Spark学习进度-Transformation算子
Transformation算子
intersection
交集
/*
交集
*/
@Test
def intersection(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.intersection(rdd2)
.collect()
.foreach(println(_))
}
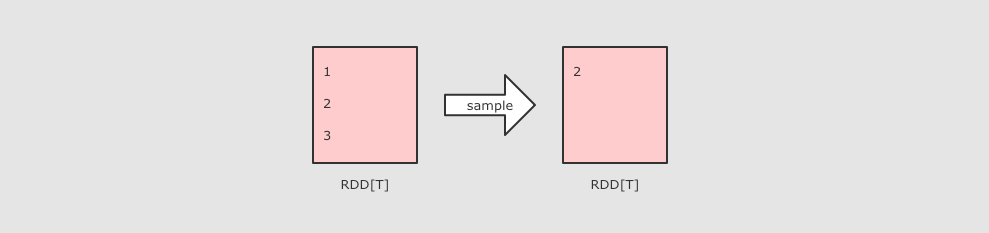
union
并集
/*
并集
*/
@Test
def union(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.union(rdd2)
.collect()
.foreach(println(_))
}

subtract
差集
@Test
def subtract(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.subtract(rdd2)
.collect()
.foreach(println(_))
}
输出:

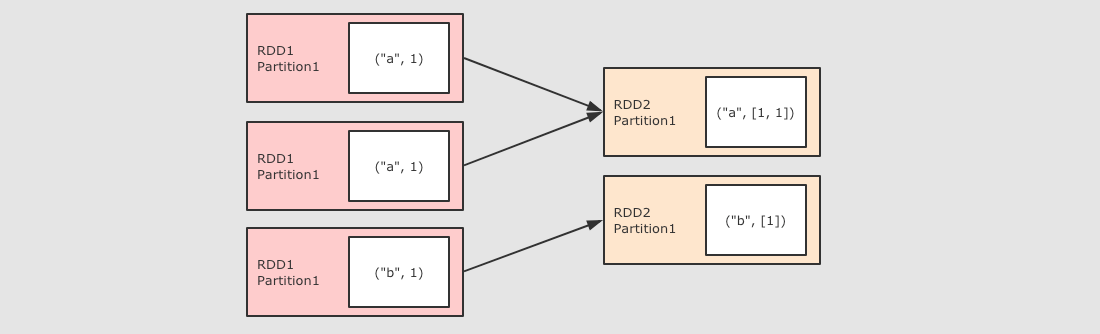
groupByKey
作用
GroupByKey 算子的主要作用是按照 Key 分组, 和 ReduceByKey 有点类似, 但是 GroupByKey 并不求聚合, 只是列举 Key 对应的所有 Value
/*
groupByKey 运算结果的格式:(K,(value1,value2))
reduceByKey 能否在Map端做Combiner
*/ @Test
def groupByKey(): Unit ={
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.groupByKey()
.collect()
.foreach(println(_))
}
distinct
作用:用于去重
@Test
def distinct(): Unit ={
sc.parallelize(Seq(1,1,2,2,3))
.distinct()
.collect()
.foreach(println(_))
}
输出:1,2,3
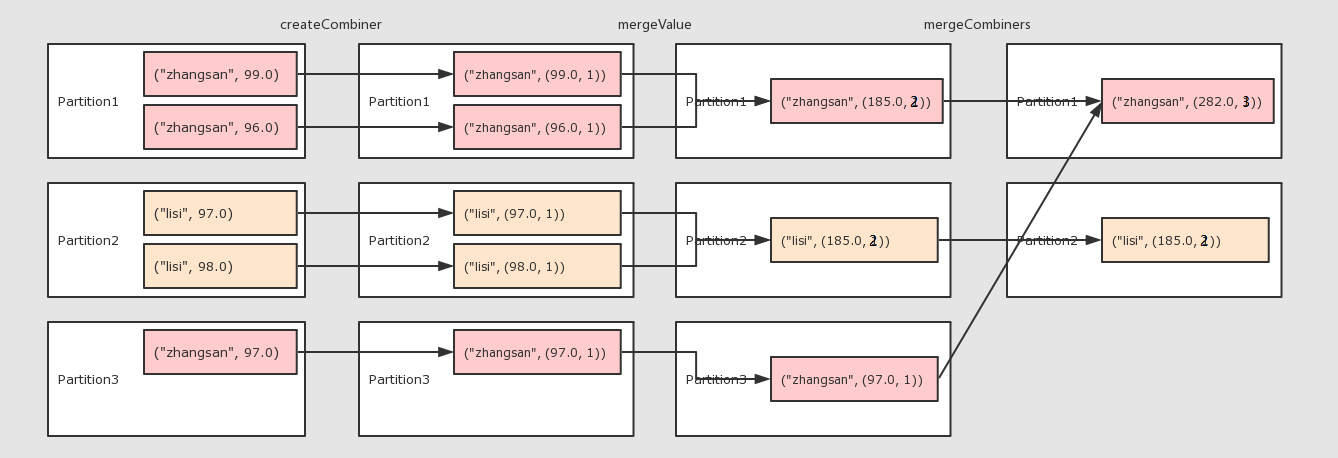
combineByKey
作用
对数据集按照 Key 进行聚合
调用
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
参数
createCombiner将 Value 进行初步转换mergeValue在每个分区把上一步转换的结果聚合mergeCombiners在所有分区上把每个分区的聚合结果聚合partitioner可选, 分区函数mapSideCombiner可选, 是否在 Map 端 Combineserializer序列化器
