【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一、前述
视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务。这一任务的定义如下: A VQA system takes as input an image and a free-form, open-ended, natural-language question about the image and produces a natural-language answer as the output[1]。 翻译为中文:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是给定的图片进行问答。
VQA系统需要将图片和问题作为输入,结合这两部分信息,产生一条人类语言作为输出。针对一张特定的图片,如果想要机器以自然语言来回答关于该图片的某一个特定问题,我们需要让机器对图片的内容、问题的含义和意图以及相关的常识有一定的理解。VQA涉及到多方面的AI技术(图1):细粒度识别(这位女士是白种人吗?)、 物体识别(图中有几个香蕉?)、行为识别(这位女士在哭吗?)和对问题所包含文本的理解(NLP)。综上所述,VQA是一项涉及了计算机视觉(CV)和自然语言处理(NLP)两大领域的学习任务。它的主要目标就是让计算机根据输入的图片和问题输出一个符合自然语言规则且内容合理的答案。
二、具体步骤
2.1 第一步,生成答案
2.2 第二步,处理输⼊源数据
2.2.1 处理输⼊源数据:图⽚
卷积CNN结合VGG-16模型
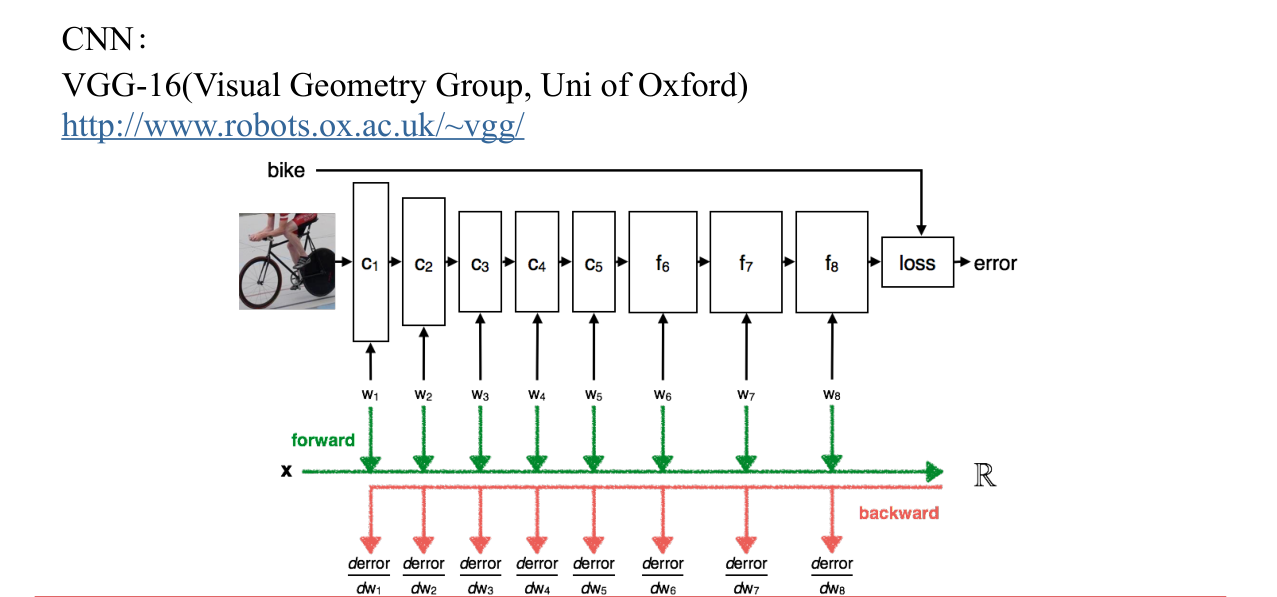
VGG-16的标准构造 (keras)
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
if weights_path:
model.load_weights(weights_path)
return model
2.2.2 处理输⼊源数据:⽂字
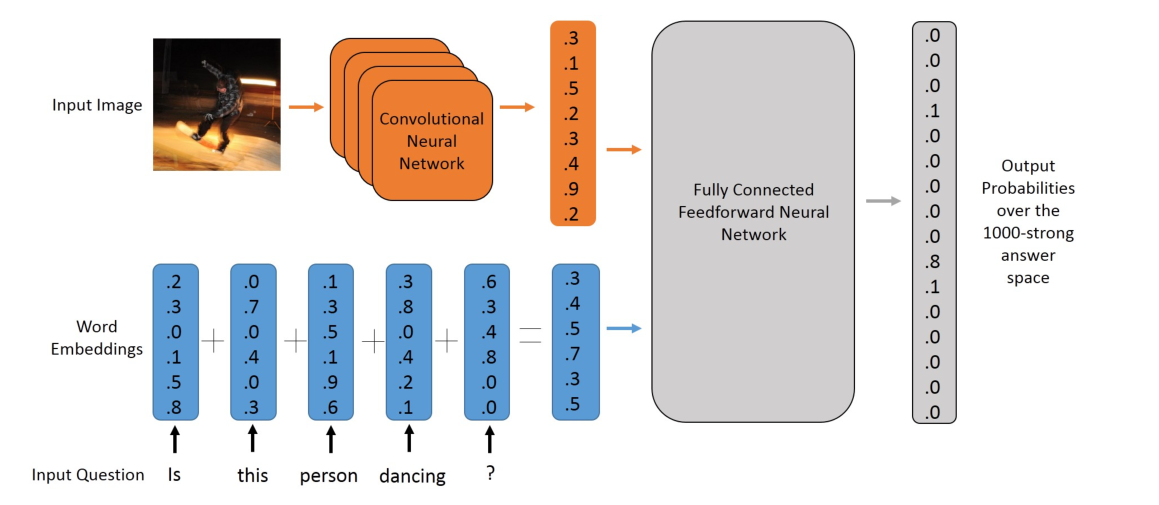
2.3 第三步, 选取VQA模型-MLP
2.3.1 选取VQA模型-MLP
2.3.2 选取VQA模型-LSTM

【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用的更多相关文章
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks 2018-05-15 20:15:03 Motivation: 虽然 VQA 已经取得 ...
- 第八讲_图像问答Image Question Answering
第八讲_图像问答Image Question Answering 课程结构 图像问答的描述 具备一系列AI能力:细分识别,物体检测,动作识别,常识推理,知识库推理..... 先要根据问题,判断什么任务 ...
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- VQA视觉问答基础知识
