Spark Shuffle之Hash Shuffle
源文件放在github,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/hash-shuffle.md
正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍hash shuffle。
spark在1.2前默认为hash shuffle(spark.shuffle.manager = hash),但hash shuffle也经历了两个发展阶段。
第一阶段
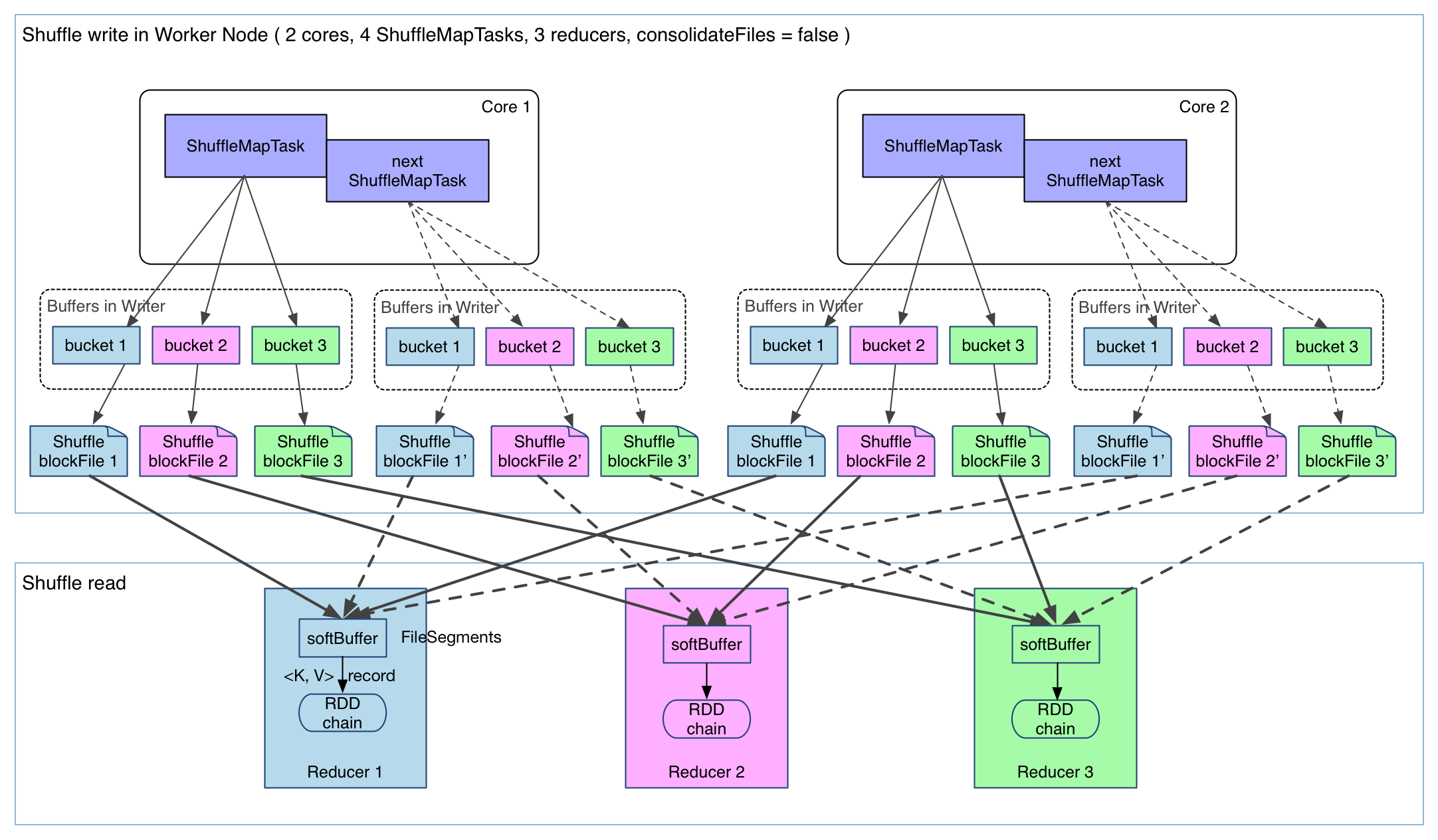
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
第二阶段
这样的实现很简单,但有几个问题:
1 产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
2 缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores * R * 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
spark.shuffle.consolidateFiles默认为false,如果为true,shuffleMapTask输出文件可以被合并。如图
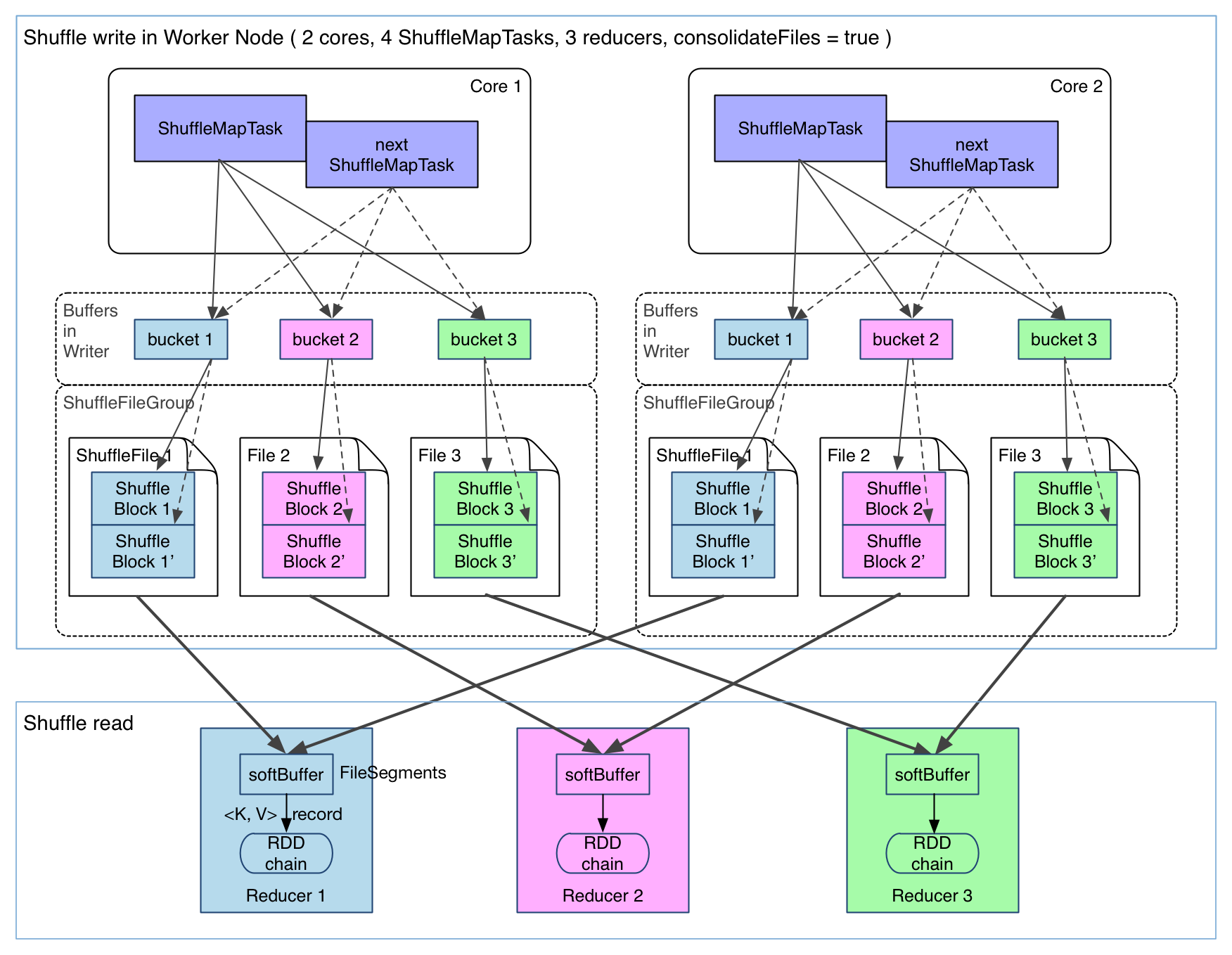
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i',每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores * R。但是缓存空间占用大还没有解决。
总结
优点
- 快-不需要排序,也不需要维持hash表
- 不需要额外空间用作排序
- 不需要额外IO-数据写入磁盘只需一次,读取也只需一次
缺点
- 当partitions大时,输出大量的文件(cores * R),性能开始降低
- 大量的文件写入,使文件系统开始变为随机写,性能比顺序写要降低100倍
- 缓存空间占用比较大
当然,数据经过序列化、压缩写入文件,读取的时候,需要反序列化、解压缩。reduce fetch的时候有一个非常重要的参数spark.reducer.maxSizeInFlight,这里用 softBuffer 表示,默认大小为 48MB。一个 softBuffer 里面一般包含多个 FileSegment,但如果某个 FileSegment 特别大的话,这一个就可以填满甚至超过 softBuffer 的界限。如果增大,reduce请求的chunk就会变大,可以提高性能,但是增加了reduce的内存使用量。
