生成式学习算法(三)之----高斯判别分析模型(Gaussian Discriminant Analysis ,GDA)
高斯判别分析模型(Gaussian Discriminant Analysis ,GDA)
当我们分类问题的输入特征$x $为连续值随机变量时,可以用高斯判别分析模型(Gaussian Discriminant Analysis ,GDA)。高斯判别分析模型通过多元正态分布来建模前面提到的概率 \(p(x | y)\)。具体的,这个模型为,
\[
\begin{equation}
\begin{aligned}
y & \sim \operatorname{Bernoulli}(\phi) \\
x | y=0 & \sim \mathcal{N}\left(\mu_{0}, \Sigma\right) \\
x | y=1 & \sim \mathcal{N}\left(\mu_{1}, \Sigma\right)
\end{aligned}
\end{equation}
\]
这个模型中的参数有 \(\phi, \Sigma, \mu_{0}\) 和 \(\mu_{1}\) 。注意到,尽管有两个不同的均值向量 \(\mu_{0}\) 和 \(\mu_{1}\)。但模型通常只有只用一个协方差矩阵 $ \Sigma$。将这三个随机变量的分布写出来则有,
\[
\begin{equation}
\begin{aligned}
p(y) &=\phi^{y}(1-\phi)^{1-y} \\
p(x | y=0) &=\frac{1}{(2 \pi)^{n / 2}|\Sigma|^{1 / 2}} \exp \left(-\frac{1}{2}\left(x-\mu_{0}\right)^{T} \Sigma^{-1}\left(x-\mu_{0}\right)\right) \\
p(x | y=1) &=\frac{1}{(2 \pi)^{n / 2}|\Sigma|^{1 / 2}} \exp \left(-\frac{1}{2}\left(x-\mu_{1}\right)^{T} \Sigma^{-1}\left(x-\mu_{1}\right)\right)
\end{aligned}
\end{equation}
\]
有了上面三个分布,则可以知道数据的对数似然概率\(\ell\)为,
\[
\begin{equation}
\begin{aligned}
\ell\left(\phi, \mu_{0}, \mu_{1}, \Sigma\right) &=\log \prod_{i=1}^{m} p\left(x^{(i)}, y^{(i)} ; \phi, \mu_{0}, \mu_{1}, \Sigma\right) \\
&=\log \prod_{i=1}^{m} p\left(x^{(i)} | y^{(i)} ; \mu_{0}, \mu_{1}, \Sigma\right) p\left(y^{(i)} ; \phi\right)
\end{aligned}
\end{equation}
\]
通过求各个参数关于对数似然概率\(\ell\)偏导为零的值,也就是使各个参数在这些取值下使得对数似然概率\(\ell\)最大的值,可以找到个参数的最大似然估计为,
\[
\begin{equation}
\begin{aligned}
\phi &=\frac{1}{m} \sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\} \\
\mu_{0} &=\frac{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\} x^{(i)}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\}} \\
\mu_{1} &=\frac{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\} x^{(i)}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\}} \\
