Spark是什么
官方直达电梯
Spark一种基于内存的通用的实时大数据计算框架(作为MapReduce的另一个更优秀的可选的方案)
- 通用:Spark Core 用于离线计算,Spark SQL 用于交互式查询,Spark Streaming 用于实时流式计算,Spark Mlib 用于机器学习,Spark GraphX 用于图计算
- 实时:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
一、Spark和Storm的区别
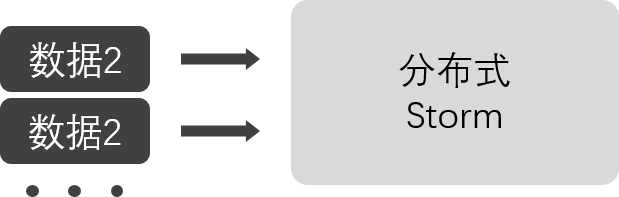
Storm的计算模型(实时)
- Storm是针对每条数据的流式实时计算框架,由于每条数据过来就直接处理,每条数据都会带来大量的资源消耗(传输,通信,校验等)吞吐量不高
- storm可以动态调整并行度
- Storm保证了更高的实时性,毫秒级延迟
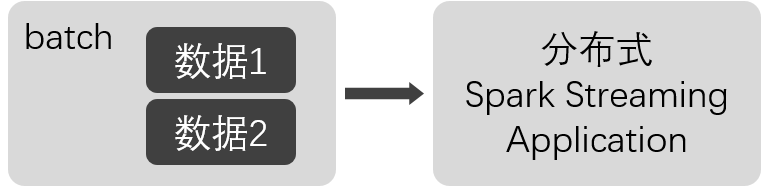
Spark Stream计算模型(准实时)
- 通过设置时间间隔 batch interval 一个时间间隔内的数据作为一个Batch收集起来给Spark Streaming Application处理(少了很多传输,校对开销),保证了高吞吐量
- 秒级延迟
- 结合Spark生态圈可以发挥很大的威力
二、Spark Streaming和MapReduce的对比
Shuffle以及MapReduce的计算模型决定了MapReduce只适合对速度要求不敏感的离线批处理任务
- Spark的多进程任务可能在同一个物理机器的内存上完成(Spark shuffle也会使用磁盘)
- MapReduce死板的模型必须基于磁盘和大量的网络传输
- MapReduce的程度编写复杂,Spark更容易上手,支持(Scale JAVA[8支持函数式编程] Python)
- Spark 在缺少调优时,会出现OOM(Out Of Memory)的问题,导致程序无法执行,而MapReduce就算是慢也能执行

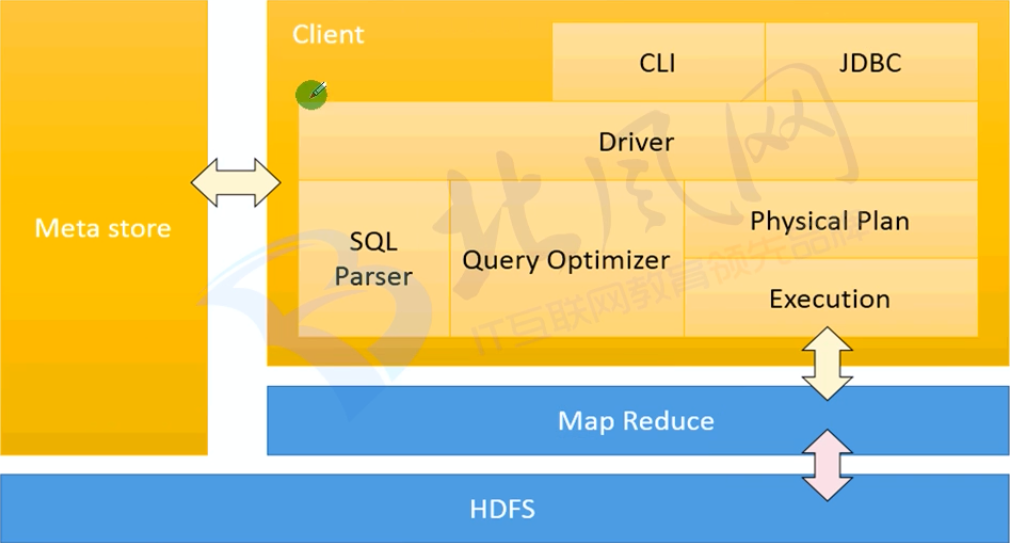
三、Spark SQL对比Hive
- Spark SQL实际上不能完全替代Hive,只是替代了Hive中的查询引擎,针对Hive数据仓库中的表进行SQL查询
- 由于Hive查询底层基于MapReduce决定了Hive的查询慢
- Hive中的一部分高级特性在Spark SQL 中未得到支持
- Spark SQL除了Hive还支持其他数据源(json parquet jdbc等),同时支持直接针对HDFS执行SQL查询
Spark是什么的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
随机推荐
- wmware共享磁盘redhat 5.8挂载问题
需要修改参数vi /etc/sysconfig/selinux将SELINUX=enforcing改为SELINUX=disabled,这样重启服务器则不会启动selinux服务 不然重启虚拟机后共享 ...
- 基于Qt搭建ROS开发环境
参考的博客: http://blog.csdn.net/u013453604/article/details/52186375 http://blog.csdn.net/dxuehui/article ...
- maven学习记录二——依赖管理
5 依赖管理 Jar包的管理 需求:整合struts2 页面上传一个客户id 跳转页面 5.1 添加依赖: 打开maven仓库的视图: 5.2 重建索引 1. 创建m ...
- 【luogu P2324 [SCOI2005]骑士精神】 题解
题目链接:https://www.luogu.org/problemnew/show/P2324 不懂怎么剪枝,所以说,,我需要氧气.. 第一道A* // luogu-judger-enable-o2 ...
- 【luogu P3865 ST表】 模板
跟忠诚是一样滴,不过是把min改成max就AC了.模板题. #include <cstdio> #include <algorithm> using namespace std ...
- 在CentOs6.5下安装Python2.7.6和Scrapy
总在网上看大家的安装教程,这回自己也贡献一份!!! 和民航大学合作项目,去给人家装环境,连简单的Scrapy都没装上,虽然有对方硬件设施坑爹的因素,但主要还是自己准备不充分. 一份好的安装文档应该是可 ...
- HTML5之canvas基本API介绍及应用 1
一.canvas的API: 1.颜色.样式和阴影: 2.线条样式属性和方法: 3.路径方法: 4.转换方法: 5.文本属性和方法: 6.像素操作方法和属性: 7.其他: drawImage:向画布上绘 ...
- 在cengos中安装zabbix server/agent, 并创建一个简单demo
添加zabbix更新源 rpm -ivh http://repo.zabbix.com/zabbix/2.4/rhel/6/x86_64/zabbix-release-2.4-1.el6.noarch ...
- SQL on&where&having
on.where.having这三个都可以加条件的子句中,on是最先执行,where次之,having最后.有时候如果这先后顺序不影响中间结果的话,那最终结果是相同的.但因为on是先把不符合条件的记录 ...
- CentOS 7 安装oracle 11.2.0.4 Error in invoking target 'agent nmhs' of makefile
%86时出现报错 Error in invoking target 'agent nmhs' of makefile 解决方案在makefile中添加链接libnnz11库的参数修改$ORACLE ...