Spark学习进度-实战测试
spark-shell 交互式编程
题目:该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在 spark-shell 中通过编程来计算以下内容:
(1)该系总共有多少学生;

(2)该系共开设来多少门课程;
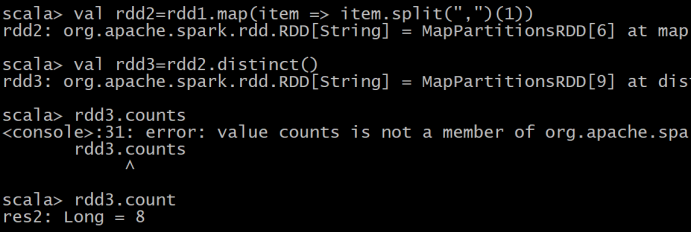
(3)Tom 同学的总成绩平均分是多少;
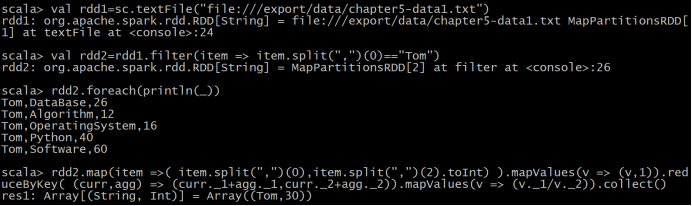
(4)求每名同学的选修的课程门数;

共265行
(5)该系 DataBase 课程共有多少人选修;

(6)各门课程的平均分是多少;

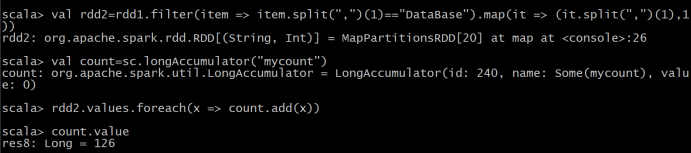
(7)使用累加器计算共有多少人选了 DataBase 这门课。
独立应用
实现数据去重,连接,排序
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其
中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
代码:
@Test
def test(): Unit ={
val conf=new SparkConf().setMaster("local[6]").setAppName("xlf_union")
val sc=new SparkContext(conf)
val ra=sc.textFile("dataset/a.txt")
val rb=sc.textFile("dataset/b.txt")
val rc=ra.union(rb)
.distinct()
.map(item => (item.split(" ")(0),item.split(" ")(1)))
.sortBy(item =>(item._1,item._2))
.collect()
val file = "dataset/c.txt"
val writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)))
for(x<- rc)
{
println(x)
writer.write(x+"\n")
}
writer.close()
}
实现求平均值
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生
名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到
一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm 成绩:
小明 92
小红 87
小新 82
小丽 90
Database 成绩:
小明 95
小红 81
小新 89
小丽 85
Python 成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
代码:
@Test
def test2(): Unit ={
val conf=new SparkConf().setMaster("local[6]").setAppName("xlf_avg")
val sc=new SparkContext(conf)
val ra=sc.textFile("dataset/Algorithm.txt")
val rb=sc.textFile("dataset/Database.txt")
val rc=sc.textFile("dataset/Python.txt")
val out=ra.union(rb)
.union(rc)
.map(item => (item.split(" ")(0),item.split(" ")(1).toDouble))
.mapValues(v => (v,1))
.reduceByKey( (x,y) =>(x._1+y._1,x._2+y._2) )
.mapValues(v => (v._1/v._2).formatted("%.2f") )
.collect()
val file = "dataset/out.txt"
val writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)))
for(x<- out)
{
println(x)
writer.write(x+"\n")
}
writer.close() }
Spark学习进度-实战测试的更多相关文章
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度-Transformation算子
Transformation算子 intersection 交集 /* 交集 */ @Test def intersection(): Unit ={ val rdd1=sc.parallelize( ...
- Spark学习进度7-综合案例
综合案例 文件排序 解法: 1.读取数据 2.数据清洗,变换数据格式 3.从新分区成一个分区 4.按照key排序,返还带有位次的元组 5.输出 @Test def filesort(): Unit = ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- Spark学习入门(让人看了想吐的话题)
这是个老生常谈的话题,大家是不是看到这个文章标题就快吐了,本来想着手写一些有技术深度的东西,但是看到太多童鞋卡在入门的门槛上,所以还是打算总结一下入门经验.这种标题真的真的在哪里都可以看得到,度娘一搜 ...
- NGUI 学习笔记实战之二——商城数据绑定(Ndata)
上次笔记实现了游戏商城的UI界面,没有实现动态数据绑定,所以是远远不够的.今天采用NData来做一个商城. 如果你之前没看过,可以参考上一篇博客 NGUI 学习笔记实战——制作商城UI界面 ht ...
随机推荐
- WindowsServerU盘系统盘制作
一.工具及安装包准备: 1.UltraISO软碟通 下载:链接:https://pan.baidu.com/s/1gixSdpEjvh6I31rGeh1-Gg 提取码:9zbx (大学期间无意间找到一 ...
- Hive数据导入HBase引起数据膨胀引发的思考
最近朋友公司在做一些数据的迁移,主要是将一些Hive处理之后的热数据导入到HBase中,但是遇到了一个很奇怪的问题:同样的数据到了HBase中,所占空间竟增长了好几倍!详谈中,笔者建议朋友至少从几点原 ...
- 题解-CF1437E Make It Increasing
题面 CF1437E Make It Increasing 给 \(n\) 个数 \(a_i\),固定 \(k\) 个下标 \(b_i\),求只修改不在 \(b_i\) 中的下标的值使 \(a_i\) ...
- sql语句执行次序
from→on→join→where→group by→having→select→distinct→order by→limit
- nginx优化-转载
(1)nginx运行工作进程个数,一般设置cpu的核心或者核心数x2 如果不了解cpu的核数,可以top命令之后按1看出来,也可以查看/proc/cpuinfo文件 grep ^processor / ...
- 关于 SFML 在 Visual Studio下的环境搭建
SFML 全称 Simple and Fast Multimedia Library,它是一个开放源代码,跨平台,支持多种编程语言绑定,并且提供简单易用的接口,用于多媒体程序和游戏开发,是替代SDL的 ...
- SpringBoot2.x集成Quartz实现定时任务管理(持久化到数据库)
1. Quartz简介 Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目. Quartz是一个完全由Java编写的开源作业调度框架,为在Java应 ...
- WindowsPhone8.1 开发-- 二维码扫描
随着 WinRT 8.1 API 的发布,Windows 8.1 和 Windows Phone 8.1 (基于 WinRT) 应用程序的开发模型经历了戏剧性的收敛性.与一些特定于平台的考虑,我们现在 ...
- Linux查看、开启、关闭防火墙操作
一.防火墙区别 CentOS6自带的防火墙是iptables,CentOS7自带的防火墙是firewall. iptables:用于过滤数据包,属于网络层防火墙. firewall:底层还是使用 ip ...
- Mybatis(二)--SqlMapConfig.xml配置文件
一.简介 SqlMapConfig.xml是Mybatis的全局配置文件,我们在写mybatis项目时,在SqlMapConfig.xml文件中主要配置了数据库数据源.事务.映射文件等,其实还有很多配 ...