\Sigma &=\frac{1}{m} \sum_{i=1}^{m}\left(x^{(i)}-\mu_{y^{(i)}}\right)\left(x^{(i)}-\mu_{y^{(i)}}\right)^{T}
\end{aligned}
\end{equation}
\]
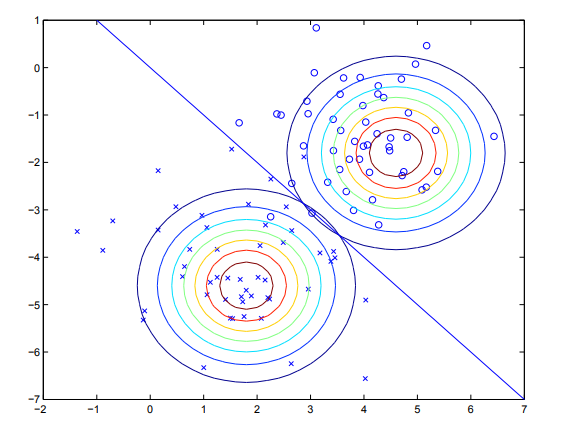
给定训练数据,通过高斯判别分析训练出的模型可以由下图来表示。其中圈和叉分别为两类数据。两个等高线图则是根据上式用数据拟合出的两个最优密度分布。直线为等高线密度相等的点,皆为0.5,也就是所谓决策边界。由于这两个分部共享协方差阵,所以虽然他们密度的均值不同,但形状相同。
高斯判别分析模型和logistic回归模型之间的关系
如果我们将后验概率$p\left(y^{(i)}=1 |x^{(i)} ; \phi, \mu_{0}, \mu_{1}, \Sigma\right) $ 视为 $x $ 的函数,则高斯判别分析模型可以写成和logistic回归模型一样的形式,即有
\[
p\left(y=1 | x ; \phi, \Sigma, \mu_{0}, \mu_{1}\right)=\frac{1}{1+\exp \left(-\theta^{T} x\right)}
\]
这里$ \theta$ 是模型参数的函数。$ x$ 为 $ n+1$ 维的带常数截距项的特征向量。
需要注意的是虽然两个模型具有相同的形式,在相同的数据集上训练这两个模型一般得到的是两个不同的决策边界。那么问题就来了,我们什么时候该用什么模型?哪个模型更好呢?
我们刚才的讨论已经说明了,如果$ x$ 的条件分布\(p(x | y)\) 满足多元高斯分布,则后验概率表达式\(p(y | x)\) 一定是logistic回归函数的形式,但反过来不一定是正确的。即在后验概率表达后验概率\(p(y | x)\) 是logistic回归函数的形式的条件下,$ x$ 的条件概率分布\(p(x | y)\) 不一定满足多元高斯分布。
这表明了GDA模型对数据的模型假设要比logistic回归模型强。
当模型假设正确的时候,也就是\(p(x | y)\) 确实满足多元高斯正态分布的时候,GDA模型是一个更好的模型,是渐进有效的(在更准意义下,没有其它模型能比它更好)。
然而,通过做出较弱的模型假设,logistic回归模型更鲁棒,对于不正确的模型假设也不那么敏感。例如当X满足泊松分布时也能推导出logistic回归模型,但这时如果用GDA模型来拟合数据,则会得到较差的效果。
综上所述,logistic回归模型作出的假设更弱,对于不正确的假设也更鲁棒。在数据集规模够大的情况下,logistic回归模型几乎总是要优于GDA模型。GDA模型通过做出更强的假设对数据的利用效率更高,也就是说当假设正确或近似正确时能以较少的数据拟合出较好的模型。
最后严正声明:logistic回归模型是判别式模型,高斯判别分析模型(GDA)是生成式模型。
生成式学习算法(三)之----高斯判别分析模型(Gaussian Discriminant Analysis ,GDA)的更多相关文章
- 机器学习理论基础学习3.4--- Linear classification 线性分类之Gaussian Discriminant Analysis高斯判别模型
一.什么是高斯判别模型? 二.怎么求解参数?
- 高斯判别分析 Gaussian Discriminant Analysis
如果在我们的分类问题中,输入特征xx是连续型随机变量,高斯判别模型(Gaussian Discriminant Analysis,GDA)就可以派上用场了. 以二分类问题为例进行说明,模型建立如下: ...
- Gaussian discriminant analysis 高斯判别分析
高斯判别分析(附Matlab实现) 生成学习算法 高斯判别分析(Gaussian Discriminant analysis,GDA),与之前的线性回归和Logistic回归从方法上讲有很大的不同,G ...
- 高斯判别分析模型( Gaussian discriminant analysis)及Python实现
高斯判别分析模型( Gaussian discriminant analysis)及Python实现 http://www.cnblogs.com/sumai 1.模型 高斯判别分析模型是一种生成模型 ...
