Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后。通过对训练数据进行学习。对比模型对 已知 数据的预测值和实际值 的差异。
错误的模型验证方法。
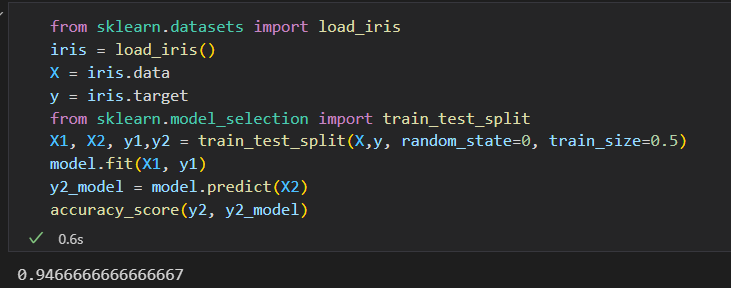
用同一套数据训练 和 评估 模型。 准确率总是100% 。
模型验证正确方法: 留出集。
从训练模型的数据中留出一部分。用这部分数据来验证模型的性能。
使用train_test_split 工具。
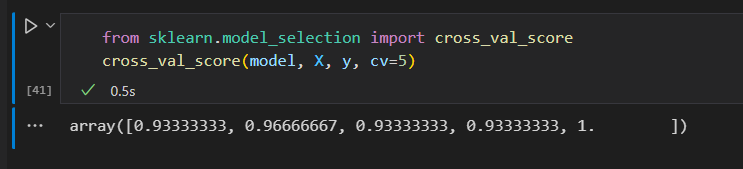
交叉检验
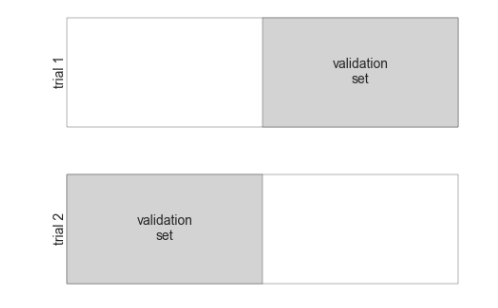
用留出集进行模型验证有一个缺点,就是模型失去了一部分训练机会。有一半数据都没有为模型训练做出贡献。
每个子集既是训练集,也是验证集。
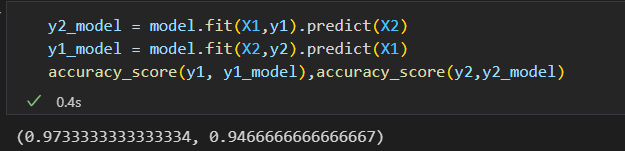
这就是俩轮交叉校验。 扩展一下,实现更多轮交叉校验。
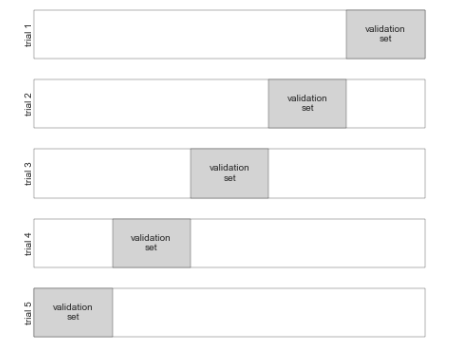
使用cross_val_score 可以非常简单的实现。
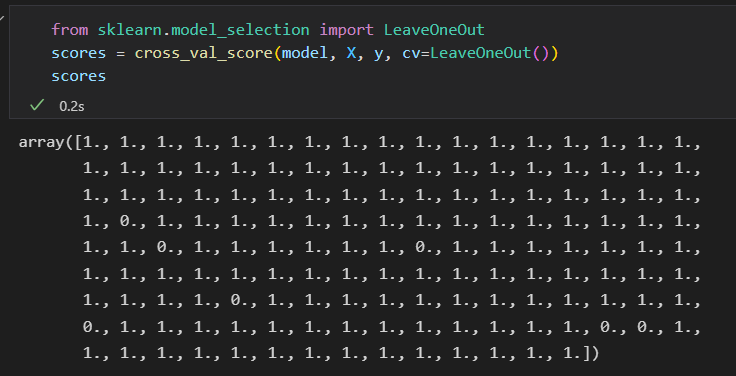
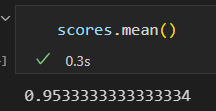
极端情况,只留一个样本左测试。这种交叉检验类型模型被称为 LOO leave-one-out .
