写论文的第四天 Spark安装 使用sparkshell
Spark分布式安装
Spark安装注意:需要和本机的hadoop版本对应
前往spark选择自己相对应的版本下载之后进行解压
命令:tar –zxf spark-2.4.0-bin-hadoop2.6.tgz –C /usr/local
配置spark分布式,修改两个主要配置文件 spark-env.sh.template slaves.template slaves 留存备份
命令: cp spark-env.sh.template spark-env.sh
命令:cp slaves.template slaves
配置spark-env.sh
#SPARK
export JAVA_HOME=/usr/local/jdk1.8.0_192
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_PID_DIR=/usr/local/hadoop/pids
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置slaves
删除localhost 增加 node1 node2
将配置好的spark复制到子节点
命令:scp –r /usr/local/spark node1:/usr/local
scp –r /usr/local/spark node2:/usr/local
尝试启动spark
命令:/usr/local/spark/sbin/start-all.sh

进入spark-shell查看spark启动是否成功
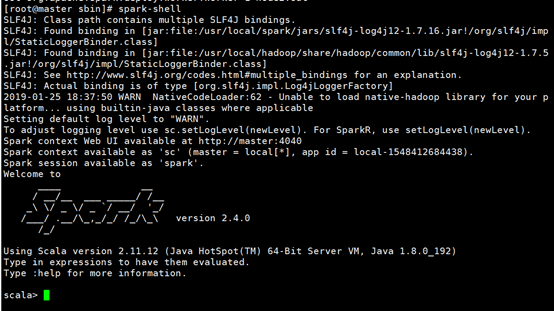
启动正常
为spark配置环境变量
命令:vim /etc/profile
#set SPARK_HOME
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
命令:source /etc/profile使配置生效
写论文的第四天 Spark安装 使用sparkshell的更多相关文章
- 写论文的第五天 hive安装
Hive的安装和使用 我们的版本约定: JAVA_HOME=/usr/local /jdk1.8.0_191 HADOOP_HOME=/usr/local/hadoop HIVE_HOME=/usr/ ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- (转)Spark安装与学习
摘要:Spark是继Hadoop之后的新一代大数据分布式处理框架,由UC Berkeley的Matei Zaharia主导开发.我只能说是神一样的人物造就的神器,详情请猛击http://www.spa ...
- spark安装mysql与hive
第一眼spark安装文件夹lib\spark-assembly-1.0.0-hadoop2.2.0.jar\org\apache\spark\sql下有没有hive文件夹,假设没有的话先下载支持hiv ...
- Latex 论文elsevier,手把手如何用Latex写论文
这几天在开始写论文,准备发的是elsevier,这个网站的instruction有问题,下载的东西基本上好多的错误,所以我就写博客记录. 首先看下:https://www.elsevier.com/a ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装 一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh ...
- Spark学习之Spark安装
Spark安装 spark运行环境 spark是Scala写的,运行在jvm上,运行环境为java7+ 如果使用Python的API ,需要使用Python2.6+或者Python3.4+ Spark ...
- Spark安装和简单示例
spark的安装 先到官网下载安装包 注意第二项要选择和自己hadoop版本相匹配的spark版本,然后在第4项点击下载.若无图形界面,可用windows系统下载完成后传送到centos中. 本例中安 ...
随机推荐
- java学习笔记(基础篇)—java数组
一:什么是数组,什么时候使用数组? 数组是用来保存一组数据类型相同的元素的有序集合,数组中的每个数据称为元素.有序集合可以按照顺序或者下标取数组中的元素. 在Java中,数组也是Java对象.数组中的 ...
- Excel催化剂开源第37波-音视频文件元数据提取(分辨率,时长,采样率等)
上一篇提到图片元信息Exif的提取,当然还有一类音视频文件,也同样存储着许多宝贵的元数据,那就开源到底呗,虽然自己找寻过程也是蛮艰辛坎坷的,大家看后有收获,只求多多传播下,让前人的工作可以更有价值. ...
- 踩坑 Spring Cloud Hystrix 线程池队列配置
背景: 有一次在生产环境,突然出现了很多笔还款单被挂起,后来排查原因,发现是内部系统调用时出现了Hystrix调用异常.在开发过程中,因为核心线程数设置的比较大,没有出现这种异常.放到了测试环境,偶尔 ...
- [leetcode] 147. Insertion Sort List (Medium)
原题 别人的思路 非常简洁 function ListNode(val) { this.val = val; this.next = null; } /** * @param {ListNode} h ...
- STL 优先队列 用法
今天做题用到了优先队列 对它的用法还不是很熟悉 现在整理一下. 需要的库 #include<queue> using namespace std; 不过我都用bits/stdc++.h.. ...
- 今天来聊Java ClassLoader
背景 类加载机制作为一个高频的面试题经常会在面试中被问到,前几天一个电话面试就问到,之前有了解过,但是没有梳理成自己的体系,所以说的有点凌乱,今天花点时间整理一下,分享给大家同时自己也好好梳理一下,顺 ...
- 用maven工具管理web项目的错误记录:org.springframework.beans.factory.xml.XmlBeanDefinitionStoreException
运行异常报告日志: 严重: Context initialization failedorg.springframework.beans.factory.xml.XmlBeanDefinitionSt ...
- 优化 Ubuntu
优化Ubuntu 1. 更换 apt 源 echo 'deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe mul ...
- 脱壳系列_2_IAT加密壳_详细版_解法1_包含脚本
1 查看壳程序信息 使用ExeInfoPe 分析: 发现这个壳的类型没有被识别出来,Vc 6.0倒是识别出来了,Vc 6.0的特征是 入口函数先调用GetVersion() 2 用OD找OEP 拖进O ...
- 常用GDB命令行调试命令
po po是print-object的简写,可用来打印所有NSObject对象.使用举例如下: (gdb) po self <LauncherViewController: 0x552c570& ...