- CS229笔记:生成学习算法
在线性回归.逻辑回归.softmax回归中,学习的结果是\(p(y|x;\theta)\),也就是给定\(x\)的条件下,\(y\)的条件概率分布,给定一个新的输入\(x\),我们求出不同输出的概率, ...
- 斯坦福《机器学习》Lesson5感想———1、成学习算法
在前面几课里的学习算法的思路都是给定数据集以后.确定基于此数据集的最佳如果H函数,通过学习算法确定最佳如果H的各个參数,然后通过最佳如果函数H得出新的数据集的结果.在这一课里介绍了一种新的思路,它的核 ...
- 【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)
参考: cs229讲义 机器学习(一):生成学习算法Generative Learning algorithms:http://www.cnblogs.com/zjgtan/archive/2013/ ...
- [置顶] 生成学习算法、高斯判别分析、朴素贝叶斯、Laplace平滑——斯坦福ML公开课笔记5
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9285001 该系列笔记1-5pdf下载请猛击这里. 本篇博客为斯坦福ML公开 ...
- 生成学习算法(Generative Learning algorithms)
一.引言 前面我们谈论到的算法都是在给定\(x\)的情况下直接对\(p(y|x;\theta)\)进行建模.例如,逻辑回归利用\(h_\theta(x)=g(\theta^T x)\)对\(p(y|x ...
随机推荐
- 从零开始一起学习SLAM | 用四元数插值来对齐IMU和图像帧
视觉 Vs. IMU 小白:师兄,好久没见到你了啊,我最近在看IMU(Inertial Measurement Unit,惯性导航单元)相关的东西,正好有问题求助啊 师兄:又遇到啥问题啦? 小白:是这 ...
- 02 http和https协议
1. HTTP协议 简介 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写, 是用于从万维网(WWW:World Wide Web )服务器传输超文本到本 ...
- Spark应用监控解决方案--使用Prometheus和Grafana监控Spark应用
Spark任务启动后,我们通常都是通过跳板机去Spark UI界面查看对应任务的信息,一旦任务多了之后,这将会是让人头疼的问题.如果能将所有任务信息集中起来监控,那将会是很完美的事情. 通过Spark ...
- 第一个Javaweb应用程序
第一个Javaweb应用程序 一.Javaweb应用程序结构 一个 web 应用程序是由一组 Servlet,HTML 页面,类,以及其它的资源组成的运行在 web 服务器上的完整的应用程序,以一种结 ...
- 【原创】Linux cpu hotplug
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- redis六种内存淘汰策略学习
当客户端会发起需要更多内存的申请,Redis检查内存使用情况,如果实际使用内存已经超出maxmemory,Redis就会根据用户配置的淘汰策略选出无用的key; 当前Redis3.0版本支持的淘汰策略 ...
- yield 实现range()函数
def range(*args,step= 1): args = list(args) if len(args) == 2: yield args[0] while args[0]<args[1 ...
- 牛客暑假多校 H Prefix sum
题意: 现在有一个2维矩阵, 初始化为0. 并且这个矩阵是及时更新的. dp[i][j] = dp[i-1][j] + dp[i][j-1]; 现在有2种操作: 0 x y dp[1][x] += ...
- Gym 100851 题解
A: Adjustment Office 题意:在一个n*n的矩阵,每个格子的的价值为 (x+y), 现在有操作取一行的值,或者一列的值之后输出这个和, 并且把这些格子上的值归0. 题解:模拟, 分成 ...
- 跟我学SpringCloud | 第十七篇:服务网关Zuul基于Apollo动态路由
目录 SpringCloud系列教程 | 第十七篇:服务网关Zuul基于Apollo动态路由 Apollo概述 Apollo相比于Spring Cloud Config优势 工程实战 示例代码 Spr ...