例子:算个人得分的平均值
@Test
def combineByKey(): Unit ={
var rdd=sc.parallelize(Seq(
("zhangsan", 99.0),
("zhangsan", 96.0),
("lisi", 97.0),
("lisi", 98.0),
("zhangsan", 97.0)
)) //2.算子运算
// 2.1 createCombiner 转换数据
// 2.2 mergeValue 分区上的聚合
// 2.3 mergeCombiners 把所有分区上的结果再次聚合,生成最终结果
val combineResult = rdd.combineByKey(
createCombiner = (curr: Double) => (curr, 1),
mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1),
mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2)
) val resultRDD = combineResult.map(item => (item._1, item._2._1 / item._2._2)) resultRDD.collect().foreach(print(_))
}
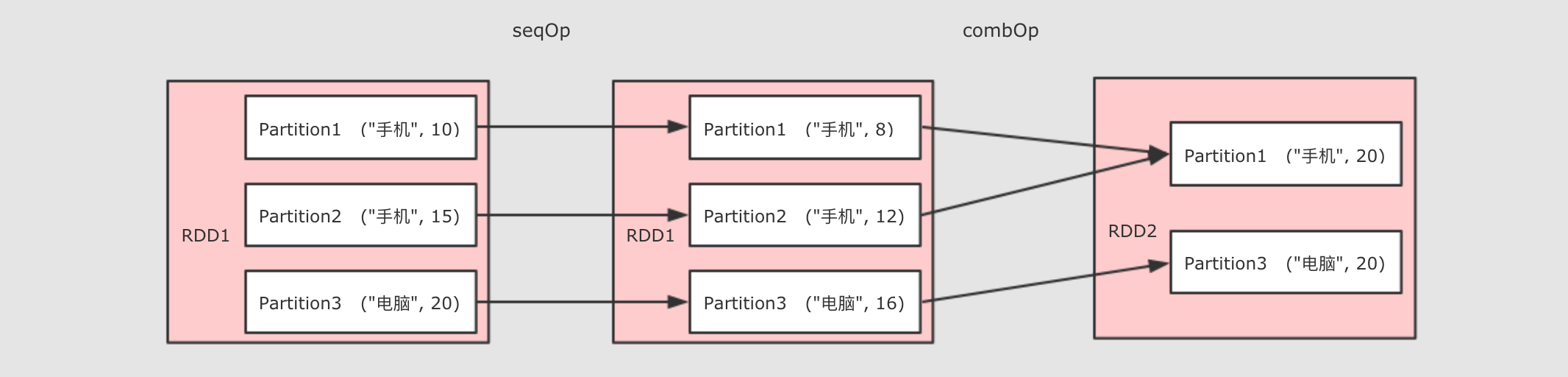
aggregateByKey
作用
聚合所有 Key 相同的 Value, 换句话说, 按照 Key 聚合 Value
调用
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
参数
zeroValue初始值seqOp转换每一个值的函数comboOp将转换过的值聚合的函数
/*
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
zeroValue 初始值
seqOp 转换每一个值的函数
comboOp 将转换过的值聚合的函数
*/ @Test
def aggregateByKey(): Unit ={
val rdd=sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0)))
rdd.aggregateByKey(0.8)(( zeroValue,item) =>item * zeroValue,(curr,agg) => curr+agg)
.collect()
.foreach(println(_))
// (手机,20.0)
// (电脑,16.0)
}
foldByKey
作用
和 ReduceByKey 是一样的, 都是按照 Key 做分组去求聚合, 但是 FoldByKey 的不同点在于可以指定初始值
/*
foldByKey可以指定初始值
*/
@Test
def foldByKey(): Unit ={
