自然语言18.1_Named Entity Recognition with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)

QQ:231469242
欢迎nltk爱好者交流
https://www.pythonprogramming.net/named-entity-recognition-nltk-tutorial/?completed=/chinking-nltk-tutorial/
Named Entity Recognition with NLTK
命名实体(Named Entity)类别识别
This is a temporary script file.
""" import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer sentence="Bush is a pig in WhiteHouse in America."
words=nltk.word_tokenize(sentence)
tagged=nltk.pos_tag(words)
nameEnt=nltk.ne_chunk(tagged,binary=False) nameEnt.draw()
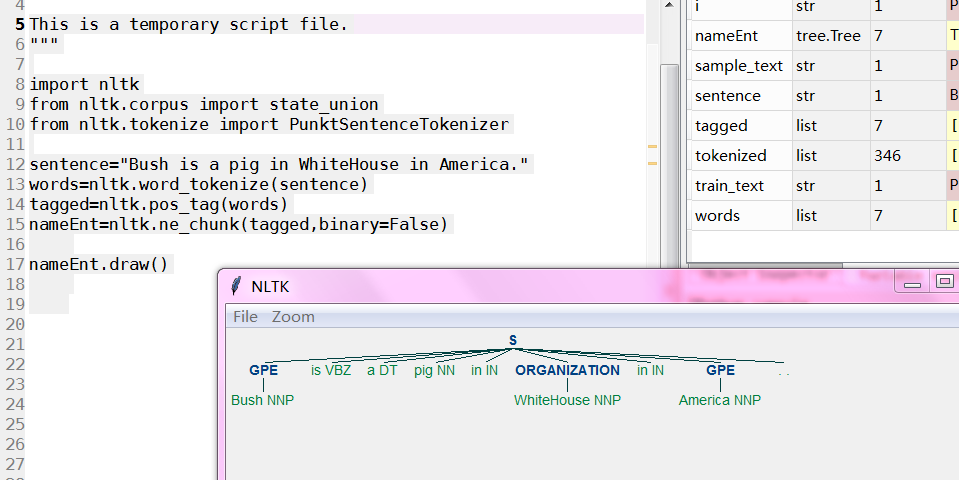
This is a temporary script file.
""" import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer train_text=state_union.raw("2005-GWBush.txt")
sample_text=state_union.raw("2006-GWBush.txt") custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#分句
tokenized=custom_sent_tokenizer.tokenize(sample_text) for i in tokenized[0:5]:
words=nltk.word_tokenize(i)
tagged=nltk.pos_tag(words)
nameEnt=nltk.ne_chunk(tagged,binary=False)
#print(nameEnt)
nameEnt.draw()
nameEnt=nltk.ne_chunk(tagged,binary=True)

nameEnt=nltk.ne_chunk(tagged,binary=False)

One of the most major forms of chunking in natural language processing is called "Named Entity Recognition." The idea is to have the machine immediately be able to pull out "entities" like people, places, things, locations, monetary figures, and more.
This can be a bit of a challenge, but NLTK is this built in for us. There are two major options with NLTK's named entity recognition: either recognize all named entities, or recognize named entities as their respective type, like people, places, locations, etc.
Here's an example:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=True)
namedEnt.draw()
except Exception as e:
print(str(e)) process_content()
Here, with the option of binary = True, this means either something is a named entity, or not. There will be no further detail. The result is:
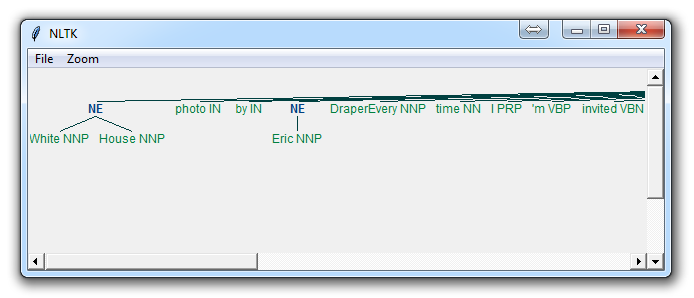
If you set binary = False, then the result is:
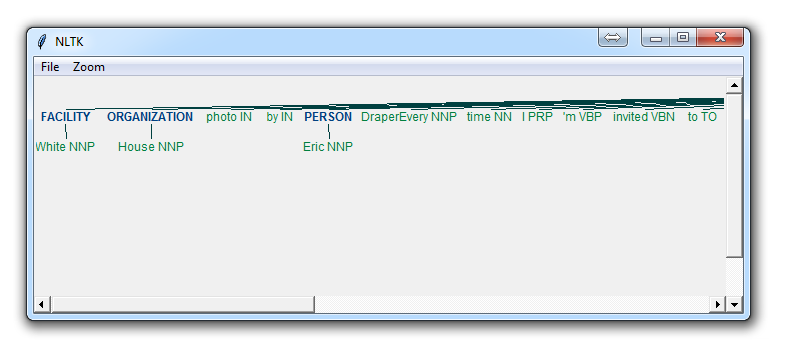
Immediately, you can see a few things. When Binary is False, it picked up the same things, but wound up splitting up terms like White House into "White" and "House" as if they were different, whereas we could see in the binary = True option, the named entity recognition was correct to say White House was part of the same named entity.
Depending on your goals, you may use the binary option how you see fit. Here are the types of Named Entities that you can get if you have binary as false:
ORGANIZATION - Georgia-Pacific Corp., WHO
PERSON - Eddy Bonte, President Obama
LOCATION - Murray River, Mount Everest
DATE - June, 2008-06-29
TIME - two fifty a m, 1:30 p.m.
MONEY - 175 million Canadian Dollars, GBP 10.40
PERCENT - twenty pct, 18.75 %
FACILITY - Washington Monument, Stonehenge
GPE - South East Asia, Midlothian
Either way, you will probably find that you need to do a bit more
work to get it just right, but this is pretty powerful right out of the
box.
In the next tutorial, we're going to talk about something similar to stemming, called lemmatizing.