本文记录简单了解VQA的过程,目的是以此学习图像和文本的特征预处理.嵌入以及如何设计分类loss等等. 参考资料: https://zhuanlan.zhihu.com/p/40704719 http ...
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结 笔记不能简单的抄写文中 ...
- 【论文小综】基于外部知识的VQA(视觉问答)
我们生活在一个多模态的世界中.视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知.作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题 ...
随机推荐
- STL--multiset用法
multiset: multiset<int>s; 定义正向迭代器与正向遍历: multiset<int>::iterator it; for(it=s.begin();it! ...
- BZOJ_3942_[Usaco2015 Feb]Censoring_KMP
BZOJ_3942_[Usaco2015 Feb]Censoring_KMP Description 有一个S串和一个T串,长度均小于1,000,000,设当前串为U串,然后从前往后枚举S串一个字符一 ...
- Python Django 2.2登录功能_2
#Now 让我们继续对上篇的登录进行操作 #对于csrf,以后再开篇章记录 #修改index.html <form method="post" action="/l ...
- js默认参数实现方法
function simue (){ var a = arguments[0] ? arguments[0] : 1; var b = arguments[1] ? arguments[1] : 2; ...
- 字符串、List集合、数组互转
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 24.0px "Songti SC"; color: #3933ff } p.p2 { ...
- 单例模式--java代码实现
单例模式 单例模式,顾名思义,在程序运行中,实例化某个类时只实例化一次,即只有一个实例对象存在.例如在古代,一个国家只能有一个皇帝,在现代则是主席或总统等. 在Java语言中单例模式有以下实现方式 1 ...
- Vue.js 牛刀小试(持续更新~~~)
一.前言 这个系列的文章开始于今年9月从上一家公司辞职后,在找工作的过程中,觉得自己应该学习一些新的东西,从前几章的更新日期也可以看出,中间隔了很长的时间,自己也经历了一些事情,既然现在已经稳定了,就 ...
- H5单张、多张图片保存续篇
前言 这篇是接上篇内容.还没看的可以看H5单张.多张图片上传这篇文章预热. 图片入库 本章我们就来看看如何让多种图片保存至数据库中.数据库:mysql 后端:.NET Core 我们回顾一下上篇我 ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- NumPy 超详细教程(1):NumPy 数组
系列文章地址 NumPy 最详细教程(1):NumPy 数组 NumPy 超详细教程(2):数据类型 NumPy 超详细教程(3):ndarray 的内部机理及高级迭代 文章目录 Numpy 数组:n ...