Spark学习进度-Transformation算子
Transformation算子
intersection
交集
/*
交集
*/
@Test
def intersection(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.intersection(rdd2)
.collect()
.foreach(println(_))
}
union
并集
/*
并集
*/
@Test
def union(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.union(rdd2)
.collect()
.foreach(println(_))
}

subtract
差集
@Test
def subtract(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.subtract(rdd2)
.collect()
.foreach(println(_))
}
输出:

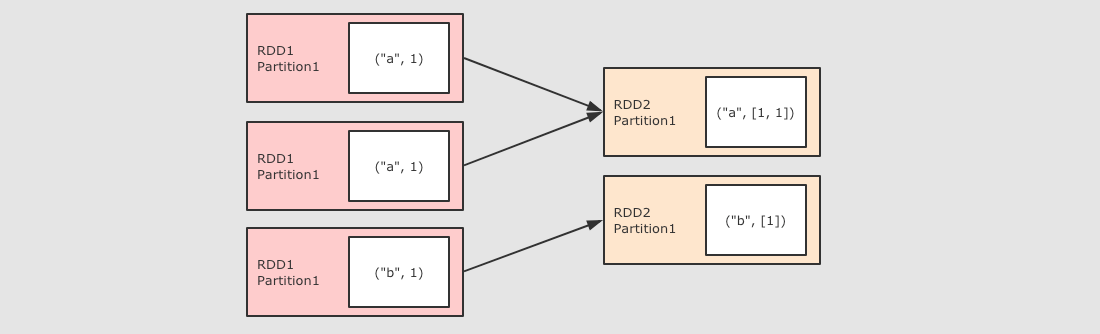
groupByKey
作用
GroupByKey 算子的主要作用是按照 Key 分组, 和 ReduceByKey 有点类似, 但是 GroupByKey 并不求聚合, 只是列举 Key 对应的所有 Value
/*
groupByKey 运算结果的格式:(K,(value1,value2))
reduceByKey 能否在Map端做Combiner
*/ @Test
def groupByKey(): Unit ={
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.groupByKey()
.collect()
.foreach(println(_))
}
distinct
作用:用于去重
@Test
def distinct(): Unit ={
sc.parallelize(Seq(1,1,2,2,3))
.distinct()
.collect()
.foreach(println(_))
}
输出:1,2,3
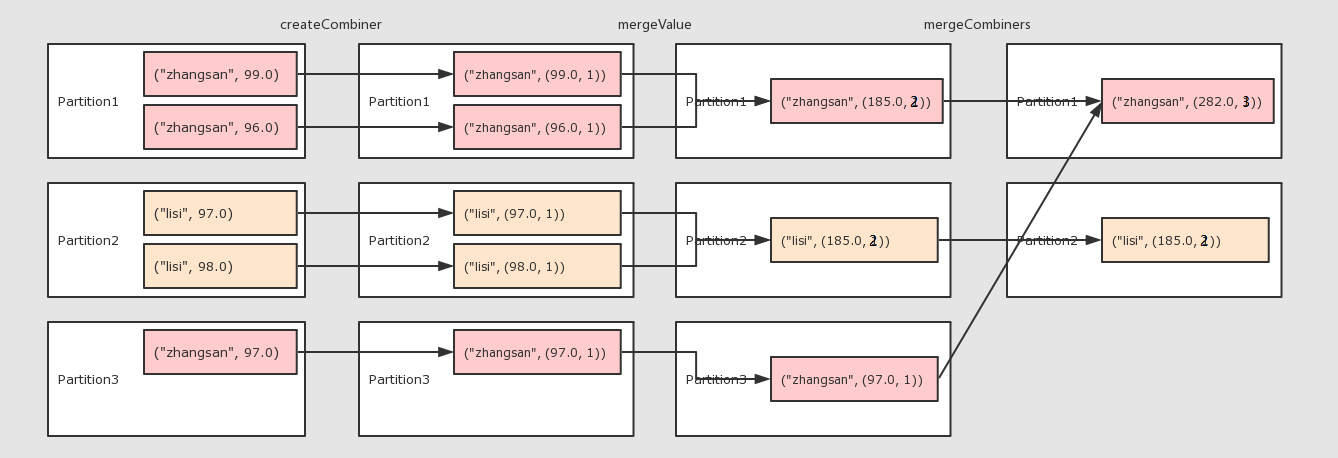
combineByKey
作用
对数据集按照 Key 进行聚合
调用
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
参数
createCombiner将 Value 进行初步转换mergeValue在每个分区把上一步转换的结果聚合mergeCombiners在所有分区上把每个分区的聚合结果聚合partitioner可选, 分区函数mapSideCombiner可选, 是否在 Map 端 Combineserializer序列化器
例子:算个人得分的平均值
@Test