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.foldByKey(zeroValue = 10)( (curr,agg) => curr + agg )
.collect()
.foreach(println(_))
}

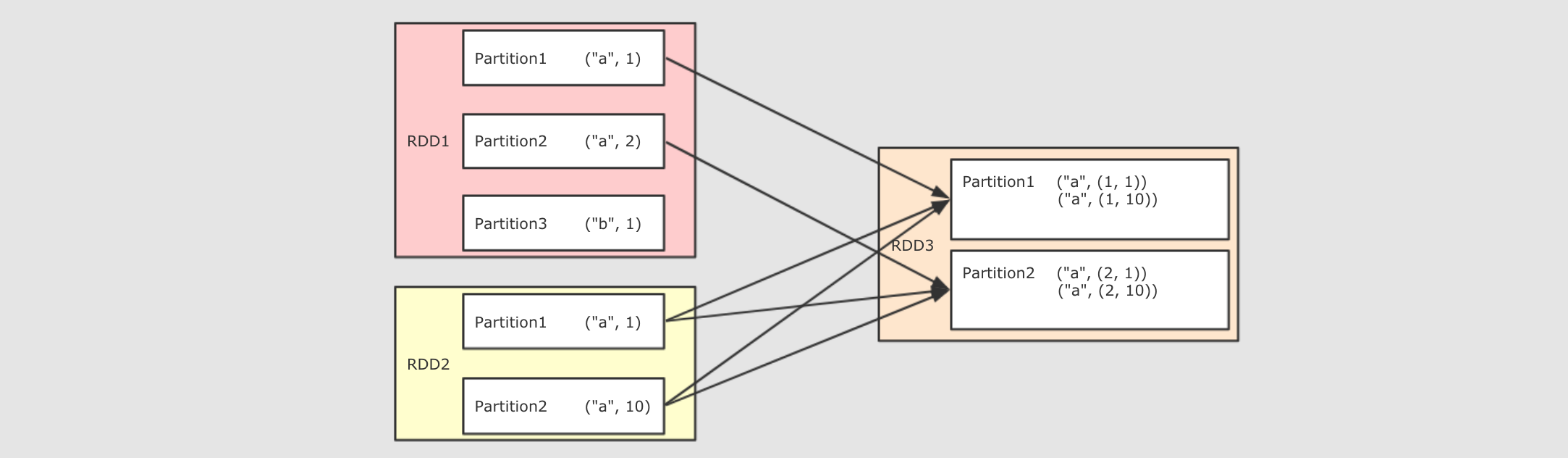
join
作用
将两个 RDD 按照相同的 Key 进行连接
@Test
def join(): Unit ={
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12))) rdd1.join(rdd2).collect().foreach(println(_))
// (a,(1,10))
// (a,(1,11))
// (a,(1,12))
// (a,(2,10))
// (a,(2,11))
// (a,(2,12))
}
sortBy
sortBy`可以指定按照哪个字段来排序, `sortByKey`直接按照 Key 来排序
@Test
def sortBy(): Unit ={
val rdd=sc.parallelize(Seq(8,4,5,6,2,1,1,9))
val rdd2=sc.parallelize(Seq(("a",1),("b",3),("c",2)))
//rdd.sortBy(item =>item).collect().foreach(println(_))
rdd2.sortBy(item => item._2).collect().foreach(println(_))
rdd2.sortByKey().collect().foreach(println(_))
}
repartition
重新进行分区
@Test
def partitioning(): Unit ={
val rdd=sc.parallelize(Seq(1,2,3,4,5),2)
//println((rdd.repartition(5)).partitions.size) println(rdd.coalesce(5,true).partitions.size)
}
Spark学习进度-Transformation算子的更多相关文章
- Spark学习笔记--Transformation 和 action
转自:http://my.oschina.net/hanzhankang/blog/200275 附:各种操作的逻辑执行图 https://github.com/JerryLead/SparkInte ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度-实战测试
spark-shell 交互式编程 题目:该数据集包含了某大学计算机系的成绩,数据格式如下所示: Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure ...
