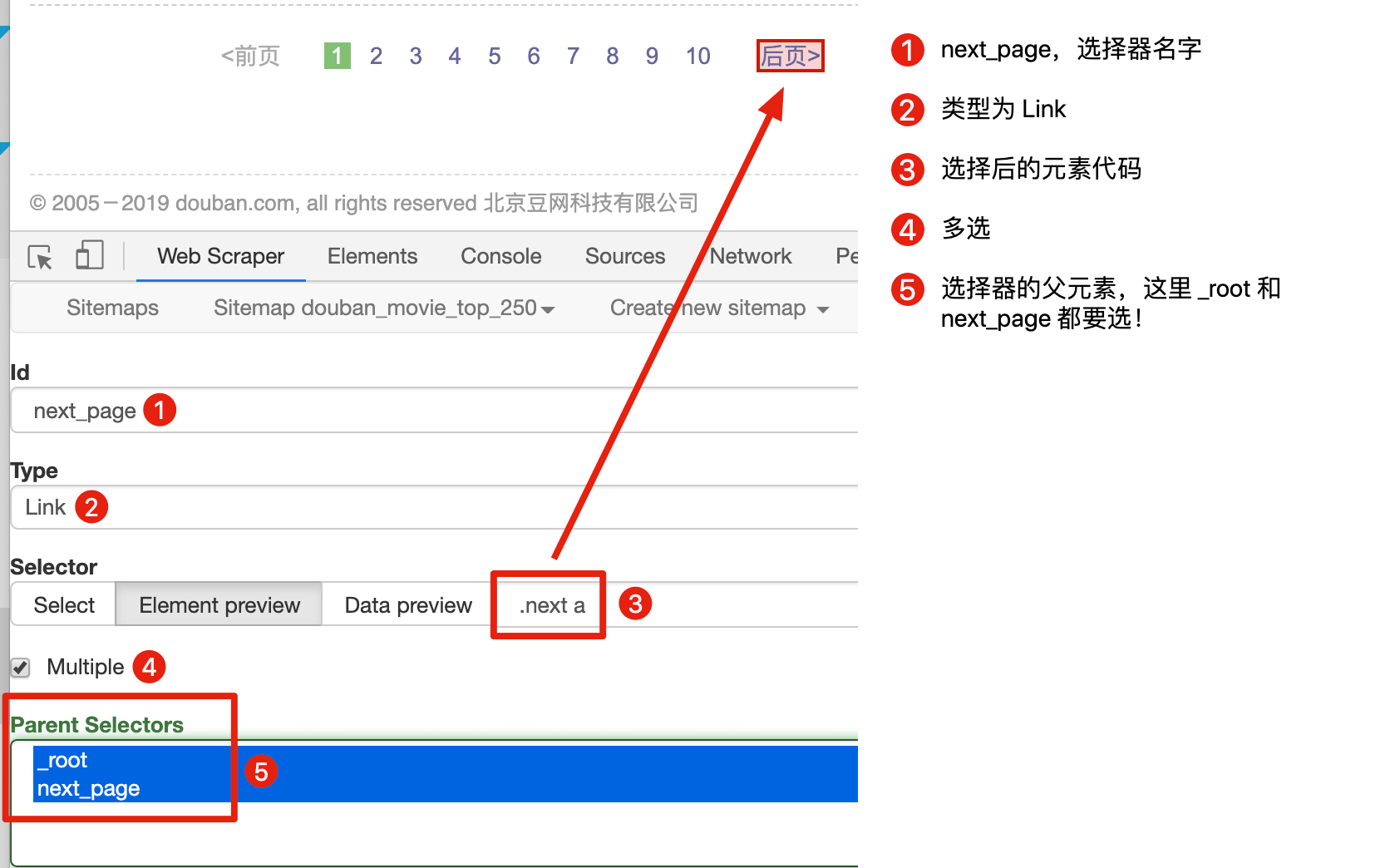
这里有一个比较特殊的地方:Parent Selectors ——父选择器。
之前我们都没有碰过这个选择框的内容,next_page 这次要有两个父节点——_root 和 next_page,键盘按 shift 再鼠标点选就可以多选了,先按我说的做,后面我会解释这样做的理由。