def combineByKey(): Unit ={
var rdd=sc.parallelize(Seq(
("zhangsan", 99.0),
("zhangsan", 96.0),
("lisi", 97.0),
("lisi", 98.0),
("zhangsan", 97.0)
)) //2.算子运算
// 2.1 createCombiner 转换数据
// 2.2 mergeValue 分区上的聚合
// 2.3 mergeCombiners 把所有分区上的结果再次聚合,生成最终结果
val combineResult = rdd.combineByKey(
createCombiner = (curr: Double) => (curr, 1),
mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1),
mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2)
) val resultRDD = combineResult.map(item => (item._1, item._2._1 / item._2._2)) resultRDD.collect().foreach(print(_))
}
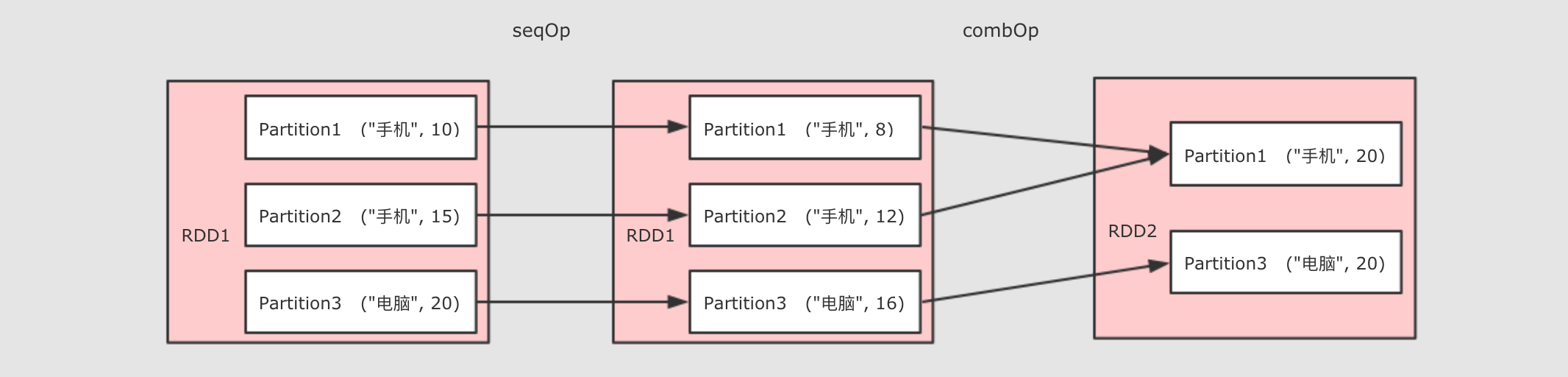
aggregateByKey
作用
聚合所有 Key 相同的 Value, 换句话说, 按照 Key 聚合 Value
调用
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
参数
zeroValue初始值seqOp转换每一个值的函数comboOp将转换过的值聚合的函数
/*
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
zeroValue 初始值
seqOp 转换每一个值的函数
comboOp 将转换过的值聚合的函数
*/ @Test
def aggregateByKey(): Unit ={
val rdd=sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0)))
rdd.aggregateByKey(0.8)(( zeroValue,item) =>item * zeroValue,(curr,agg) => curr+agg)
.collect()
.foreach(println(_))
// (手机,20.0)
// (电脑,16.0)
}
foldByKey
作用
和 ReduceByKey 是一样的, 都是按照 Key 做分组去求聚合, 但是 FoldByKey 的不同点在于可以指定初始值
/*
foldByKey可以指定初始值
*/
@Test
def foldByKey(): Unit ={