选择最优模型
如何选择模型和超参数
偏差与方差的均衡
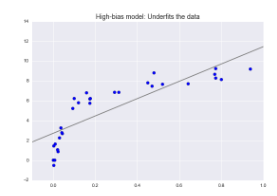
“最优模型”的问题 基本可以看出是找出偏差 与方差平衡点的问题。欠拟合
希望从数据中找到一条直线,但由于数据本质上比直线要复杂, 也就是说模型没有足够的灵活性来适应数据的所有特征。
也叫高偏差。
过拟合
希望用高阶多项式拟合数据,有足够的灵活性,完美地适应数据的所有特征。 十分准确的描述了训练数据,也过多的学习了数据的噪音。适应数据所有特征的同时,也适应了随机误差,
也叫高方差
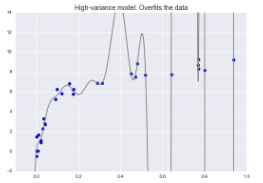
对于高偏差模型:模型在验证集的表现与训练集的表现类似
对于高方差模型:模型在验证集的表现远远不如训练集的表现。
如果我们有能力不断调整模型的复杂度,那么希望训练得分和验证得分如下
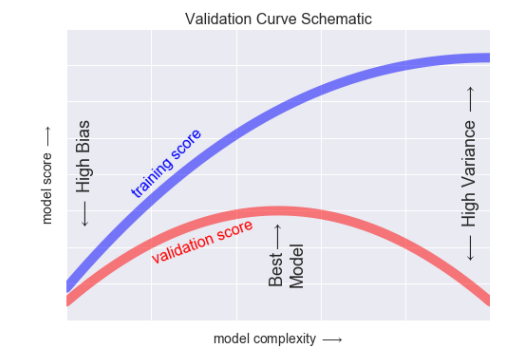
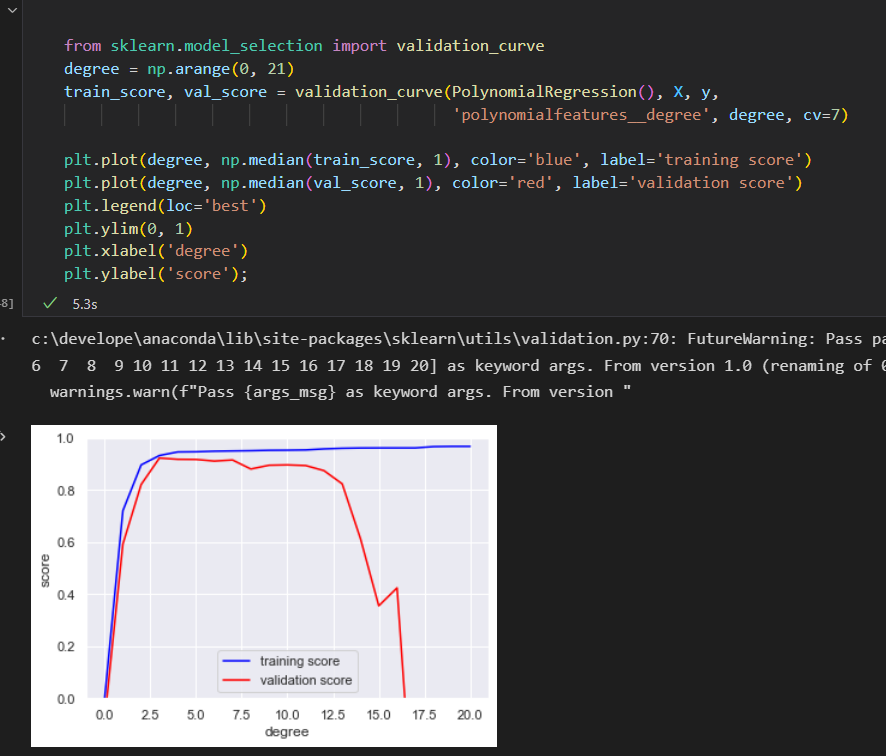
Scikit-Learn 验证曲线
用交叉校验计算一个模型的验证曲线。 用多项式 回归 模型。 多项式的次数是一个可调参数。
一次多项式: y = ax + b
三次多项式: y = ax^3 + bx^2 + cx + d
在Scikit-Learn 中,可以用一个带多项式预处理器 的 简单线性回归模型实现。
用一个管道命令 来组合 这 俩种操作。
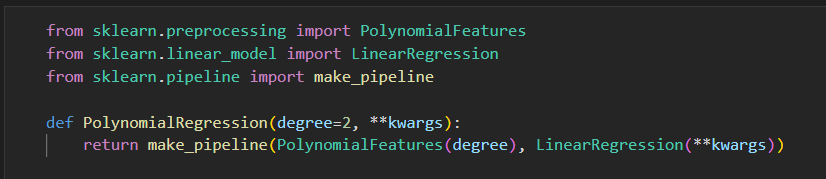
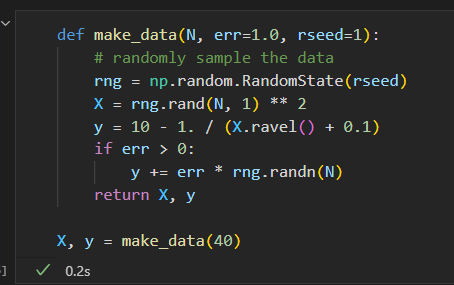
创建一些数据 给模型 拟合
数据可视化,将不同次数的多项式拟合曲线画出来
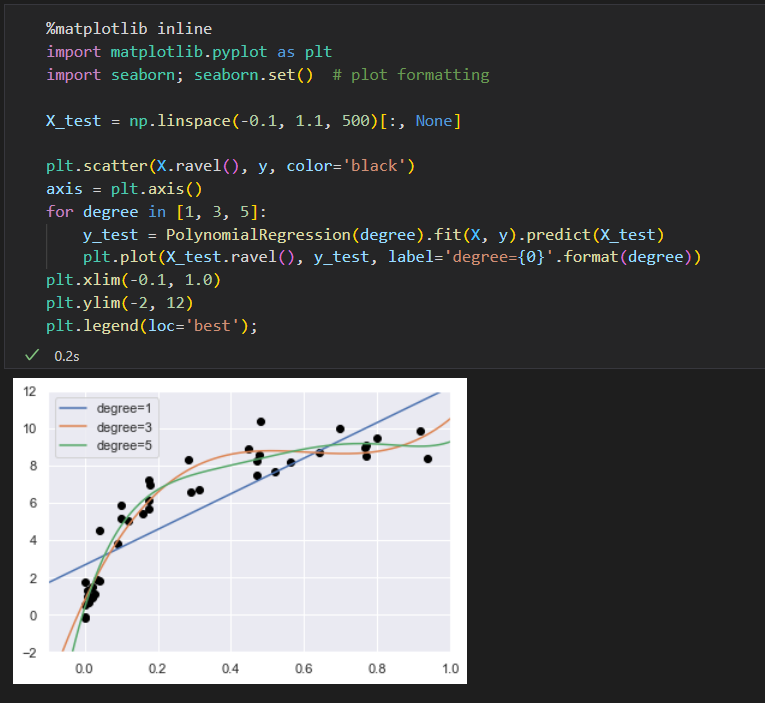
问题:究竟多项式的次数是多少,才能在 偏差 和 方差 间达到平衡。
可以通过可视化验证曲线来找答案。
利用Scikit-Learn的 validation_curve函数 可以非常简单的实现。 只提供模型、数据、参数名称和验证范围信息。
函数就会 自动计算验证范围 内的训练得分 和 验证得分。
