自然语言18.1_Named Entity Recognition with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)

QQ:231469242
欢迎nltk爱好者交流
https://www.pythonprogramming.net/named-entity-recognition-nltk-tutorial/?completed=/chinking-nltk-tutorial/
Named Entity Recognition with NLTK
命名实体(Named Entity)类别识别
This is a temporary script file.
""" import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer sentence="Bush is a pig in WhiteHouse in America."
words=nltk.word_tokenize(sentence)
tagged=nltk.pos_tag(words)
nameEnt=nltk.ne_chunk(tagged,binary=False) nameEnt.draw()
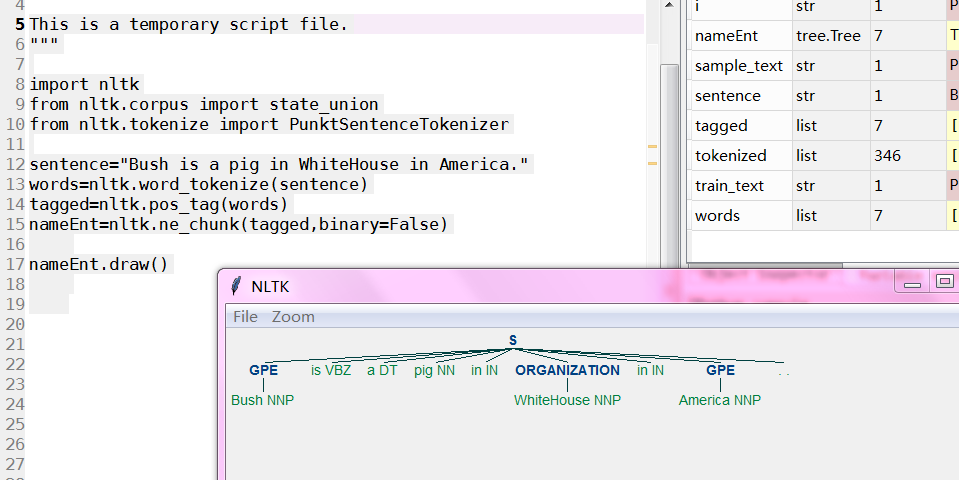
This is a temporary script file.
""" import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer train_text=state_union.raw("2005-GWBush.txt")
sample_text=state_union.raw("2006-GWBush.txt") custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#分句
tokenized=custom_sent_tokenizer.tokenize(sample_text) for i in tokenized[0:5]:
words=nltk.word_tokenize(i)
tagged=nltk.pos_tag(words)
nameEnt=nltk.ne_chunk(tagged,binary=False)
#print(nameEnt)
nameEnt.draw()
nameEnt=nltk.ne_chunk(tagged,binary=True)

nameEnt=nltk.ne_chunk(tagged,binary=False)

One of the most major forms of chunking in natural language processing is called "Named Entity Recognition." The idea is to have the machine immediately be able to pull out "entities" like people, places, things, locations, monetary figures, and more.
This can be a bit of a challenge, but NLTK is this built in for us. There are two major options with NLTK's named entity recognition: either recognize all named entities, or recognize named entities as their respective type, like people, places, locations, etc.
Here's an example:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=True)
namedEnt.draw()
except Exception as e:
print(str(e)) process_content()
Here, with the option of binary = True, this means either something is a named entity, or not. There will be no further detail. The result is:
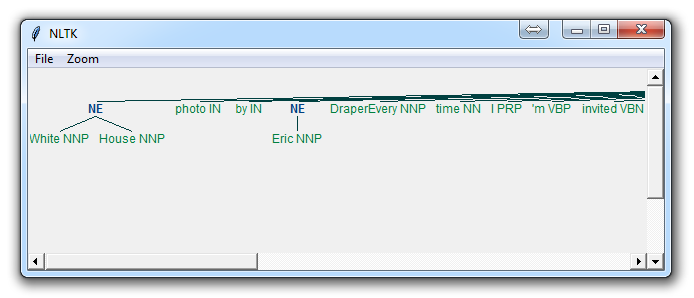
If you set binary = False, then the result is:
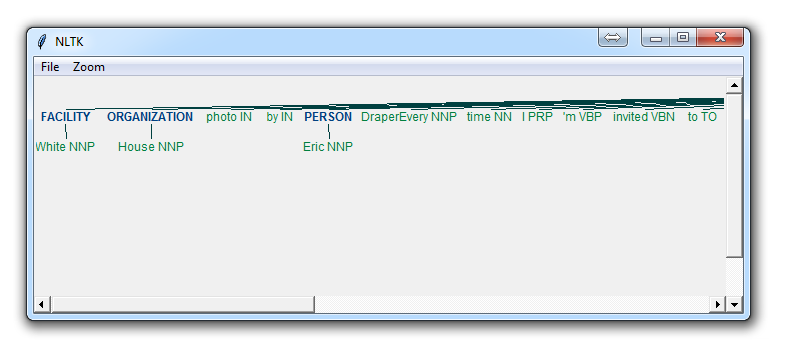
Immediately, you can see a few things. When Binary is False, it picked up the same things, but wound up splitting up terms like White House into "White" and "House" as if they were different, whereas we could see in the binary = True option, the named entity recognition was correct to say White House was part of the same named entity.
Depending on your goals, you may use the binary option how you see fit. Here are the types of Named Entities that you can get if you have binary as false:
ORGANIZATION - Georgia-Pacific Corp., WHO
PERSON - Eddy Bonte, President Obama
LOCATION - Murray River, Mount Everest
DATE - June, 2008-06-29
TIME - two fifty a m, 1:30 p.m.
MONEY - 175 million Canadian Dollars, GBP 10.40
PERCENT - twenty pct, 18.75 %
FACILITY - Washington Monument, Stonehenge
GPE - South East Asia, Midlothian
Either way, you will probably find that you need to do a bit more
work to get it just right, but this is pretty powerful right out of the
box.
In the next tutorial, we're going to talk about something similar to stemming, called lemmatizing.

