python3--网络爬虫--爬取图片
网上大多爬虫仍旧是python2的urllib2写的,不过,坚持用python3(3.5以上版本可以使用异步I/O)
相信有不少人爬虫第一次爬的是Mm图,网上很多爬虫的视频教程也是爬mm图,看了某人的视频后,把这个爬虫给完成了
因为爬取的内容涉及个人隐私,所以,爬取的代码及网址不在此公布,不过介绍一下爬取的经验:
1.我们首先得了解我们要爬取的是什么,在哪爬取这些信息,不要着急想用什么工具,怎么搞,怎么搞得
2.手动操作一遍爬虫要完成的任务,我这个就是爬图片的,可以自己操作一遍
3.打开抓包软件或者Google的F12调试工具,查看数据,了解请求过程中的信息,如网址,发送请求的数据
大概了解以上信息后,可以开始编写爬虫了(个人经验,大牛勿喷,,,)
介绍python3用于爬虫的模块及方法:
可以查看官方的API文档,看懂文档,下面的就不用看了
urllib包:在python2中urllib和urllib2是分开的,python3合并在了一起,强调,这是个包,所以很多函数不一样了,但是还是那个味道
urllib.requestfor opening and reading URLsurllib.errorcontaining the exceptions raised byurllib.requesturllib.parsefor parsing URLsurllib.robotparserfor parsingrobots.txtfiles
这四个模块中urllib.request是常用的,urllib.parse中urlencode()也是会用到的
在urllib.request中,常用的方法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
headers参数,如果不想很容易被服务器发现,那么最起码加个user-agent吧,当然,你可以设置代理ip
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
将请求发送的data字典转化为str,经过编码,data成了(get请求不用)
在爬取的过程中,正则表达式一定会用到,推荐一款软件:MTracer,可以自己尝试写正则: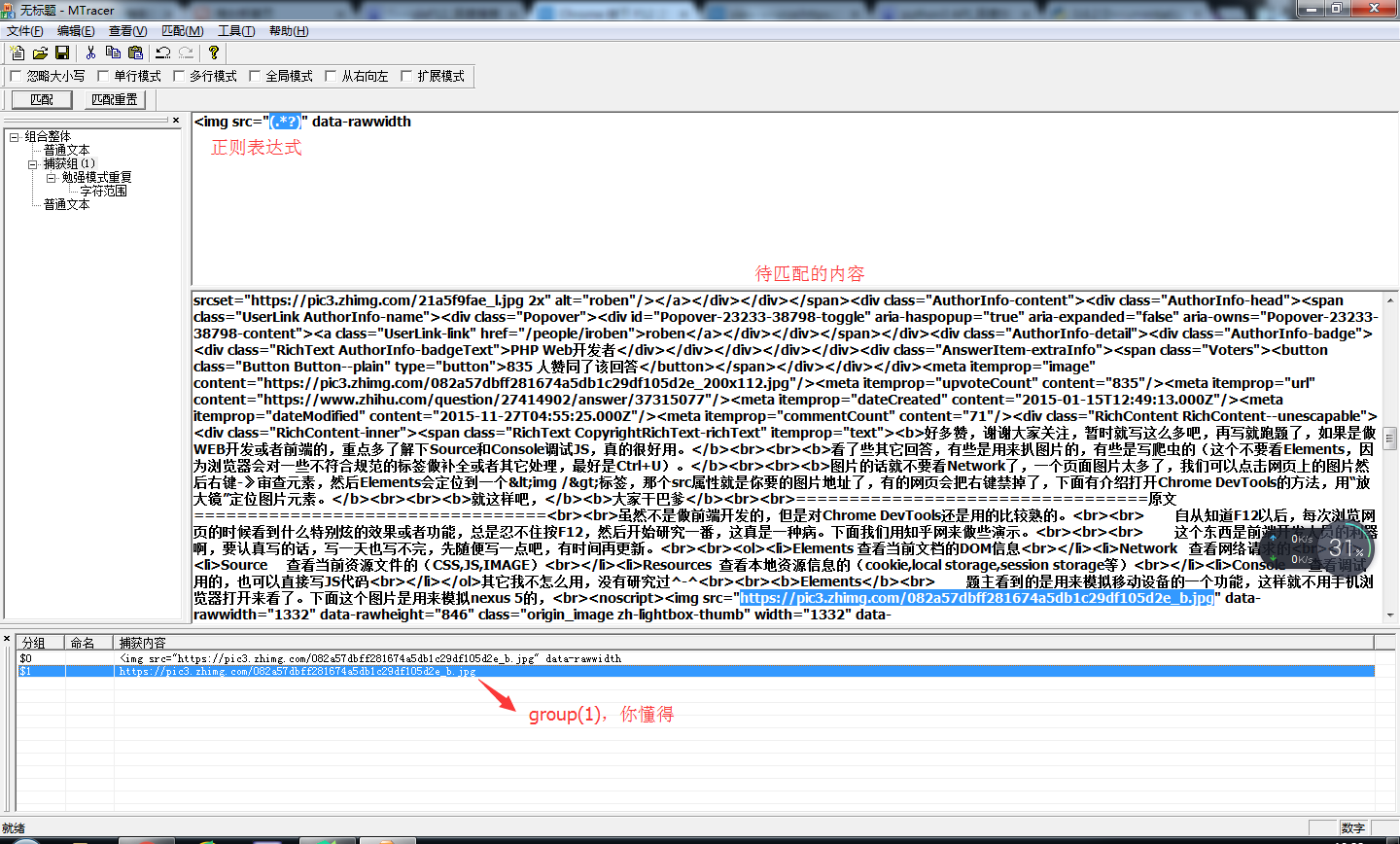
还是很不错的,谁爬谁知道
python3--网络爬虫--爬取图片的更多相关文章
- python网络爬虫&&爬取图片
爬取学院官网数据from urllib.request import * #导入所有request urllib文件夹,request只是里面的一个模块from lxml import etree # ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3网络爬虫(四):使用User Agent和代理IP隐藏身份《转》
https://blog.csdn.net/c406495762/article/details/60137956 运行平台:Windows Python版本:Python3.x IDE:Sublim ...