学习曲线
英雄模型复杂度的另一个重要因素就是 最优模型 往往受到 训练数据量 的影响。
学习曲线的特征:
- 特定复杂度的模型 对较小的数据集 容易 过拟合:此时 训练得分较高,验证得分较低。
- 特定复杂度的模型 对较大的数据集 容易 欠拟合:随着数据的增大,训练得分会不断降低, 验证得分会不断升高。
- 模型的验证集得分永远不会高于 训练集得分: 俩条曲线一直在靠近,不会交叉
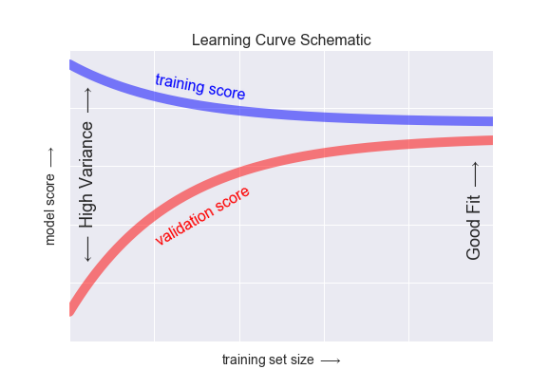
学习曲线最重要的特征,随着训练样本数量的增加,分数会收敛到定值,因此,一旦训练数据已经使模型收件,再增加训练数据 也无济于事, 只能通过换模型。
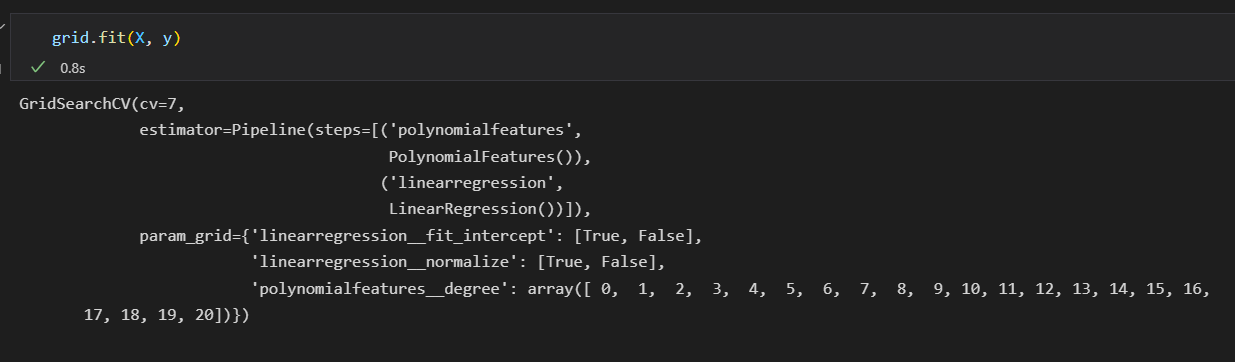
验证时间:网格搜索
Scikit-Learn在grid_search提供了一个自动化工具来寻找最优多项式的回归模型。
GridSearchCV元评估器来设置这些参数。
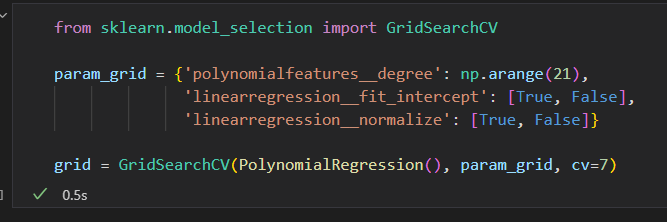
然后调用fit()方法在每个网格上拟合模型。并同时记录每个点的得分
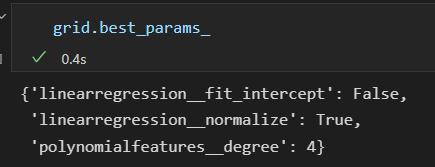
获取最优参数
Python数据科学手册-机器学习之模型验证的更多相关文章
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
随机推荐
- sql server 开启一个事务
开启事务,回滚 /*============================================================== */ /* Date : 2020年11月18日 11 ...
- Redis主从复制+Keepalived+VIP漂移实现HA高可用技术之详细教程
1.大家可以先看我的单台Redis安装教程,链接在此点击Redis在CentOS for LInux上安装详细教程 2.第一台redis配置,是正常配置.作为MASTER主服务器,第二台redis的配 ...
- 2m高分辨率土地利用分类数据