保存 next_page 选择器后,在它的同级下再创建 container 节点,用来抓取电影数据:
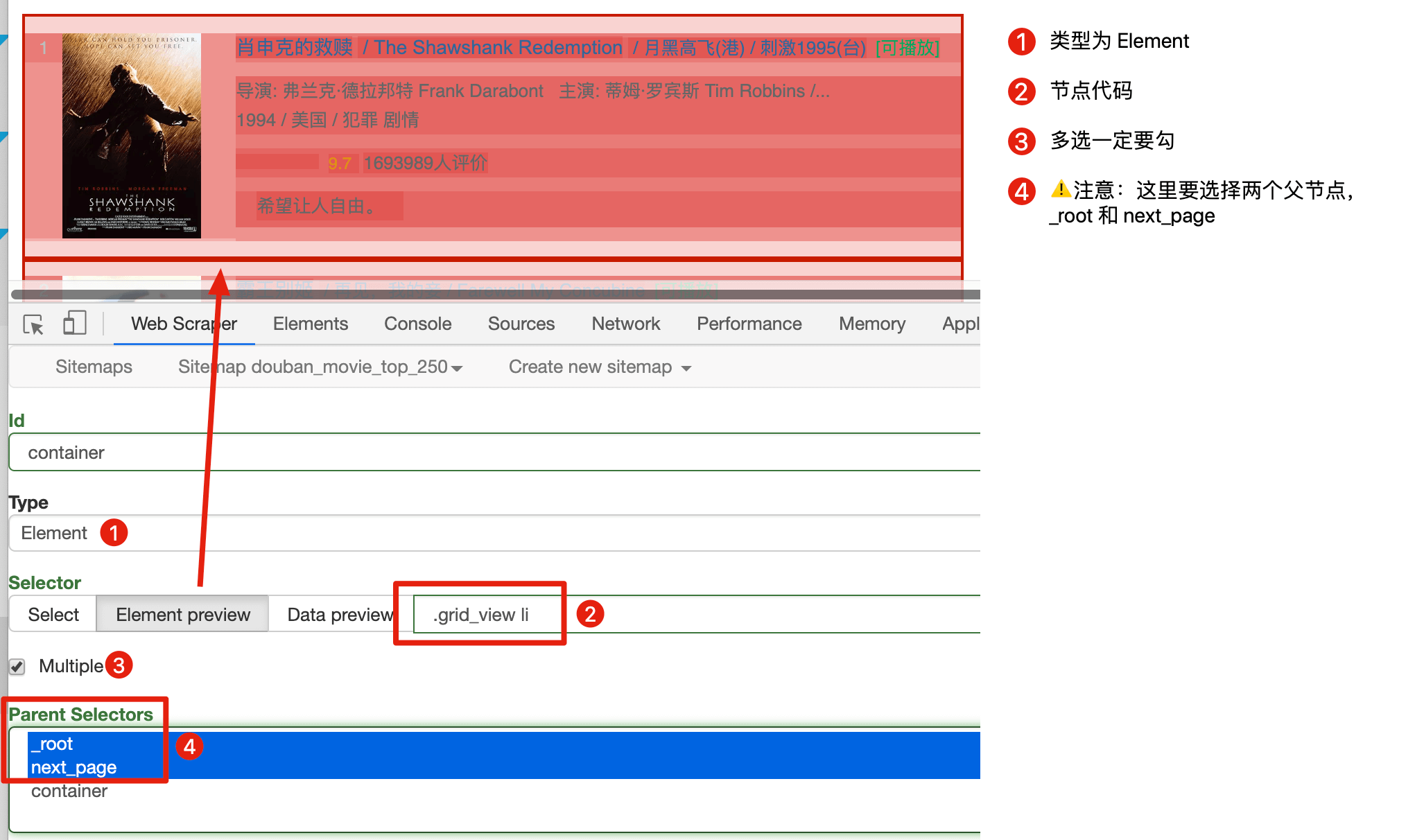
这里要注意:翻页选择器节点 next_page 和数据选择器节点 container 是同一级,两个节点的父节点都是两个:_root 和 next_page:

因为重点是 web scraper 翻页技巧,抓取的数据上我只简单的抓取标题和排名:

然后我们点击 Selector graph 查看我们编写的爬虫结构:
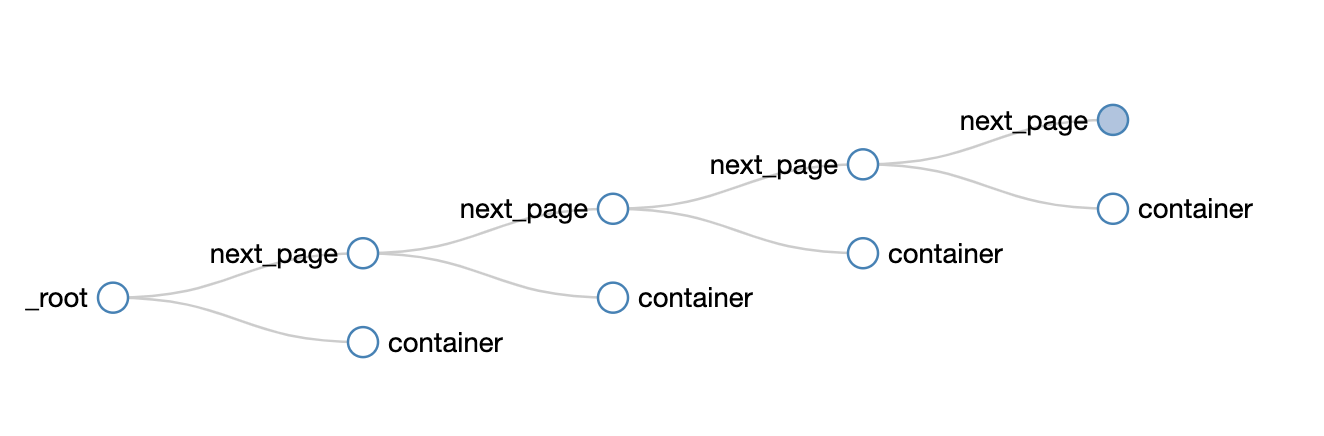
可以很清晰的看到这个爬虫的结构,可以无限的嵌套下去:
点击 Scrape,爬取一下试试,你会发现所有的数据都爬取下来了:
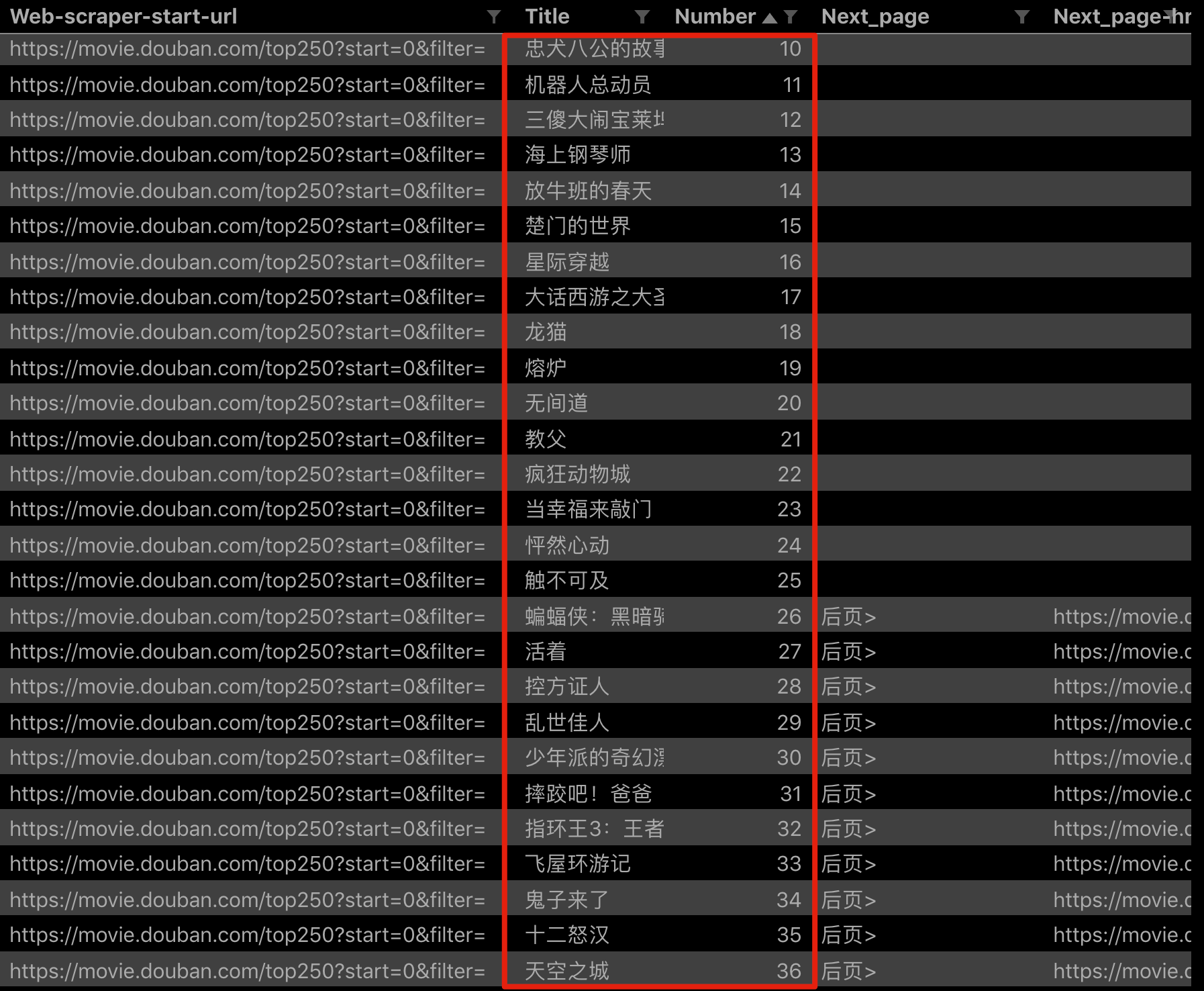
2.分析原理
按照上面的流程下来,你可能还会比较困扰,数据是抓下来了,但是为什么这样操作就可以呢,为什么 next_page 和 container 要同级,为什么他们要同时选择两个父节点:_root 和 next_page?
产生困扰的原因是因为我们是倒叙的讲法,从结果倒推步骤;下面我们从正向的思维分步讲解。
首先我们要知道,我们抓取的数据是一个树状结构,_root 表示根节点,就是我们的抓取的第一个网页,我们在这个网页要选择什么东西呢?
