scala flatmap、reduceByKey、groupByKey
1、test.txt文件中存放
asd sd fd gf g
dkf dfd dfml dlf
dff gfl pkdfp dlofkp
// 创建一个Scala版本的Spark Context
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
// 读取我们的输入数据
val input = sc.textFile(inputFile)
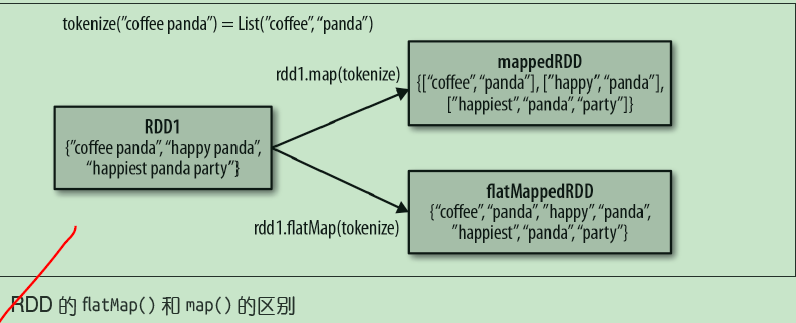
// 把它切分成一个个单词
val words = input.flatMap(line => line.split(" "))
//words为------------------
asd
sd
fd
gf
g
dkf
dfd
dfml
dlf
dff
gfl
pkdfp
dlofkp
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// 将统计出来的单词总数存入一个文本文件,引发求值
counts.saveAsTextFile(outputFile)
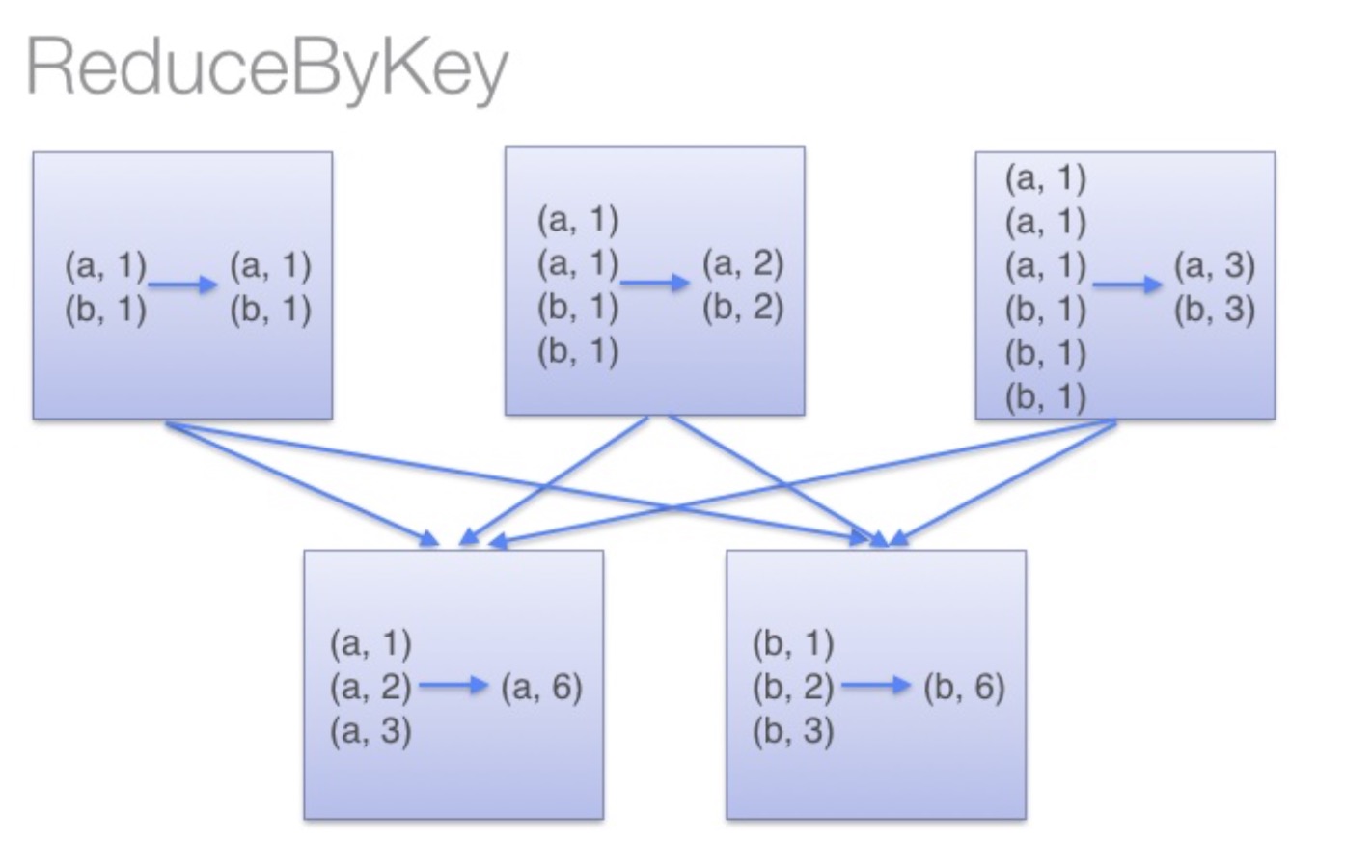
//reduceByKey 合并key计算

2、reduceByKey 合并key计算
按key求和
val rdd = sc.parallelize(List((“a”,2),(“b”,3),(“a”,3))) 合并key计算