自然语言18.1_Named Entity Recognition with NLTK的更多相关文章
- 自然语言18.2_NLTK命名实体识别
QQ:231469242 欢迎nltk爱好者交流 http://blog.csdn.net/u010718606/article/details/50148261 NLTK中对于很多自然语言处理应用有 ...
- 自然语言12_Tokenizing Words and Sentences with NLTK
https://www.pythonprogramming.net/tokenizing-words-sentences-nltk-tutorial/ # -*- coding: utf-8 -*- ...
- 自然语言处理NLP程序包(NLTK/spaCy)使用总结
NLTK和SpaCy是NLP的Python应用,提供了一些现成的处理工具和数据接口.下面介绍它们的一些常用功能和特性,便于对NLP研究的组成形式有一个基本的了解. NLTK Natural Langu ...
- 自然语言27_Converting words to Features with NLTK
https://www.pythonprogramming.net/words-as-features-nltk-tutorial/ Converting words to Features with ...
- 自然语言15_Part of Speech Tagging with NLTK
https://www.pythonprogramming.net/part-of-speech-tagging-nltk-tutorial/?completed=/stemming-nltk-tut ...
- 【448】NLP, NER, PoS
目录: 停用词 —— stopwords 介词 —— prepositions —— part of speech Named Entity Recognition (NER) 3.1 Stanfor ...
- 自然语言18_Named-entity recognition
https://en.wikipedia.org/wiki/Named-entity_recognition http://book.51cto.com/art/201107/276852.htm 命 ...
- 自然语言17_Chinking with NLTK
https://www.pythonprogramming.net/chinking-nltk-tutorial/?completed=/chunking-nltk-tutorial/ 代码 # -* ...
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
随机推荐
- webpack入坑之旅(二)loader入门
这是一系列文章,此系列所有的练习都存在了我的github仓库中vue-webpack 在本人有了新的理解与认识之后,会对文章有不定时的更正与更新.下面是目前完成的列表: webpack入坑之旅(一)不 ...
- 用自己的话描述wcf中的传输安全与消息安全的区别(三)
消息交换安全模式 PS:很多书上把transfer security和transport security都翻译成“传输安全”,这样易混淆.我这里把transfer说成消息交换安全. 安全的含义分为验 ...
- 【CodeVS 1582】【SDOI 2009】E和D
http://codevs.cn/problem/1582/ 首先我打了一张50*50的表(4用#代替) 并没有发现什么规律! 然后观察题解可得,我观察的是TimeMachine学长的题解 什么得到s ...
- word2007插入页码里面不显示或没选项可点怎么办?
1.打开Word 2007 2.单击Microsoft Office按钮 (左上角的圆圈) 3.单击“Word 选项”(在页面的右下方) 4.单击“加载”项(页面左边一排,倒数第三个,出现的页面中,向 ...
- spring-ant-处理zip
因为java类型自带的不支持中文路径,不过两者使用的方式是一样的,只是apache压缩工具多了设置编码方式的接口,其他基本上是一样的.另外,如果使用org.apache.tools.zip.ZipOu ...
- 数据库开发基础-SQl Server 主键、外键、子查询(嵌套查询)
主键 数据库主键是指表中一个列或列的组合,其值能唯一地标识表中的每一行.这样的一列或多列称为表的主键,通过它可强制表的实体完整性.当创建或更改表时可通过定义 PRIMARY KEY约束来创建主键.一个 ...
- asp.net mvc中应用缓存依赖文件(xml)的一个小demo
最近项目中加了一个通用模块,就是根据一些特殊的tag,然后根据处理这些tag在同一个视图中加载不同的model(个人觉得此功能无任何意义,只是把不同的代码放在了同一个View中). 我的处理思路是这样 ...
- golang学习之旅:搭建go语言开发环境
从今天起,将学习go语言.今天翻了一下许式伟前辈写的<Go语言编程>中的简要介绍:Go语言——互联网时代的C语言.前面的序中介绍了Go语言的很多特性,很强大,迫不及待地想要一探究竟,于是便 ...
- Leetcode 110. Balanced Binary Tree
Given a binary tree, determine if it is height-balanced. For this problem, a height-balanced binary ...
- 一次性下载CVPR2016的所有文章
wget --no-clobber --convert-links --random-wait -r -p -E -e robots=off -U mozilla http://www.cv-foun ...