- Spark学习之常用算子介绍
1. reduceByKey reduceByKey的作用对像是(key, value)形式的rdd,而reduce有减少.压缩之意,reduceByKey的作用就是对相同key的数据进行处理,最终每 ...
- Spark学习进度7-综合案例
综合案例 文件排序 解法: 1.读取数据 2.数据清洗,变换数据格式 3.从新分区成一个分区 4.按照key排序,返还带有位次的元组 5.输出 @Test def filesort(): Unit = ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
随机推荐
- CTFD平台部署自制题目指北(灌题)
给实验室同学搭建的CTFD平台用于内部训练和CTF的校赛,为了循序渐进当然是先内部出一些简单入门的题目,但是网上大部分关于CTFD平台的都只是部署,而关于题目放置的内容却很少,虽然这个过程比较简单,但 ...
- jupyterlab 增加新内核的方法ipykernel
参考: https://blog.csdn.net/C_chuxin/article/details/82690830
- 第 4 篇 Scrum 冲刺博客
每天举行会议 会议照片: 昨天已完成的工作与今天计划完成的工作及工作中遇到的困难: 成员姓名 昨天完成工作 今天计划完成的工作 工作中遇到的困难 蔡双浩 实现收藏夹功能 实现重设计的个人界面功能 无 ...
- CSP-S 2019 Solution
Day1-T1 格雷码(code) 格雷码是一种特殊的 \(n\) 位二进制串排列法,要求相邻的两个二进制串恰好有一位不同,环状相邻. 生成方法: \(1\) 位格雷码由两个 \(1\) 位的二进制串 ...
- git学习——git下载安装
原文来至 一.集中式vs分布式 Linus一直痛恨的CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢? 先说集中式版本控制系统,版本库是集中 ...
- NPM相关知识点
1.Windows环境变量的配置 npm config set prefix "D:\Program Files\nodejs\node_global" npm config se ...
- 高速缓冲存储器Cache
目录 概述 问题的提出 局部性原理 命中与未命中 Cache的命中率 Cache-主存系统的效率 例题 工作原理 地址映射方式(本节最重要) 直接映射 全相联映射 组相联映射 例子 替换策略 例题 写 ...
- 双向数据绑定 v-model
双向数据绑定 就是既可以从页面传到数据也可以从数据到页面 初始运行结果为: 在输入框 更改数据 相应的输入框上的也会相对改变 然后再试试利用控制台更改数据 可以看到数据也被改变了 而且输入框中的内容也 ...
- 4. 上新了Spring,全新一代类型转换机制
目录 ✍前言 版本约定 ✍正文 PropertyEditor设计缺陷 新一代类型转换 Converter 代码示例 不足 ConverterFactory 代码示例 不足 GenericConvert ...
- MySQL数据归档小工具推荐--mysql_archiver
一.主要概述 MySQL数据库归档历史数据主要可以分为三种方式:一.创建编写SP.设置Event:二.通过dump导入导出:三.通过pt-archiver工具进行归档.第一种方式往往受限于同实例要求, ...