如果排序在reduce不强制执行,那么reduce只返回一个依赖于map的迭代器。如果需要排序, 那么在reduce端,调用ExternalSorter。
参考文献
Spark Shuffle之Hash Shuffle的更多相关文章
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- spark性能调优(二) 彻底解密spark的Hash Shuffle
装载:http://www.cnblogs.com/jcchoiling/p/6431969.html 引言 Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-B ...
- 研究一下Spark Hash Shuffle 和 SortShuffle 原理机制
研究一下Spark Hash Shuffle 和 SortShuffle 原理机制研究一下Spark Hash Shuffle 和 SortShuffle 原理机制研究一下Spark Hash Shu ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- Spark Shuffle之Sort Shuffle
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正.原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowled ...
- Spark性能优化:shuffle调优
调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行 ...
- Spark技术内幕:Shuffle Map Task运算结果的处理
Shuffle Map Task运算结果的处理 这个结果的处理,分为两部分,一个是在Executor端是如何直接处理Task的结果的:还有就是Driver端,如果在接到Task运行结束的消息时,如何对 ...
随机推荐
- 一图看懂JVM,JRE,JDK的关系
- FreeRTOS内存管理
简介 Freertos的内存管理分别在heap_1.c,heap_2.c,heap_3.c,heap_4.c,heap_5.c个文件中,选择合适的一种应用于嵌入式项目中即可. 本文的图片中 红色部分B ...