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.foldByKey(zeroValue = 10)( (curr,agg) => curr + agg )
.collect()
.foreach(println(_))
}

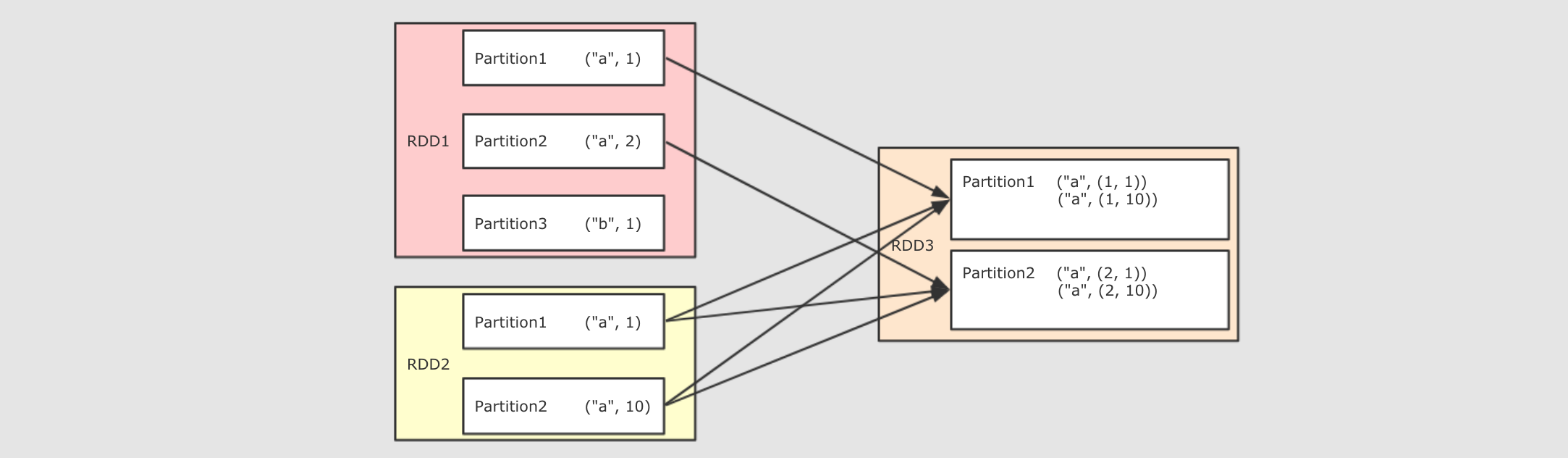
join
作用
将两个 RDD 按照相同的 Key 进行连接
@Test
def join(): Unit ={
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12))) rdd1.join(rdd2).collect().foreach(println(_))
// (a,(1,10))
// (a,(1,11))
// (a,(1,12))
// (a,(2,10))
// (a,(2,11))
// (a,(2,12))
}
sortBy
sortBy`可以指定按照哪个字段来排序, `sortByKey`直接按照 Key 来排序
@Test
def sortBy(): Unit ={
val rdd=sc.parallelize(Seq(8,4,5,6,2,1,1,9))
val rdd2=sc.parallelize(Seq(("a",1),("b",3),("c",2)))
//rdd.sortBy(item =>item).collect().foreach(println(_))
rdd2.sortBy(item => item._2).collect().foreach(println(_))
rdd2.sortByKey().collect().foreach(println(_))
}
repartition
重新进行分区
@Test
def partitioning(): Unit ={
val rdd=sc.parallelize(Seq(1,2,3,4,5),2)
//println((rdd.repartition(5)).partitions.size) println(rdd.coalesce(5,true).partitions.size)
}
Spark学习进度-Transformation算子的更多相关文章
- Spark学习笔记--Transformation 和 action
转自:http://my.oschina.net/hanzhankang/blog/200275 附:各种操作的逻辑执行图 https://github.com/JerryLead/SparkInte ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度-实战测试
spark-shell 交互式编程 题目:该数据集包含了某大学计算机系的成绩,数据格式如下所示: Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure ...