随机推荐
- BeanUtils.copyProperties()方法引入不同包
两个对象之间拷贝相同的属性,可以使用BeanUtils.copyProperties()方法, BeanUtils.copyProperties(obj1,obj2); 提示有三个包可选. A,选择o ...
- Java常用类String的面试题汇总
比较两个字符串时使用"=="还是equals()方法? 当然是equals方法."=="测试的是两个对象的引用是否相同,而equals()比较的是两个字符串的值 ...
- Swift字符串插值
字符串插值是一种全新的构建字符串的方式,可以在其中包含常量.变量.字面量和表达式.您插入的字符串字面量的每一项都被包裹在以反斜线为前缀的圆括号中: let multiplier = let messa ...
- AngularJs学习笔记0——前言
距离上次写博客有很长时间了,这段时间中也一直想坚持写博客,但是迟迟未动,一方面是因为刚换工作并适应新的环境导致工作比较忙碌,一直没有抽出时间来,其实说白了就是给自己的懒惰找借口,但是本人在园子里也有一 ...
- JS组件系列——自己动手扩展BootstrapTable的 冻结列 功能:彻底解决高度问题
前言:一年前,博主分享过一篇关于bootstrapTable组件冻结列的解决方案 JS组件系列——Bootstrap Table 冻结列功能IE浏览器兼容性问题解决方案 ,通过该篇,确实可以实现bo ...
- JavaScript函数的各种调用模式
函数是JavaScript世界里的第一公民,换句话来说,就是我们如果可以精通JavaScript函数的使用,那么对JavaScript的运用可以更游刃有余了.熟悉JavaScript的人应该都知道,同 ...
- tp框架---验证码详解
很多注册登录界面都会验证码,用tp如何实现验证码的功能呢? 在tp中:Think\Verify类可以支持验证码的生成和验证功能. 首先,看一下逻辑: (1)如何生成?------ 先做Yanzheng ...
- 如何在docker配置asp.net core https协议
本文参考自<Step by step: Expose ASP.NET Core over HTTPS with Docker> 自从微软发布.net core以来,就在许多社区掀起了讨论, ...
- 给xcode项目修改名字
在xcode项目开发中,经常会遇到需要修改项目名字的问题, 但是xcode本身修改项目名字比较麻烦,有时候修改的不完全,有时候修改了项目无法打开,无奈只能建一个新项目.这里提供一种修改xcode项目名 ...
- TortoiseGit上传项目到github方法(超简单)
Github是咱广大开发者用的非常多的项目版本管理网站,项目托管可以是私人的(private)或者公开的(public),私人的收费,一个月7美金.咱这里就只说我们个人使用的,一般都是代码对外开放的: ...