32、reduceByKey和groupByKey对比
一、groupByKey
1、图解
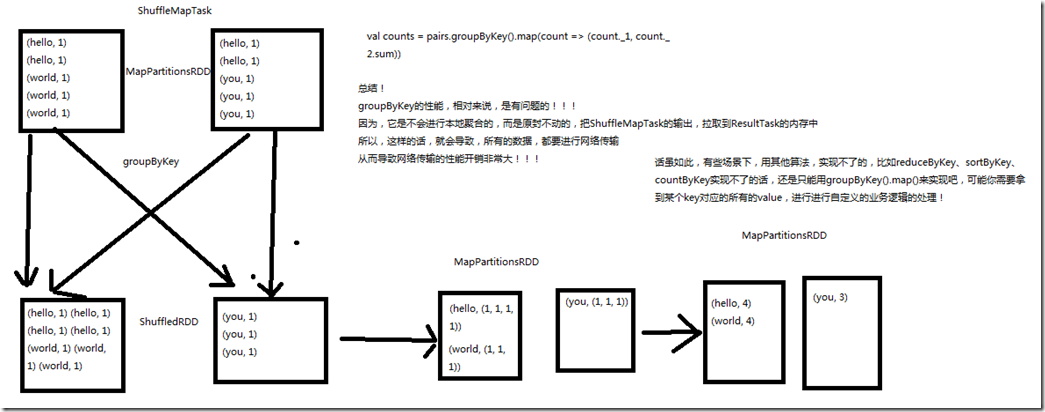
val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2.sum)) groupByKey的性能,相对来说,是有问题的; 因为,它是不会进行本地聚合的,而是原封不动的,把ShuffleMapTask的输出,拉取到ResultTask的内存中,所以这样的话,会导致,所有的数据,都要进行网络传输,
从而导致网络传输的性能开销很大; 但是,有些场景下,用其他算法实现不了的,比如reduceByKey,sortByKey,countByKey实现不了的话,还是只能用groupByKey().map()来实现,比如可能你需要拿到
某个key对应的所有的value,进行自定义的业务逻辑处理;
二、reduceByKey
1、图解
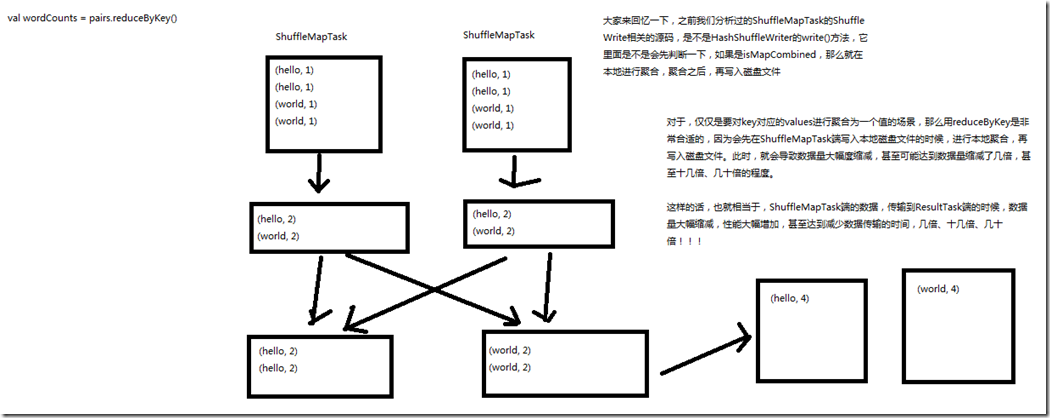
val counts = pairs.reduceByKey(_ + _) HashShuffleWriter的writer()方法,是先判断了一下,如果是isMapCombined,那么就在本地进行聚合,聚合之后,再写入磁盘文件; 对于,仅仅是要对key对应的values进行聚合为一个值的场景,用reduceByKey是非常合适的,因为会先在ShuffleMapTask端写入本地磁盘文件的时候,
进行本地聚合,再写入磁盘文件,此时,就会导致数据量大幅度缩减,甚至可能达到数据量缩减了几倍,甚至十几倍、几十倍的程度; 这样的话,也就相当于,ShuffleMapTask端的数据,传输到ReduceTasl端的数据,数据量大幅度缩减,性能大幅度增加,甚至达到减少数据量的时间,几倍、十几倍、几十倍; 如果能用reduceByKey,那就用reduceByKey,因为它会在map端,先进行本地combine,可以大大减少要传输到reduce端的数据量,减小网络传输的开销。
只有在reduceByKey处理不了时,才用groupByKey().map()来替代。
32、reduceByKey和groupByKey对比的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
- reduceByKey和groupByKey区别与用法
在spark中,我们知道一切的操作都是基于RDD的.在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式.这种格式很像Pyth ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- spark:reducebykey与groupbykey的区别
从源码看: reduceBykey与groupbykey: 都调用函数combineByKeyWithClassTag[V]((v: V) => v, func, func, partition ...
- scala flatmap、reduceByKey、groupByKey
1.test.txt文件中存放 asd sd fd gf g dkf dfd dfml dlf dff gfl pkdfp dlofkp // 创建一个Scala版本的Spark Context va ...
- spark新能优化之reduceBykey和groupBykey的使用
val counts = pairs.reduceByKey(_ + _) val counts = pairs.groupByKey().map(wordCounts => (wordCoun ...
- 【spark】常用转换操作:reduceByKey和groupByKey
1.reduceByKey(func) 功能: 使用 func 函数合并具有相同键的值. 示例: val list = List("hadoop","spark" ...
随机推荐
- html中实现某区域内右键自定义菜单
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- NIO(3)--Selector
Selector是NIO中的可选择Channel(SelectableChannel)的multiplexor.有两个拗口的概念,首先是SelectableChannel,在NIO里并非所有的Chan ...
- Mysql 一些命令记录
查看数据库当前的状态 show processlist; 查询表索引的基数 show index from LoadingPlan; 重新统计表格的索引基数 analyze table Loading ...
- 分布式系统session一致性解决方案
在单机系统中,不存在Session共享问题,但是在分布式系统中,我们必须实现session共享机制,使得多台应用服务器之间会话统一,如果不进行Session共享会出现数据不一致,比如:会导致请求落到不 ...
- js 数组的深度拷贝 的四种实现方法
首先声明本人资质尚浅,本文只用于个人总结.如有错误,欢迎指正.共同提高. --------------------------------------------------------------- ...
- UTF-8 中文编码范围
主流的匹配字符有两种 [\u4e00-\u9fa5]和[\u2E80-\u9FFF],后者范围更广,包括了日韩地区的汉字 import re pattern = re.compile("[\ ...
- MySQL Backup--Xtrabackup远程备份和限速备份
使用xbstream 备份到远程服务器 ##xbstream 备份到远程服务器 innobackupex \ --defaults-file="/export/servers/mysql/e ...
- shell脚本:Syntax error: Bad for loop variable错误解决方法(转)
Linux Mint中写了一个简单的shell脚本,利用for..do..done结构计算1+2+3......+100的值,结果执行"sh -n xxx.sh"检测语法时总是报错 ...
- atoi()和itoa()函数详解以及C语言实现
atoi()函数 atoi()原型: int atoi(const char *str ); 函数功能:把字符串转换成整型数. 参数str:要进行转换的字符串 返回值:每个函数返回 int 值,此值 ...
- jQuery和bootstrap
1. jQuery学习,搜索开发者网络: js学习: https://www.apeland.con/web/20/568 https://www.apeland.con/web/21 vue饿了么 ...