在Python中使用BeautifulSoup进行网页爬取
|
简介:Web抓取是从Internet提取数据的过程。这也称为网络收集或网络数据提取。Python使我们能够使用自动化技术执行Web抓取。BeautifulSoup是一个Python库,用于解析HTML和XML文档中的数据(结构化数据)。 |
互联网有海量数据。无论你是数据科学家,商人,学生还是专业人士,所有人都会从互联网上获取数据。
网页抓取是什么意思?这是从网站提取数据的简单动作。甚至从Internet复制和粘贴数据都是Web抓取。因此,如果你从互联网上下载了喜欢的歌曲,则意味着您已经从互联网上抓取了数据。
在本文中,我们将探讨一些与Web抓取有关的最常见问题,然后我们将介绍创建Web抓取工具的整个过程,并使Web抓取任务自动化!
什么是网页抓取?
Web抓取是从Internet提取数据的过程。这也称为网络收集或网络数据提取。Python使我们能够使用自动化技术执行Web抓取。
Python中用于网络抓取的一些最常用的库是:
- requests
- BeautifulSoup4
- Selenium
- Scrapy.
为什么我们要从互联网上抓取数据?
如果按照适当的指导方针进行Web抓取,并且可以通过自动化,实现我们在Internet上重复执行的日常任务,会使我们的生活变得轻松。
- 如果你是数据分析师,并且需要每天从Internet提取数据,那么创建一个自动Web爬虫是减轻你每天手动提取数据负担的解决方案。
- 你可以使用网络抓取工具从在线购物网站提取有关产品的信息,并比较产品价格和规格。
- 你可以将网页抓取用于内容营销和社交媒体促销。
- 作为学生或研究人员,你可以使用网络抓取从网络中提取研究/项目的数据。
最重要的是,“自动采集可以让您聪明地工作!”
网站采集合法吗?
这是一个非常重要的问题,但是,对此没有具体答案。有些网站不介意你从其网页上抓取内容,而另一些网站则禁止抓取内容。因此,有必要遵循准则,并且在从其网页上抓取内容时不要违反网站的政策。
让我们看看在通过Internet抓取内容时必须牢记的一些重要准则。






在深入研究网络抓取之前,了解网络的工作原理以及什么是超文本标记语言非常重要,因为这就是我们要从中提取数据的方式。因此,让我们简要讨论一下HTTP请求响应模型和HTML。
HTTP请求/响应模型
网络工作原理的整个工作原理可能非常复杂,但让我们尝试并从简单的角度理解事物,这将使我们对如何进行网络抓取有所了解。
简而言之,HTTP请求/响应是HTTP和其他基于HTTP的扩展协议使用的通信模型,根据该模型,客户端(Web浏览器)向服务器发送对资源或服务的请求,然后服务器发送如果成功处理了请求,则返回与资源相对应的响应;否则,如果服务器无法处理该请求,则服务器将以错误消息进行响应。

与Web服务器进行交互的HTTP方法很多。但最常用的是 get 和 post
- GET:用于从Web服务器中的特定资源请求数据。
