新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装
下载IDEA并安装,可以百度一下免费文档。
2.IDEA Maven工程创建与配置
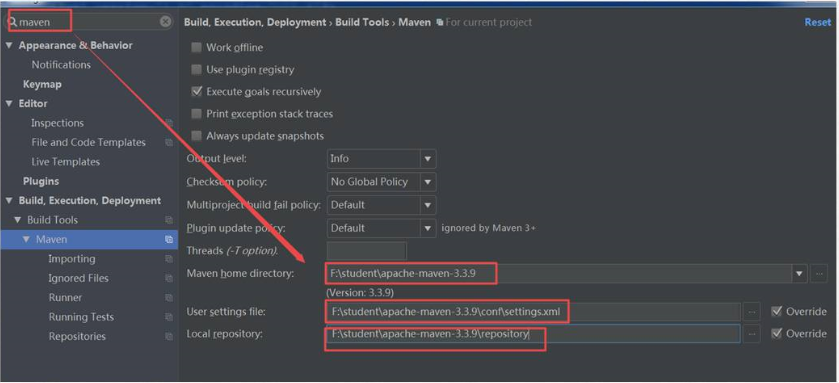
1)配置maven
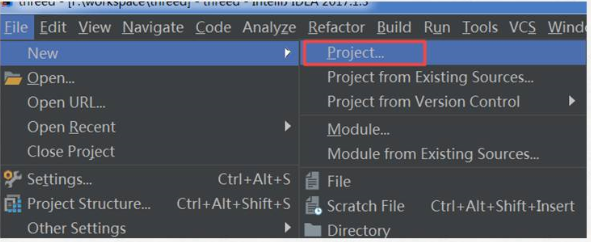
2)新建Project项目
3)选择maven骨架

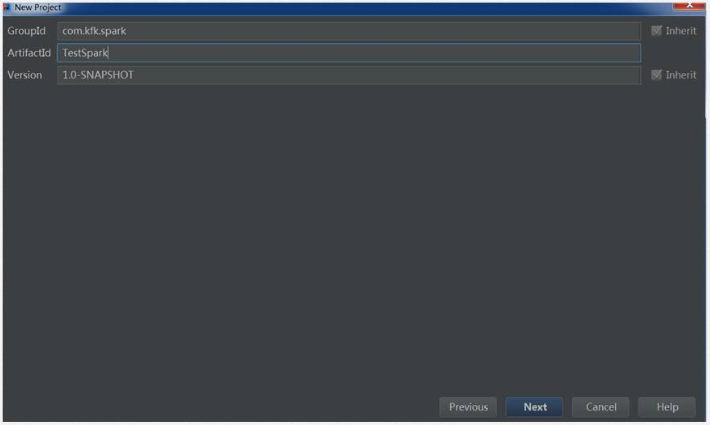
4)创建项目名称
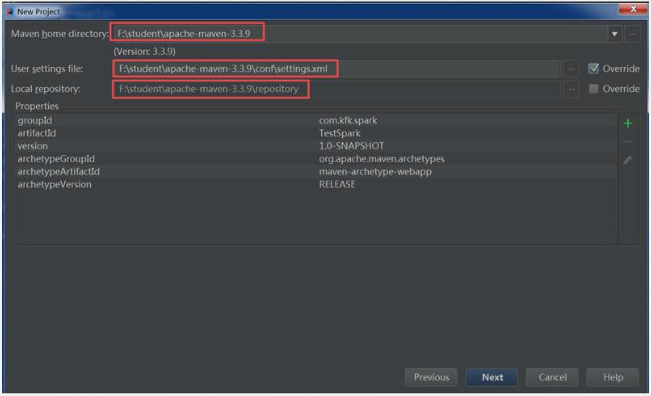
5)选择maven地址
6)生成maven项目
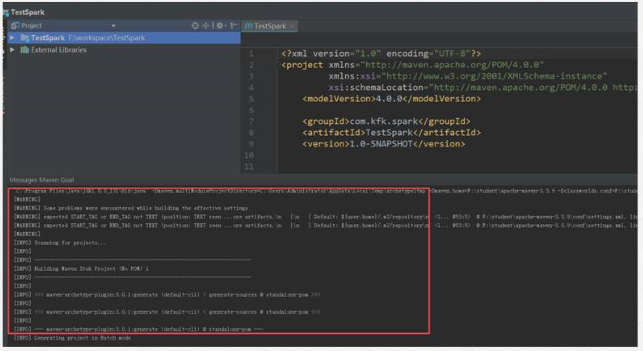
7)选择scala版本
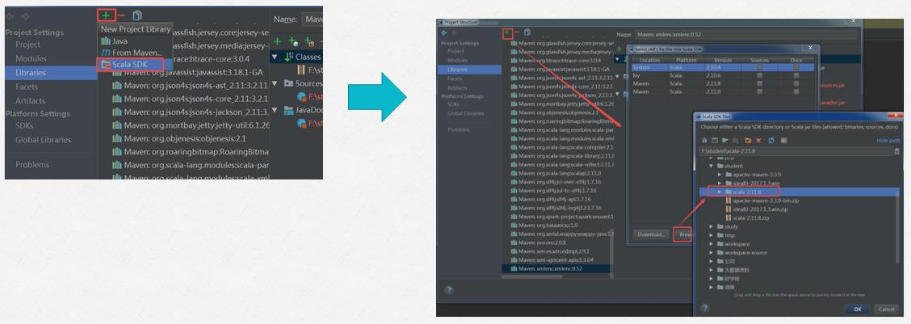
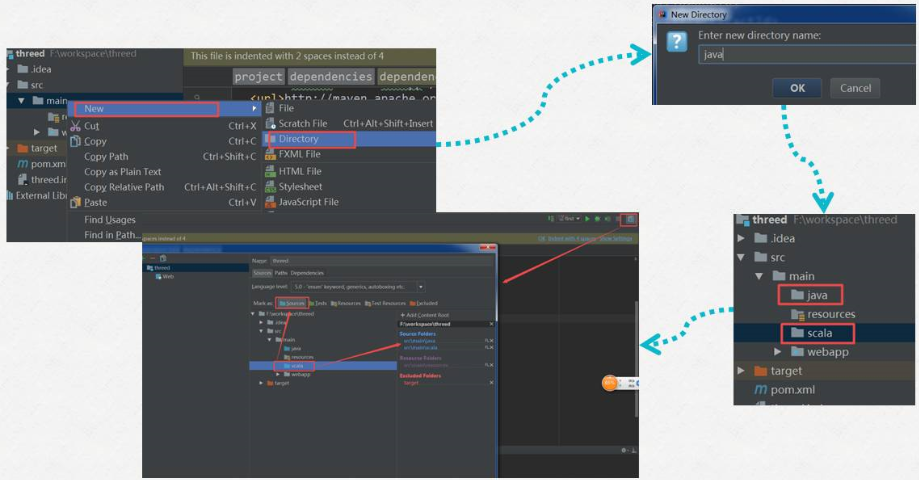
8)新建Java 和 scala目录
9)编辑pom.xml文件
a)地址一
b)地址二
3.开发Spark Application程序并进行本地测试
1)idea编写WordCount程序
package com.spark.test
import org.apache.spark.{SparkConf, SparkContext}
object MyScalaWordCout {
def main(args: Array[String]): Unit = {
//参数检查
if (args.length < 2) {
System.err.println("Usage: MyWordCout ")
System.exit(1)
}
//获取参数
val input=args(0)
val output=args(1)
//创建scala版本的SparkContext
val conf=new SparkConf().setAppName("myWordCount")
val sc=new SparkContext(conf)
//读取数据
val lines=sc.textFile(input)
//进行相关计算
val resultRdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//保存结果
resultRdd.saveAsTextFile(output)
sc.stop()
}
}
4.Spark Application程序打包
1)项目打jar包,参考之前讲过的项目打包方式
2)spark-submit方式提交作业
bin/spark-submit --master local[2] /opt/jars/sparkStu.jar hdfs://bigdata-pro01.kfk.com:9000/user/data/stu.txt
新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