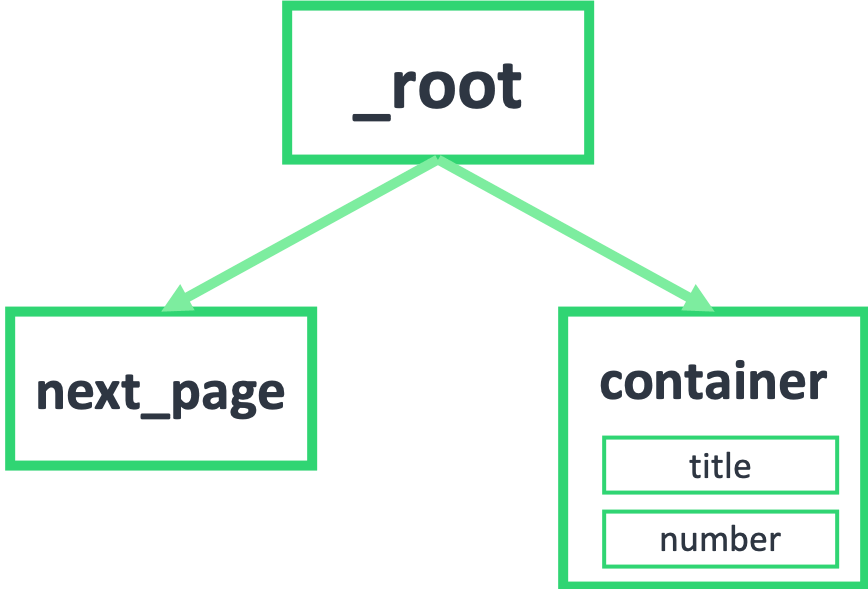
1.一个是下一页的节点,在这个例子里就是用 Link 选择器选择的 next_page
2.一个是数据节点,在这个例子里就是用 Element 选择器选择的 container
因为 next_page 节点是会跳转的,会跳到第二页。第二页除了数据不一样,结构和第一页还是一样的,为了持续跳转,我们还要选择下一页,为了抓取数据,还得选择数据节点:
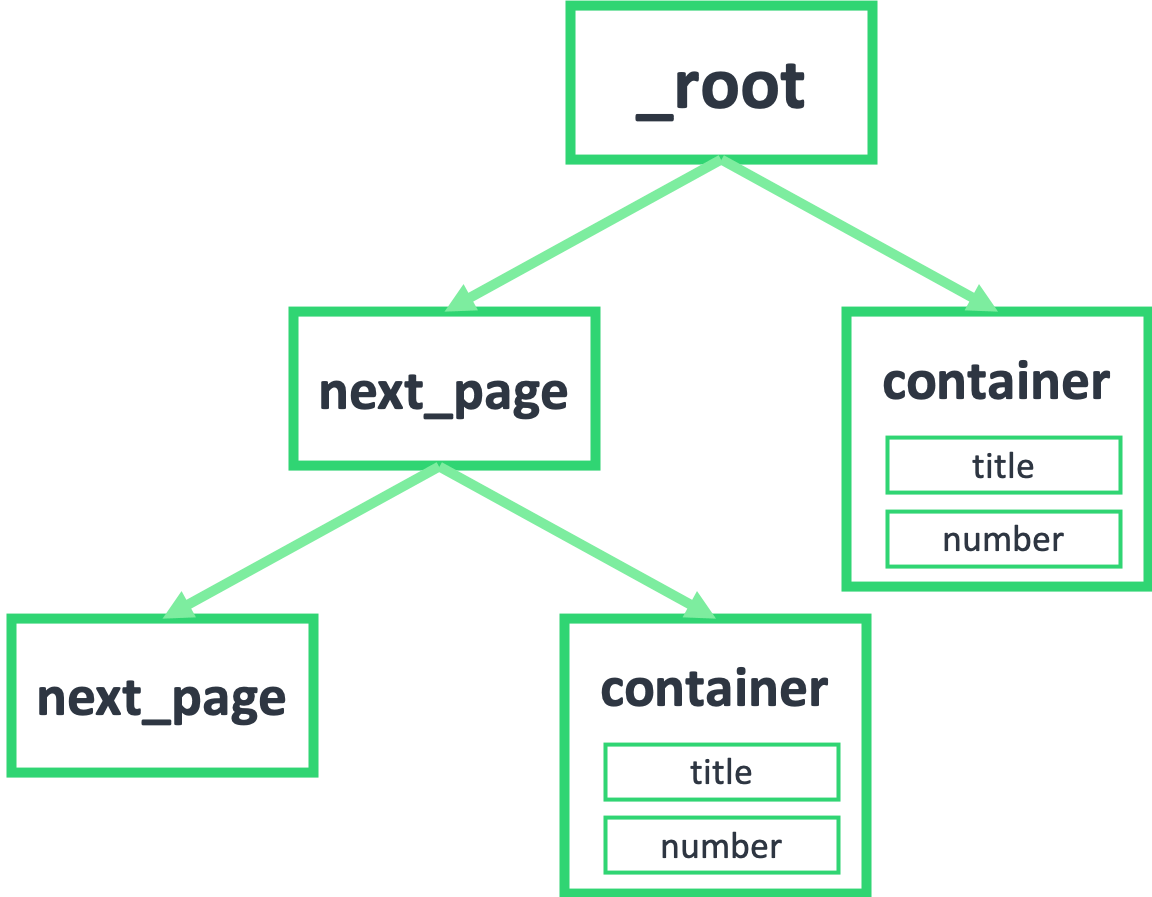
如果我们把箭头反转一下,就会发现真相就在眼前,next_page 的父节点,不正好就是 _root 和 next_page 吗?container 的父节点,也是 _root 和 next_page!
