Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url、标题以及摘要。
实例环境:python3.7
requests库(内置的python库,无需手动安装)
re库(内置的python库,无需手动安装)
实例网站:
第一步,点击网站地址http://www.eastmountyxz.com/,查看页面有哪些信息,网页标题、图片以及摘要等
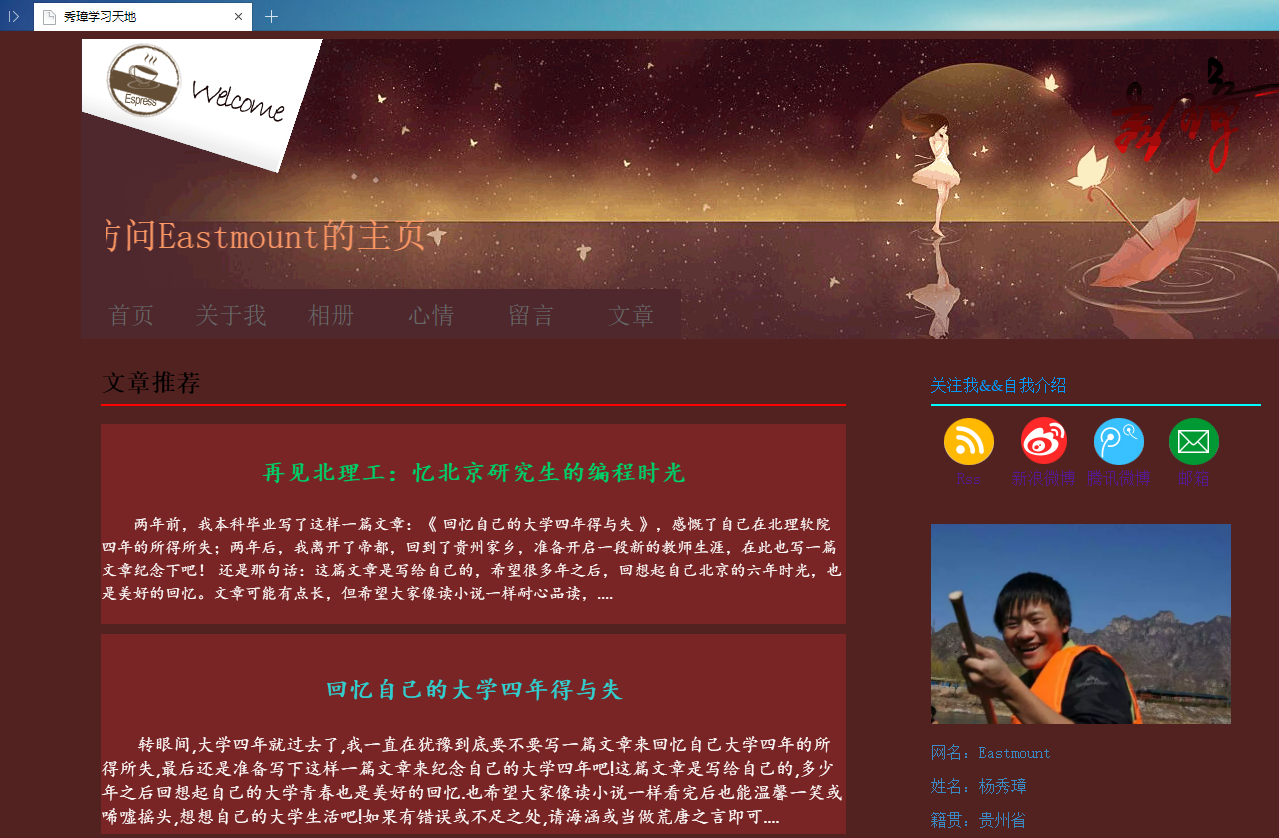
第二步,查看网页源代码,即可看到想要爬取的基本信息


实例代码:
#encoding:utf-8
import re
#import urllib.request
import requests def getHtmlStr(url):
#content = urllib.request.urlopen(url).read().decode("utf-8")
res = requests.get(url)
res.encoding = res.apparent_encoding
return res.text def parseHtml(content):
#爬取整个网页的标题
title = re.findall(r'<title>(.*?)</title>', content)
print(title[0])
#爬取图片地址
urls = re.findall(r'<img .*src="\./(.*?)"', content)
baseUrl = 'http://www.eastmountyxz.com/' for i in range(len(urls)):
urls[i] = baseUrl + urls[i]
print(urls) #爬取文章信息
p = r'<div class="essay.*?">(.*?)</div>'
artcles = re.findall(p, content, re.S)
for a in artcles:
res = r'<a .*href="(.*?)">'
t1 = re.findall(res, a, re.S) #超链接
print(t1[0])
t2 = re.findall(r'<a .*?>(.*?)</a>', a, re.S) #标题
print(t2[0])
t3 = re.findall('<p style=.*?>(.*?)</p>', a, re.S) #摘要(
print(t3[0].replace(' ',''))
print('') if __name__ == '__main__':
url = "http://www.eastmountyxz.com/"
htmlString = getHtmlStr(url)
parseHtml(htmlString)
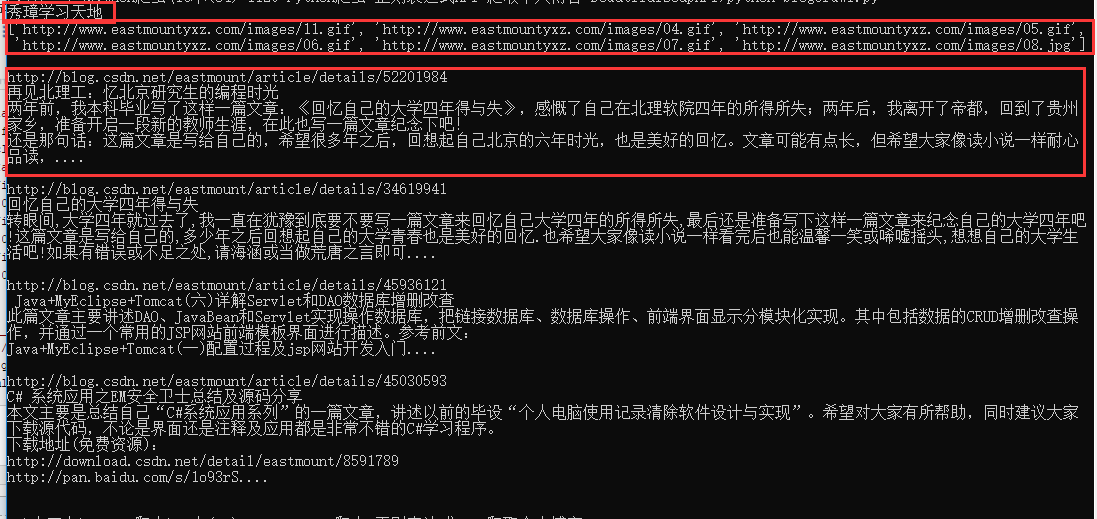
实例结果:
Python爬虫学习之正则表达式爬取个人博客的更多相关文章
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python爬虫之利用正则表达式爬取内涵吧