- Spark学习之常用算子介绍
1. reduceByKey reduceByKey的作用对像是(key, value)形式的rdd,而reduce有减少.压缩之意,reduceByKey的作用就是对相同key的数据进行处理,最终每 ...
- Spark学习进度7-综合案例
综合案例 文件排序 解法: 1.读取数据 2.数据清洗,变换数据格式 3.从新分区成一个分区 4.按照key排序,返还带有位次的元组 5.输出 @Test def filesort(): Unit = ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
随机推荐
- SQL Server常用函数及命令
1.字符串函数 --ascii函数,返回字符串最左侧字符的ascii码值 SELECT ASCII('a') AS asciistr --ascii代码转换函数,返回指定ascii值对应的字符 SEL ...
- Springcloud之gateway配置及swagger集成
前言 关于引入gateway的好处我网上找了下: 性能:API高可用,负载均衡,容错机制. 安全:权限身份认证.脱敏,流量清洗,后端签名(保证全链路可信调用),黑名单(非法调用的限制). 日志:日志记 ...
- Tensorflow学习笔记No.10
多输出模型 使用函数式API构建多输出模型完成多标签分类任务. 数据集下载链接:https://pan.baidu.com/s/1JtKt7KCR2lEqAirjIXzvgg 提取码:2kbc 1.读 ...
- 写了两年的一本.NET书现在终于在北京最大的新华书店上架了,然而我却很难找到工作了。
两年前,有几个出版社的编辑在QQ上跟我联系写书的事情,好奇为什么出版社会找到我这样一个很普通的.NET技术人员,其中一个编辑说他们分析了很多博客园博主的文章阅读量和写作质量,觉得我的博客还是不错的.尽 ...
- SpringBoot如何利用Actuator来监控应用?
目录 Actuator是什么? 快速开始 引入依赖 yml与自动配置 主程序类 测试 Endpoints 官方列举的所有端点列表 启动端点 暴露端点 配置端点 发现页面 跨域支持 实现一个定义的端点 ...
- Linux安装Mycat1.6.7.4并实现Mysql数据库读写分离简单配置
1. Mycat简介 一个彻底开源的,面向企业应用开发的大数据库集群 支持事务.ACID.可以替代MySQL的加强版数据库 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群 一 ...
- 总结 Visual Studio 2019 发布以来 XAML 工具的改进
不知不觉,Visual Studio 2019 已经出到 16.8 和 16.9 Preview 了.虽然每次更新都林林总总地一大堆新功能和改进,但关于 XAML 的内容总是,always,每次都只有 ...
- ceph工作原理及安装
一.概述 Ceph是一个分布式存储系统,诞生于2004年,最早致力于开发下一代高性能分布式文件系统的项目.随着云计算的发展,ceph乘上了OpenStack的春风,进而成为了开源社区受关注较高的项目之 ...
- 听说特斯拉花了4个月研发出新ERP,然后很多人都疯了
欢迎关注微信公众号:sap_gui (ERP咨询顾问之家) 最近这件事儿在SAP圈里炒的挺火的,最主要是因为这几个关键词: 放弃SAP.4个月.自研ERP: 这则新闻一出来,很多人都兴高采烈,都要疯了 ...
- [GXYCTF2019]禁止套娃(无参RCE)
[GXYCTF2019]禁止套娃 1.扫描目录 扫描之后发现git泄漏 使用githack读取泄漏文件 <?php include "flag.php"; echo &quo ...