val r1 = rdd.reduceByKey((x,y) => x + y) 输出结果如下 (a,5)
(b,3)
reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。
这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
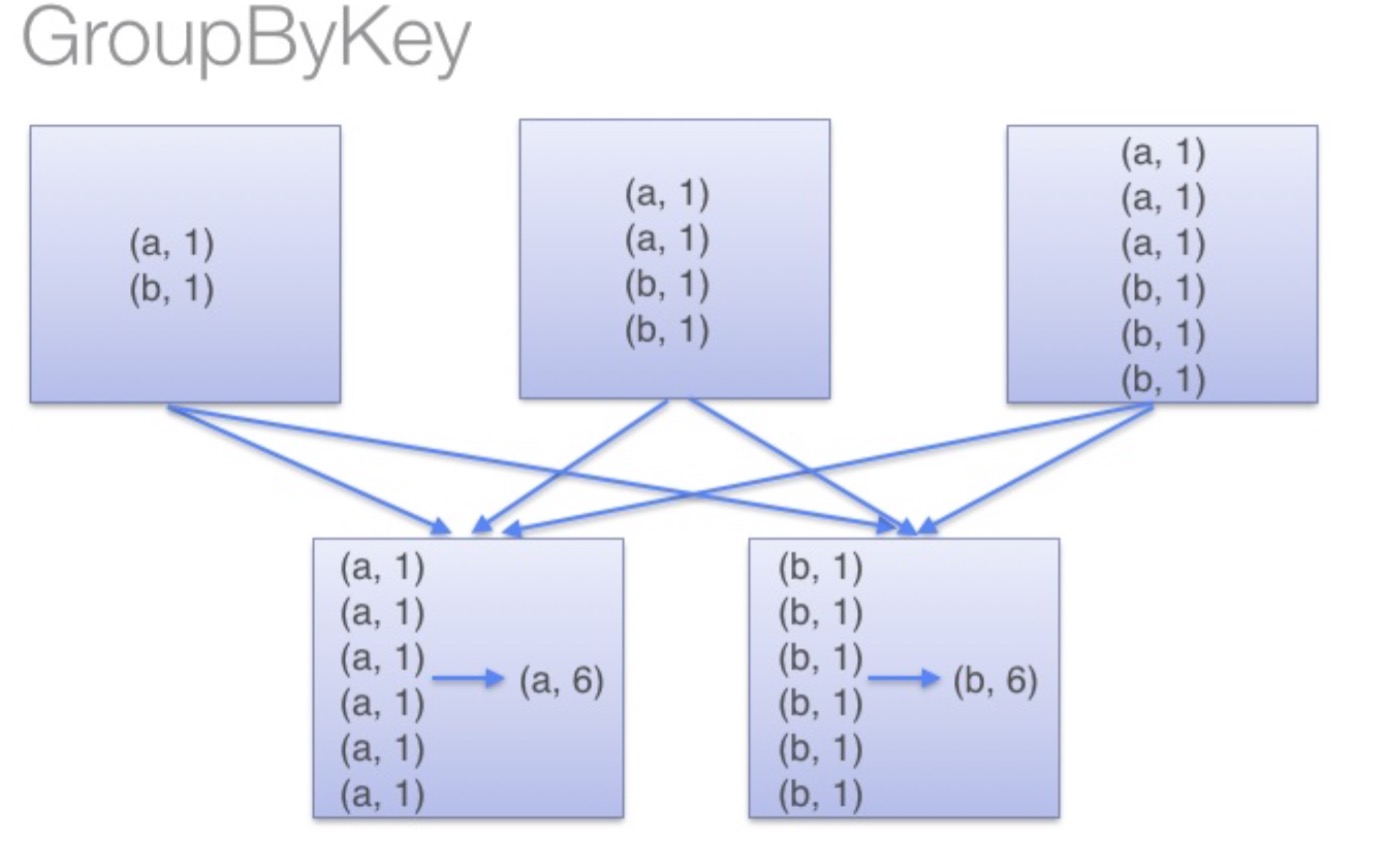
groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),
此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。
同时如果数据量十分大,可能还会造成OutOfMemoryError。
通过以上对比可以发现在进行大量数据的reduce操作时候建议使用reduceByKey。
不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题。




scala flatmap、reduceByKey、groupByKey的更多相关文章
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- 32、reduceByKey和groupByKey对比
一.groupByKey 1.图解 val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2 ...