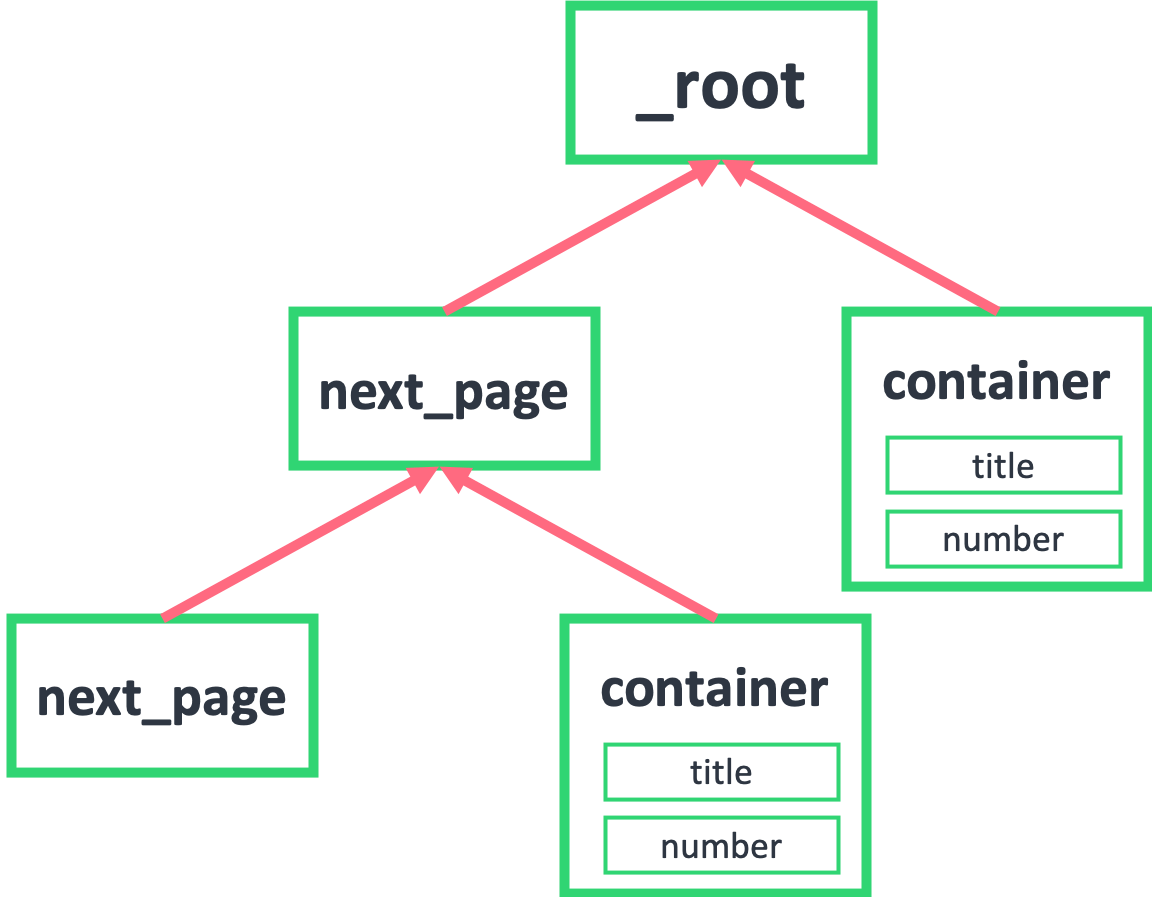
到这里基本就真相大白了,不理解的同学可以再多看几遍。像 next_page 这种我调用我自己的形式,在编程里有个术语——递归,在计算机领域里也算一种比较抽象的概念,感兴趣的同学可以自行搜索了解一下。
3.sitemap 分享
下面是这次实战的 Sitemap,同学们可以导入到自己的 web scraper 中进行研究:
{"_id":"douban_movie_top_250","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0}]}
4.推荐阅读
简易数据分析 05 | Web Scraper 翻页——控制链接批量抓取数据
简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
简易数据分析 13 | Web Scraper 高级用法——抓取二级页面
5.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。

Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14的更多相关文章
- Web Scraper 高级用法——利用正则表达式筛选文本信息 | 简易数据分析 17
这是简易数据分析系列的第 17 篇文章. 学习了这么多课,我想大家已经发现了,web scraper 主要是用来爬取文本信息的. 在爬取的过程中,我们经常会遇到一个问题:网页上的数据比较脏,我们只需要 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- web scraper
参考:https://sspai.com/u/skychx/updates https://www.jianshu.com/p/76cad8e963b5 :nth-of-type(-n+100) 元素 ...
- Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16
这是简易数据分析系列的第 16 篇文章. 这期课程我们讲一个用的较少的 Web Scraper 功能--抓取属性信息. 网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息.我们拿豆瓣电影 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
随机推荐
- OptimalSolution(5)--数组和矩阵问题(2)2