- POST:用于将数据发送到服务器以创建/更新资源。
其他HTTP方法是:
- PUT
- HEAD
- DELETE
- PATCH
- OPTIONS
注意:为了从网站上获取数据,我们将使用 requests 库和 get() 方法向Web服务器发送一个请求。
虽然HTML本身超出了本文的讨论范围,但是你必须了解HTML的基本结构。不要担心,你不需要学习如何使用HTML和CSS设计网页,但你必须了解使用HTML创建网页时使用的一些关键元素和标记。
HTML有一个层次结构 / 树形结构。这个属性使我们在访问HTML文档中的元素时,可以根据它们的父子关系来访问网页。为了可视化HTML树状结构,让我们看看下面给出的图片。
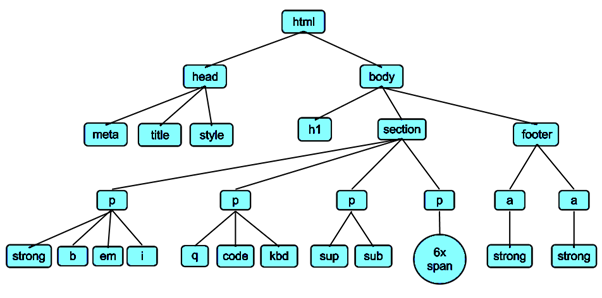
如果你想进一步探索和了解HTML的工作原理,我列出了几个链接:
创建网络爬虫
在本次演练中,我们将抓取:
- 笑话段子内容
网站:糗事百科
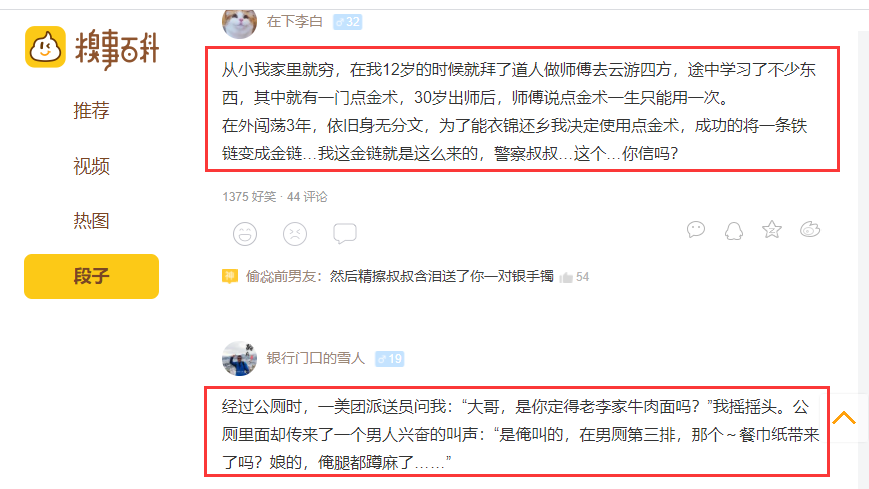
步骤1:浏览并检查网站/网页
要使用开发者工具导航:
- 右键单击该网页。
- 选择检查。
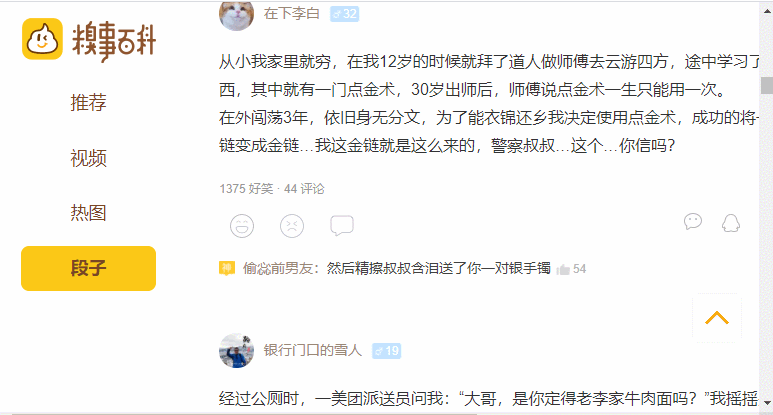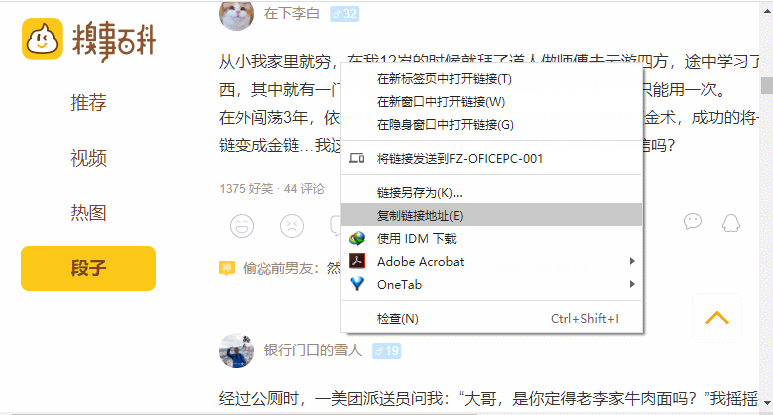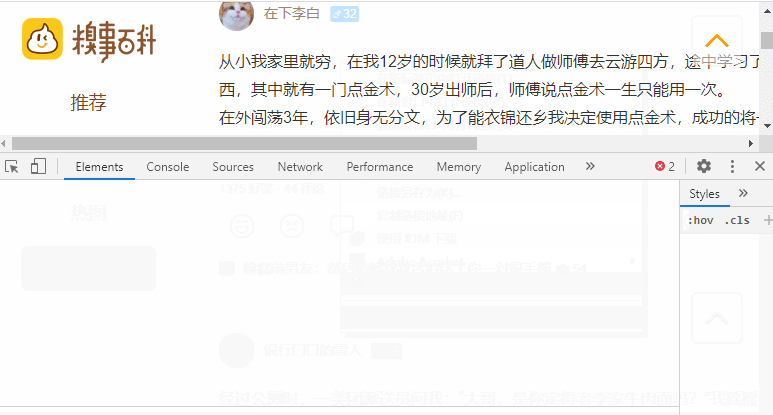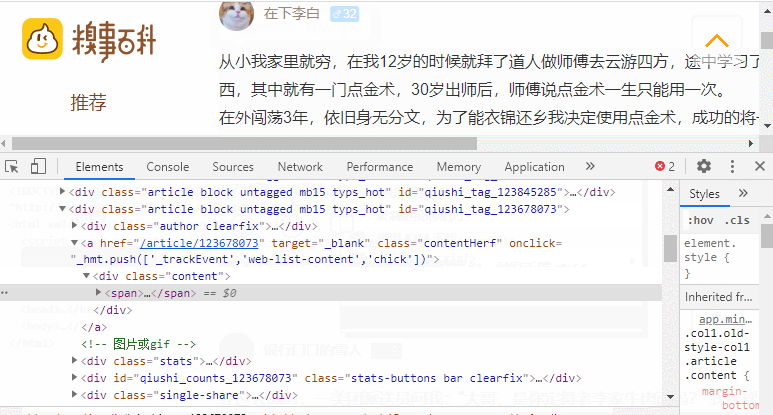
下面给出的图像表示我们在抓取时需要处理的部分。
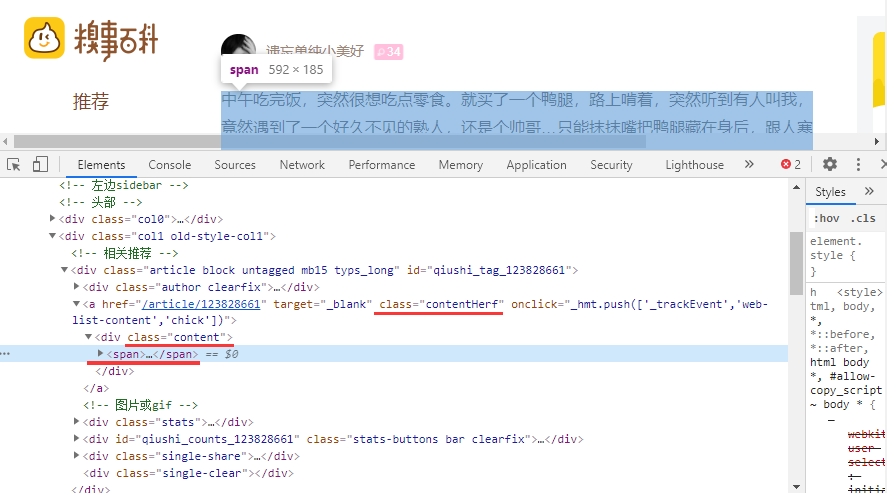
步骤2:创建用户代理
用户代理是客户端(通常是Web浏览器),用于代表用户向Web服务器发送请求。当从同一台机器/系统一次又一次地获取自动化请求时,Web服务器可能会猜测该请求是自动化发送的。它会阻止了该请求。因此,我们可以使用用户代理来伪造浏览器,访问特定网页,从而使服务器认为请求来自原始用户,而不是机器人。
语法:
# 创建 User-Agent (可选)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
# 将User-Agent作为参数与get()请求一起传递
response = requests.get("https://www.qiushibaike.com/text/page/1/", headers=headers)
步骤3:导入请求库
Requests 请求库允许我们发送 get 请求到Web服务器。
运作方式如下:
- import requests 该库以一种易于处理的格式,处理从服务器请求网站的细节。
- 使用 requests.get(...) 方法访问网站,并将URL 作为参数传递, 以便函数知道要访问的位置。