随机推荐
- A Kill Cord for your Laptop
前言 昨晚在朋友圈看到国外一篇文章利用U盘锁笔记本电脑,刚好有一个坏的金士顿U盘,所以就折腾了一下. 准备 USB设备*1 Arch系统*1 走过的坑 因为systemd-udevd带起来的进程是ro ...
- Python的 REPL 模式
REPL Read Eval Print Loop读取,执行,输出,循环 在REPL环境中,你输入一句话,他就读取,执行,输出一个结果,所以也称为 交互式提示模式这是python代码最简单的方式,也揭 ...
- codeforces round#613
A题:输出n+1: B题: 题意:就是给n个数,a人全拿,b人拿连续的子段和,如果b人比a人大于等于的话输出NO,反之输出YES 思路:最大子段和,比赛的时候忘记 ll 和 字段和不是遇到负数就重置. ...
- RTT学习之SPI设备
SPI分为主.从.设备:具体又分标准SPI/DUAL SPI/QUAD SPI(用80字节的RAMrt_err_t rt_spi_take_bus(struct rt_spi_device *devi ...
- Java 基础--移位运算符
移位运算符就是在二进制的基础上对数字进行平移.按照平移的方向和填充数字的规则分为三种: <<(左移).>>(带符号右移)和>>>(无符号右移). 1.左移 按 ...
- 对FPM 模块进行参数优化!
Nginx 的 PHP 解析功能实现如果是交由 FPM 处理的,为了提高 PHP 的处理速度,可对FPM 模块进行参数跳转.FPM 优化参数:pm 使用哪种方式启动 fpm 进程,可以说 static ...
- 解决github访问慢和下载项目慢的问题
一.国内访问 GitHub 为什么很慢? GitHub的CDN域名遭到DNS污染,导致无法连接使用 GitHub 的加速分发服务器,才使得国内访问速度很慢. 二.如何解决 DNS 污染? 通过修改 ...
- Unable to instantiate Action, xxxAction, defined for 'xxx' in namespace '/'xxxAction解决方案
出现这个问题的原因主要有两个 1.如果项目没有使用Spring,则struts.xml配置文件中,这个action的class属性的路径没有写完整,应该是包名.类名 2.如果项目使用了Spring,那 ...
- http://www.yyne.com/python使用-urllib-quote-进行-url-编码小技巧/
http://www.yyne.com/python使用-urllib-quote-进行-url-编码小技巧/
- day1-4js算术运算符及类型转化
一,JS的运行环境 在html中使用JS,浏览器去解析 NodeJS环境内封装了JS的解析器 二,JavaScript的特点 1.客户端执行 2.执行顺序自上而下 3.弱类型(数据类型)语言 var ...