一.找到无序数组中最小的k个数 二.在数组中找到出现次数大于N/K的数 三.最长的可整合子数组的长度 四.不重复打印排序数组中相加和为给定值的所有二元组和三元组 五.未排序正数数组中累加和为给定值的最 ...
- stream流篇
流是C#中比较重要的一个概念,很多关键技术都需要用到流.何为流呢?可以理解流为江河中水的流动,不过C#中则为信息流,我们可以把信息写入流,也可以读出.比如以文件读写操作为例,首先以某种方式(如只读)打 ...
- SpringBoot整合Mybatisplus3.x之CRUD(一)
pom.xml <dependencies> <dependency> <groupId>org.springframework.boot</groupId& ...
- 6、pytest -- 临时目录和文件
目录 1. 相关的fixture 1.1. tmp_path 1.2. tmp_path_factory 1.3. tmpdir 1.4. tmpdir_factory 1.5. 区别 2. 默认的基 ...
- WebApi -用户登录后SessionId未更新
描工具检测出.net的程序有会话标识未更新这个漏洞 用户尚未登录时就有session cookie产生.可以尝试在打开页面的时候,让这个cookie过期.等到用户再登陆的时候就会生成一个新的sessi ...
- 为什么 Flutter 是跨平台开发的终极之选
跨平台开发是当下最受欢迎.应用最广泛的框架之一.能实现跨平台开发的框架也五花八门,让人眼花缭乱.最流行的跨平台框架有 Xamarin.PhoneGap.Ionic.Titanium.Monaca.Se ...
- maven项目部署到tomcat方法
今天记录下,maven项目部署到服务器的过程 1.首先在ide中里将自己的maven项目打包 mvn clean install 2. 看是否需要修改war包的名字,如果要修改,就用命令 mv xxx ...
- Appium的加载过程
appium运行流程 Appium的加载过程如上图. 1)调用Android adb完成基本的系统操作: 2)向Android上部署bootstrap.jar: 3)Bootstrap.jar For ...
- Pandas 分组聚合
# 导入相关库 import numpy as np import pandas as pd 创建数据 index = pd.Index(data=["Tom", "Bo ...
- 星空 题意转化,差分,状压DP
好题(爆搜和puts("2")一个分(雾)),不得不说思维真的强. 首先发现区间翻转很难受,考虑用差分(异或满足可逆性),注意是从0到n+1 然后就转化题意,操作改为选取距离为L的 ...