自然语言18.1_Named Entity Recognition with NLTK的更多相关文章
- 自然语言18.2_NLTK命名实体识别
QQ:231469242 欢迎nltk爱好者交流 http://blog.csdn.net/u010718606/article/details/50148261 NLTK中对于很多自然语言处理应用有 ...
- 自然语言12_Tokenizing Words and Sentences with NLTK
https://www.pythonprogramming.net/tokenizing-words-sentences-nltk-tutorial/ # -*- coding: utf-8 -*- ...
- 自然语言处理NLP程序包(NLTK/spaCy)使用总结
NLTK和SpaCy是NLP的Python应用,提供了一些现成的处理工具和数据接口.下面介绍它们的一些常用功能和特性,便于对NLP研究的组成形式有一个基本的了解. NLTK Natural Langu ...
- 自然语言27_Converting words to Features with NLTK
https://www.pythonprogramming.net/words-as-features-nltk-tutorial/ Converting words to Features with ...
- 自然语言15_Part of Speech Tagging with NLTK
https://www.pythonprogramming.net/part-of-speech-tagging-nltk-tutorial/?completed=/stemming-nltk-tut ...
- 【448】NLP, NER, PoS
目录: 停用词 —— stopwords 介词 —— prepositions —— part of speech Named Entity Recognition (NER) 3.1 Stanfor ...
- 自然语言18_Named-entity recognition
https://en.wikipedia.org/wiki/Named-entity_recognition http://book.51cto.com/art/201107/276852.htm 命 ...
- 自然语言17_Chinking with NLTK
https://www.pythonprogramming.net/chinking-nltk-tutorial/?completed=/chunking-nltk-tutorial/ 代码 # -* ...
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
随机推荐
- 20 seq 某个数到另外一个数之间的所有整数
seq命令Shell内建命令 seq命令用于产生从某个数到另外一个数之间的所有整数. 语法 : seq [选项]... 尾数 seq [选项]... 首数 尾数 seq [选项]... 首数 增量 尾 ...
- linux基础-第十二单元 硬盘分区、格式化及文件系统的管理一
第十二单元 硬盘分区.格式化及文件系统的管理一 硬件设备与文件名的对应关系 硬盘的结构及硬盘分区 为什么进行硬盘分区 硬盘的逻辑结构 Linux系统中硬盘的分区 硬盘分区的分类 分区数量的约束 使用f ...
- CEPH浅析”系列之三——CEPH的设计思想
Ceph针对的目标应用场景 理解Ceph的设计思想,首先还是要了解Sage设计Ceph时所针对的目标应用场景,换言之,"做这东西的目的是啥?" 事实上,Ceph最初针对的目标应用场 ...
- Swift基础--通知,代理和block的使用抉择以及Swift中的代理
什么时候用通知,什么时候用代理,什么时候用block 通知 : 两者关系层次太深,八竿子打不着的那种最适合用通知.因为层级结构深了,用代理要一层一层往下传递,代码结构就复杂了 代理 : 父子关系,监听 ...
- Mysql修改root用户密码 For Mac 报错:ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
环境 Mysql版本:5.7.12 操作系统:OSX 10.11 安装文件:.dmg文件 MySQL:mysql-5.7.12-osx10.11-x86_64.dmg(注意5.7跟之前的字段有些不同, ...
- JavaScript RegExp 对象(来自w3school)
RegExp 对象用于规定在文本中检索的内容. 什么是 RegExp? RegExp 是正则表达式的缩写. 当您检索某个文本时,可以使用一种模式来描述要检索的内容.RegExp 就是这种模式. 简单的 ...
- python 学习笔记 8(闭包)
30. 闭包 首先理清几个关系. 函数式编程 面向对象编程 : 对象 面向过程编程 : 函数 对象和函数都是一种逻辑方式来组织代码,为了提高可重复利用性(reusability). 而闭包作用和对象 ...
- Linux下C程序的内存布局
参考下列书籍中的对应章节: <Linux高级程序设计(第3版)>第3章Linux进程存储管理.相关视频:一.二. <C专家编程>第6章 运动的诗章:运行时数据结构. <U ...
- scales小谈grunt
Grunt是基于Node.js的项目构建工具.它可以自动运行你所设定的任务.Grunt拥有数量庞大的插件,几乎任何你所要做的事情都可以用Grunt实现. 一头野猪映入眼帘,意:咕噜声 中文网站:htt ...
- Ninject.MVC 知识点记录
Ninject 是跟Unity 差不多的DI容器.Ninject 推荐零配置,快速使用.小中型项目,最适合. 通过nuget,安装Ninject.MVC.略.参考博客:Ninject依赖注入 ...