- 【blockly教程】第一章 Google Blockly教学应用手册
1.1 Google Blockly概述 美国计算科学教育一直认为计算机作为当今各个领域的基础技术工具,有必要让学生尽早的了解和学习计算机工作原理,理解基础的编程思维.在2006年周以真教授提出计算思 ...
- Webservice返回SoapHeader
Webservice在请求中加入自定义的SoapHeader,比较常用的场景是在SoapHeader中携带用户登陆信息,由服务端进行身份验证.今天遇到一个需求,除了在请求时要携带SoapHeader外 ...
- 20155308 2016-2017-2《Java程序设计》课堂实践项目
20155308 2016-2017-2<Java程序设计>课堂实践项目 在java.lang包中有String.split()方法,返回是一个数组 我在应用中用到一些,给大家总结一下,仅 ...
- 15、Java并发编程:Callable、Future和FutureTask
Java并发编程:Callable.Future和FutureTask 在前面的文章中我们讲述了创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口. 这2种方式都有一 ...
- 在Centos7下安装与部署.net core
在Centos7下安装与部署.net core 2018年02月28日 19:36:16 阅读数:388 个人安装流程,参照文档 https://www.cnblogs.com/Burt/p/6566 ...
- 前端--初识jQuery
jQuery 一.jQuery介绍 1.jQuery是一个轻量级.兼容多浏览器的js库. 2.jQuery使用户能够更方便地处理HTML Document,Events,实现动画效果,方便的进行Aja ...
- C# TTS-文本转语音
System.Speech 命名空间包含支持语音识别的类型,你可以从Visual Studio很方便的添加相关组件的引用. System.Speech相关介绍:https://msdn.microso ...
- gitlab runner 填坑记
一.Gitlab Runner CI/CD 错误: Couldn't connect to Docker daemon at http+docker://localhost - is it runn ...