- 访问get请求的实际主体(返回值是一个请求对象,它还包含一些有用的元信息,如文件类型等),并使用 .text 属性将其存储在一个变量中。
语法:
# 存储网页内容
webpage = response.text
检查状态码
服务器处理完HTTP请求后,它将发送包含状态码的响应。状态代码指示特定响应是否已成功处理。
主要有5种不同的状态代码类别:

语法:
print(response.status_code)
200
步骤4:使用 BeautifulSoup 库解析HTML
BeautifulSoup是一个Python库,用于解析HTML和XML文档中的数据(结构化数据)。
- 导入BeautifulSoup库。
- 创建BeautifulSoup对象。第一个参数表示HTML数据,而第二个参数是解析器。
语法:
# 从bs4导入BeautifulSoup
from bs4 import BeautifulSoup
# 从网页内容中创建一个BeautifulSoup对象
soup = BeautifulSoup(webpage, "lxml")
创建BeautifulSoup对象后,我们需要使用BeautifulSoup 库提供给我们的不同选项来导航和查找HTML文档中的元素,并从中抓取数据。
步骤5:使用for循环请求多个页面
语法:
# 指定10个页面,循环赋值
for page in range(10):
response = requests.get('https://www.qiushibaike.com/text/page/{}/'.format(page), headers=headers)
步骤6:使用 select() 方法,快速找到标签元素
soup.select('a.contentHerf .content span')
步骤7:数据清洗,删除字符串“None”
语法:
if joke.string is not None:
print(joke.string)
最终的解决方案
现在,我们合并所有步骤,以达到最终的解决方案/代码,如下所示:
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
for page in range(10):
response = requests.get('https://www.qiushibaike.com/text/page/{}/'.format(page), headers=headers)
webpage = response.text
soup = BeautifulSoup(webpage, "lxml")
for joke in soup.select('a.contentHerf .content span'):
if joke.string is not None:
print(joke.string)
输出:

最后
希望阅读完整篇文章后,你可以轻松地从网页中抓取数据!