首先,我们来看一下,爬虫前基本的知识点概括 一. match()方法: 这个方法会从字符串的开头去匹配(也可以指定开始的位置),如果在开始没有找到,立即返回None,匹配到一个结果,就不再匹配. 我们 ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫学习笔记之爬取新浪微博
import requests from urllib.parse import urlencode from pyquery import PyQuery as pq from pymongo im ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
随机推荐
- Codeforces Round #553 (Div. 2) A题
题目网址:http://codeforces.com/contest/1151/problem/A 题目大意:给定一个由大写字母构成的字符串和它的长度,有这样的操作,使任意一个字母变成与其相邻的字母, ...
- 更换Appsecrect应该要注意的问题
1. 有时候因为需要,有些地方需要填写Appsecrect, 但是大家都知道微信公众平台上这个值 即使你自己是管理员是看不到的,只能重置,但是重置后,一定要记住刷新AccessToken啊,不然就尴尬 ...
- Oracle使用触发器和mysql中使用触发器的比较
一.触发器 1.触发器在数据库里以独立的对象存储, 2.触发器不需要调用,它由一个事件来触发运行 3.触发器不能接收参数 --触发器的应用 举个例子:校内网.开心网.facebook,当你发一个日志, ...
- spring :Log4j各级别日志重复打印
使用filter进行日志过滤 这个其实是Log4j自带的方案,也是推荐方案,不知道为什么网上的资料却很少提到这点. 把log4j.properties配置文件修改成如下: #root日志 log4j. ...
- pd 注意事项
- beamer插入图片的一些技巧
1. 点一下,让另一张隐藏的图出现
- vue版 文件下载
标签的download: 是HTML5标准新增的属性,作用是指示浏览器下载URL而不是导航到URL,因此将提示用户将其保存为本地文件. 这种是定义的接口不是下载文件的路径,而是通过API可以获得文件的 ...
- Docker学习笔记:基础
docker的概念 :docker是一个可供开发者在容器中 开发 部署 运行 应用的一个平台.通过使用Linux容器去部署应用的方式称为容器化. 基础概念 Images and Container i ...
- 【Java】a++,++a 区分记忆
写了个例子测试: package com.xdsux.java.basetest; public class BaseTest1 { public static void main(String[] ...
- 计蒜客 2019 蓝桥杯省赛 B 组模拟赛(三)数字拆分
#include<iostream> #include<cstring> #include<cstdio> #include<algorithm> us ...