Hadoop之HDFS概述
一、HDFS产生背景及定义
1、HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2、HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
二、HDFS优缺点
1、优点
1)高容错性
a、数据自动保存多个副本。它通过增加副本的形式,提高容错性。

b、某个副本丢失以后,它可以自动恢复。

2)适合处理大数据
a、数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
b、文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性。
2、缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
a、存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
b、小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改。
a、一个文件只能有一个写,不允许多个线程同时写;
b、仅支持数据append(追加),不支持文件的随机修改。
三、HDFS架构组成
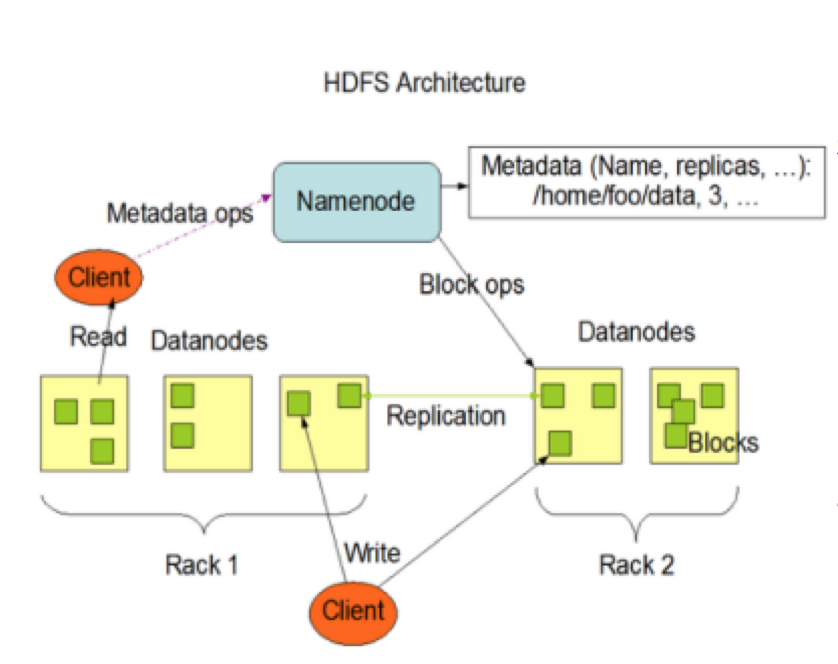
1、NameNode(nn):在整个集群中是Master,它是一个主管、管理者。
1)管理HDFS的名称空间;
2)配置副本策略
3)管理数据块(Block)映射信息
4)处理客户端读写请求
2、DataNode(dn):它是Slave,NameNode下达命令,DataNode执行实际的操作。
1)存储实际的数据块;
2)执行数据块的读/写操作
3、Client:客户端
1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
2)与NameNode交互,获取文件的位置信息
3)与DataNode交互,读取或者写入数据
4)Client提供一些命令来管理HDFS,比如NameNode格式化
5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
4、Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
2)在紧急情况下,可辅助恢复NameNode。
四、HDFS文件块大小
HDFS的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来设定,默认大小在Hadoop2.x版本中是128M,老版本中是64M。

思考:为什么块的大小不能设置太小,也不能设置太大?
1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需时间,导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
Hadoop之HDFS概述的更多相关文章
- Hadoop(5)-HDFS概述
HDFS产生背景 HDFS优缺点 HDFS组成架构 HDFS文件块大小
- C#、JAVA操作Hadoop(HDFS、Map/Reduce)真实过程概述。组件、源码下载。无法解决:Response status code does not indicate success: 500。
一.Hadoop环境配置概述 三台虚拟机,操作系统为:Ubuntu 16.04. Hadoop版本:2.7.2 NameNode:192.168.72.132 DataNode:192.168.72. ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
- HDFS概述
HDFS概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS产出背景及定义 1>.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- 介绍hadoop中的hadoop和hdfs命令
有些hive安装文档提到了hdfs dfs -mkdir ,也就是说hdfs也是可以用的,但在2.8.0中已经不那么处理了,之所以还可以使用,是为了向下兼容. 本文简要介绍一下有关的命令,以便对had ...
- hadoop之hdfs架构详解
本文主要从两个方面对hdfs进行阐述,第一就是hdfs的整个架构以及组成,第二就是hdfs文件的读写流程. 一.HDFS概述 标题中提到hdfs(Hadoop Distribute File Syst ...
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- Hadoop之HDFS介绍
1. 概述 HDFS是一种分布式文件管理系统. HDFS的使用场景: 适合一次写入,多次读出的场景,且不支持文件的修改: 适合用来做数据分析,并不适合用来做网盘应用: 1.2 优缺点 优点: 高容错性 ...
随机推荐
- 1、Linux的安装及基本配置
1.安装 2.登录后开启root用户 https://www.cnblogs.com/suhfj-825/p/8611436.html https://www.cnblogs.com/suhfj-82 ...
- html5+css基础
最近在学习html+css3基础教程,整理了一些基础知识点.在此与大家分享. 1.盒模型 定义:css处理网页时,它认为每个元素都包含在一个不可见的盒子里,即我们所熟知的盒模型.其中它的主要属性有:h ...
- 项目从.net core 2.1.0升级到.net core 2.2.4,原有项目出错及解决方案
... 1.Controller中的形参命名为query.pager,且里面实体中的参数也有Query.Pager参数时,Query.Pager 就会无数据. 解决方案: 形参query.pager ...
- 黑苹果,Win7,Win10,Xp 各个系统镜像文件下载地址(备用)
windows Mac Xp(系统镜像下载装系统专区)百度系统世家也可 http://www.xp933.com/download/ 黑苹果系统(各种驱动型号下载专区) http://www.it36 ...
- Windows Java安装
jdk安装与配置jdk for windows1.下载官网地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html2. ...
- PS跑马灯效果和更换图标
最终效果 1.图片修改 跑马灯效果图 Head页面 使用的 IScript_HPDefaultHdr() in WEBLIB_PORTAL.PORTAL_HOMEPAGE 这个页面 一 ...
- sersync客户端搭建及配置
首先需要自行下载sersync包,地址如下: 谷歌项目地址:https://code.google.com/archive/p/sersync/ 64位下载地址:https://storage.goo ...
- 再谈HTTP2性能提升之背后原理—HTTP2历史解剖
即使千辛万苦,还是把网站升级到http2了,遇坑如<phpcms v9站http升级到https加http2遇到到坑>. 因为理论相比于 HTTP 1.x ,在同时兼容 HTTP/1.1 ...
- CentOS7 源码编译安装Tengine
简介 Tengine是由淘宝网发起的Web服务器项目.它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性.它的目的是打造一个高效.安全的Web平台. 发展 Tengine的性能和 ...
- OpenStack-Neutron-Fwaas-代码【二】
上一节从代码层面来讲解了fwaas的流程,这里通过具体查看iptables规则来说下应用规则的流程: 1.首先通过命令获取当前路由中的规则 #ip netns exec qrouter-[router ...