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- spark提交命令 spark-submit 的参数 executor-memory、executor-cores、num-executors、spark.default.parallelism分析
转载:https://blog.csdn.net/zimiao552147572/article/details/96482120 nohup spark-submit --master yarn - ...
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- Spark中groupByKey、reduceByKey与sortByKey
groupByKey把相同的key的数据分组到一个集合序列当中: [("hello",1), ("world",1), ("hello",1 ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- 深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
下面来看看groupByKey和reduceByKey的区别: val conf = new SparkConf().setAppName("GroupAndReduce").se ...
随机推荐
- centos7下安装docker(15.7容器跨主机网络---calico)
Calico是一个纯三层的虚拟网络方案,Calico为每个容器分配一个IP,每个host都是router,把不同host的容器连接起来.与vxlan不同的是:calico不对数据包进行封装,不需要NA ...
- 在Ubuntu18.04上使用Anaconda
启动Anaconda Navigator 图形化界面 $ source ~/anaconda3/bin/activate root $ anaconda-navigator 查看目前的conda版本: ...
- 【js】鼠标跟随效果
1.实现思想 ①鼠标跟随效果,发生在鼠标移动的时候,故需要使用onmousemove事件 ②当页面内容多于1屏时,就需要考虑滚动距离的问题 ③想实现鼠标跟随的效果需要: 元素的left位置 = 鼠标当 ...
- 04 python 初学(数据类型)
数据类型: 数字: 整数 int (integer) python3 已经不区分整型和长整型了,都叫整型 浮点型 float 复数 complex 布尔: True False 字符串 ...
- day12--装饰器
定义(如何理解装饰器):装饰器本生是闭包函数的一种应用,是指在不改变原函数的情况下为原函数添加新的功能的一个函数.它把被装饰的函数作为外层函数的参数传入装饰器,通过闭包操作后返回一个替代版函数. 遵循 ...
- [MicroPython]TPYBoardv102播放音乐实例
0x00前言 前段时间看到TPYBoard的技术交流群(群号:157816561,)里有人问关于TPYBoard播放音乐的问题.最近抽空看了一下文档介绍,着手做了个实验.更多MicroPython的教 ...
- linux内存源码分析 - 内存池
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 内存池是用于预先申请一些内存用于备用,当系统内存不足无法从伙伴系统和slab中获取内存时,会从内存池中获取预留的 ...
- linux驱动编写之poll机制
一.概念 1.poll情景描述 以按键驱动为例进行说明,用阻塞的方式打开按键驱动文件/dev/buttons,应用程序使用read()函数来读取按键的键值.这样做的效果是:如果有按键按下了,调用该re ...
- DataHub使用小结(一)——概述
一.概念 1.什么是DataHub DataHub是流式数据(Streaming Data)的处理平台,提供对流式数据的发布(Publish),订阅(Subscribe)和分发功能, 可以轻松构建基于 ...
- UVA12253 简单加密法 Simple Encryption
这题到现在还是只有我一个人过?太冷门了吧,毕竟你谷上很少有人会去做往年ACM比赛的题 题面意思很简单,每次给出\(K_1\),让你求一个\(K_2\)满足\(K_1^{K_2}\equiv K_2(\ ...