数据下载链接:百度云下载链接 土地利用数据是在根据影像光谱特征,结合野外实测资料,同时参照有关地理图件,对地物的几何形状,颜色特征.纹理特征和空间分布情况进行分析,建立统一解译标志的基础之上,依据多源 ...
- 渗透测试(PenTest)基础指南
什么是渗透测试? 渗透测试(Penetration Test,简称为 PenTest),是指通过尝试利用漏洞攻击来评估IT基础设施的安全性.这些漏洞可能存在于操作系统.服务和应用程序的缺陷.不当配置或 ...
- 大数据--Hive的安装以及三种交互方式
1.3 Hive的安装(前提是:mysql和hadoop必须已经成功启动了) 在之前博客中我有记录安装JDK和Hadoop和Mysql的过程,如果还没有安装,请先进行安装配置好,对应的随笔我也提供了百 ...
- 如何创建一个带诊断工具的.NET镜像
现阶段的问题 现在是云原生和容器化时代,.NET Core对于云原生来说有非常好的兼容和亲和性,dotnet社区以及微软为.NET Core提供了非常方便的镜像容器化方案.所以现在大多数的dotnet ...
- python编程思想及对象与类
目录 编程思想 面向对象 面向过程 对象与类的概念 对象与类的创建 对象的实例化方法-独有数据 编程思想 1.面向对象 1.1. 面向对象前戏 案例:人狗大战 # 需求:人狗大战# 1.'创造'出人和 ...
- Java面试题(六)--Redis
1 Redis基础篇 1.简单介绍一下Redis优点和缺点? 优点: 1.本质上是一个 Key-Value 类型的内存数据库,很像memcached 2.整个数据库统统加载在内存当中进行操作,定期通过 ...
- Java多线程超级详解(只看这篇就够了)
多线程能够提升程序性能,也属于高薪必能核心技术栈,本篇会全面详解Java多线程.@mikechen 主要包含如下几点: 基本概念 很多人都对其中的一些概念不够明确,如同步.并发等等,让我们先建立一个数 ...
- LuoguP4165 [SCOI2007]组队
化式子,然后两个指针平\(A\)过去 #include <cstring> #include <cstdio> #include <algorithm> #incl ...