请订阅并继续关注继续关注,以后会收到更多有趣的文章。
本文为“一个火星程序员”原创文章,转载请标明出处
原文链接:https://www.cnblogs.com/oklucas/articles/14089851.html
在Python中使用BeautifulSoup进行网页爬取的更多相关文章
- Python和BeautifulSoup进行网页爬取
在大数据.人工智能时代,我们通常需要从网站中收集我们所需的数据,网络信息的爬取技术已经成为多个行业所需的技能之一.而Python则是目前数据科学项目中最常用的编程语言之一.使用Python与Beaut ...
- Python——初识网络爬虫(网页爬取)
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫 ...
- Python中使用requests和parsel爬取喜马拉雅电台音频
场景 喜马拉雅电台: https://www.ximalaya.com/ 找到一步小说音频,这里以下面为例 https://www.ximalaya.com/youshengshu/16411402/ ...
- Python爬虫——用BeautifulSoup、python-docx爬取廖雪峰大大的教程为word文档
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 廖雪峰大大贡献的教程写的不错,写了个爬虫把教程保存为word文件,供大家方便下载学习:http://p ...
- Python中的BeautifulSoup模块
目录 BeautifulSoup Tag NavigableString BeautifulSoup Comment 遍历文档树 直接子节点 所有子孙节点 节点内容 搜索标签 CSS选择器 Bea ...
- 第14.12节 Python中使用BeautifulSoup解析http报文:使用select方法快速定位内容
一. 引言 在<第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问>和<第14.11节 Python中使用BeautifulSo ...
- 第14.11节 Python中使用BeautifulSoup解析http报文:使用查找方法快速定位内容
一. 引言 在<第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问>介绍了BeautifulSoup对象的主要属性,通过这些属性可以访 ...
- 第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问
一. 引言 在<第14.8节 Python中使用BeautifulSoup加载HTML报文>中介绍使用BeautifulSoup的安装.导入和创建对象的过程,本节介绍导入后利用Beauti ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
随机推荐
- oracle 释放表空间到OS(resize)
1.查看表空间里面的对象 SELECT OWNER AS OWNER, SEGMENT_NAME AS SEGMENT_NAME, SEGMENT_TYPE AS SEGMENT_TYPE, SUM ...
- 【pytest】(十二)参数化测试用例中的setup和teardown要怎么写?
还是一篇关于pytest的fixture在实际使用场景的分享. fixture我用来最多的就是写setup跟teardown了,那么现在有一个用例是测试一个列表接口,参数化了不同的状态值传参,来进行测 ...
- jvm源码解析java对象头
认真学习过java的同学应该都知道,java对象由三个部分组成:对象头,实例数据,对齐填充,这三大部分扛起了java的大旗对象,实例数据其实就是我们对象中的数据,对齐填充是由于为了规则分配内存空间,j ...
- 【CentOS7】Apache发布静态网页-超简单
目前能够提供Web网络服务的程序有 IIS. Nginx和 Apache等.其中,IIS (Internet Information Services,互联网信息服务)是 Windows系统中默认的 ...
- 开源AwaitableCompletionSource,用于取代TaskCompletionSource
1 TaskCompletionSource介绍 TaskCompletionSource提供创建未绑定到委托的任务,任务的状态由TaskCompletionSource上的方法显式控制,以支持未来的 ...
- Java编程技术之浅析SPI服务发现机制
SPI服务发现机制 SPI是Java JDK内部提供的一种服务发现机制. SPI->Service Provider Interface,服务提供接口,是Java JDK内置的一种服务发现机制 ...
- 淘宝APP消息推送模型
为什么到了2020年,"统一推送联盟"依旧无法起显著作用? - 知乎 https://www.zhihu.com/question/370632447 https://mp.wei ...
- nginx proxy pass redirects ignore port
nginx proxy pass redirects ignore port $host in this order of precedence: host name from the request ...
- Graceful restart of a server with active WebSocket
Graceful restart of a server with active WebSocket Simonwep/graceful-ws: ⛓ Graceful WebSocket wrappe ...
- (Oracle)导出表结构
DECLARE cursor t_name is SELECT rank() over(order by a.TABLE_NAME) as xiaolonglong,a.TABLE_NAME FROM ...