爬虫实战(二) 51job移动端数据采集
在上一篇51job职位信息的爬取中,对岗位信息div下各式各样杂乱的标签,简单的Xpath效果不佳,加上string()函数后,也不尽如人意。因此这次我们跳过桌面web端,选择移动端进行爬取。
一、代码结构
按照下图所示的爬虫基本框架结构,我将此份代码分为四个模块——URL管理、HTML下载、HTML解析以及数据存储。
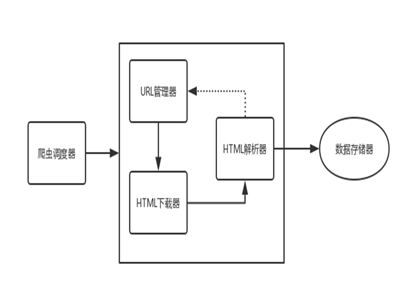
二、URL管理模块
这个模块负责搜索框关键词与对应页面URL的生成,以及搜索结果不同页数的管理。首先观察某字段(大数据, UTF-8为'E5A4A7 E695B0 E68DAE') 全国范围内的结果,前三页结果的URL如下:
URL前半部分:

这部分中我们可以看到两处处不同,第一处为编码后'2,?.html'中间的数字,这是页数。另一处为参数stype的值,除第一页为空之外,其余都为1。另外,URL中有一连串的数字,这些是搜索条件,如地区、行业等,在这儿我没有用上。后面的一连串字符则为搜索关键词的字符编码。值得注意的是,有些符号在URL中是不能直接传输的,如果需要传输的话,就需要对它们进行编码。编码的格式为'%'加上该字符的ASCII码。因此在该URL中,%25即为符号'%'。
URL后半部分:

后半部分很明显的就能出首页与后面页面的URL参数相差很大,非首页的URL后半部分相同。
因此我们需要对某关键字的搜索结果页面分两次处理,第一次处理首页,第二次可使用循环处理后续的页面。
- if __name__ == '__main__':
- key = '数据开发'
- # 第一页
- url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'+key+',2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
- getUrl(url)
- # 后页[2,100)
- urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,'+key+',2,{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(i) for i in range(2,30)]
- for url in urls:
- getUrl(url)
三、HTML下载模块
下载HTMl页面分为两个部分,其一为下载搜索结果某一页的HTML页面,另一部分为下载某一岗位具体页面。由于页面中具体岗位URL需要从搜索结果页面中获取,所以将下载搜索结果页面及获取具体岗位URL放入一个函数中,在提取到具体岗位URL后,将其传入至另一函数中。
3.1搜索结果页面下载与解析
下载页面使用的是requests库的get()方法,得到页面文本后,通过lxml库的etree将其解析为树状结构,再通过Xpath提取我们想要的信息。在搜索结果页面中,我们需要的是具体岗位的URL,打开开发者选项,找到岗位名称。

我们需要的是<a>标签里的href属性。右键,复制——Xpath,得到该属性的路径。
- //*[@id="resultList"]/div/p/span/a/@href
由于xpath返回值为一个列表,所以通过一个循环,将列表内URL依次传入下一函数。
- def getUrl(url):
- print('New page')
- res = requests.get(url)
- res.encoding = 'GBK'
- if res.status_code == requests.codes.ok:
- selector = etree.HTML(res.text)
- urls = selector.xpath('//*[@id="resultList"]/div/p/span/a/@href')
- # //*[@id="resultList"]/div/p/span/a
- for url in urls:
- parseInfo(url)
- time.sleep(random.randrange(1, 4))
3.2具体岗位信息页面下载
该函数接收一个具体岗位信息的参数。由于我们需要对移动端网页进行处理,所以在发送请求时需要进行一定的伪装。通过设置headers,使用手机浏览器的用户代理,再调用get()方法。
- def parseInfo(url):
- headers = {
- 'User-Agent': 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/ADR-1301071546) Presto/2.11.355 Version/12.10'
- }
- res = requests.get(url, headers=headers)
四、HTML解析模块
在3.2中,我们已经得到了岗位信息的移动端网页源码,因此再将其转为etree树结构,调用Xpath即可得到我们想要的信息。
需要注意的是页面里岗位职责div里,所有相关信息都在一个<article>标签下,而不同页面的<article>下层标签并不相同,所以需要将该标签下所有文字都取出,此处用上了string()函数。
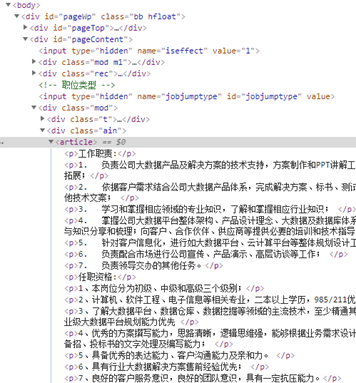
- selector = etree.HTML(res.text)
- title = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/p/text()')
- salary = selector.xpath('//*[@id="pageContent"]/div[1]/p/text()')
- company = selector.xpath('//*[@id="pageContent"]/div[2]/a[1]/p/text()')
- companyinfo = selector.xpath('//*[@id="pageContent"]/div[2]/a[1]/div/text()')
- companyplace = selector.xpath('//*[@id="pageContent"]/div[2]/a[2]/span/text()')
- place = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/em/text()')
- exp = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[2]/text()')
- edu = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[3]/text()')
- num = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[1]/text()')
- time = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/span/text()')
- info = selector.xpath('string(//*[@id="pageContent"]/div[3]/div[2]/article)')
- info = str(info).strip()
五、数据存储模块
首先创建.csv文件,将不同列名称写入首行。
- fp = open('51job.csv','wt',newline='',encoding='GBK',errors='ignore')
- writer = csv.writer(fp)
- writer.writerow(('职位','薪资','公司','公司信息','公司地址','地区','工作经验','学历','人数','时间','岗位信息'))
再在解析某一页面数据后,将数据按行写入.csv文件。
- writer.writerow((title,salary,company,companyinfo,companyplace,place,exp,edu,num,time,info))
相关:智联招聘源码分析
爬虫实战(二) 51job移动端数据采集的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- Puppeteer爬虫实战(二)
连接浏览器 上一篇说到了Puppeteer本质是使用了Chrome Devtools协议控制浏览器,本篇就说说连接方式. 常规Hook浏览器 此方式其实就是需要一个浏览器可执行文件(不同平台需要下载对 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- 基于C#.NET的高端智能化网络爬虫(二)(攻破携程网)
本篇故事的起因是携程旅游网的一位技术经理,豪言壮举的扬言要通过他的超高智商,完美碾压爬虫开发人员,作为一个业余的爬虫开发爱好者,这样的言论我当然不能置之不理.因此就诞生了以及这一篇高级爬虫的开发教程. ...
随机推荐
- HDU4081 Qin Shi Huang's National Road System 2017-05-10 23:16 41人阅读 评论(0) 收藏
Qin Shi Huang's National Road System ...
- hdu 5032 不易发觉的树状数组
http://acm.hdu.edu.cn/showproblem.php?pid=5032 给定一个1000x1000的点阵,m组询问,每次询问一个由(0,0).(x,0)点一以及从原点出发的方向向 ...
- Android-Xml文件生成,Xml数据格式写入
在上一篇博客,Android-XML格式描述,介绍来XML在Android中的格式: 生成xml文件格式数据,Android提供了Xml.newSerializer();,可以理解为Xml序列化: 序 ...
- 设计模式之模版方法模式(Template Method Pattern)
一.什么是模版方法模式? 首先,模版方法模式是用来封装算法骨架的,也就是算法流程 既然被称为模版,那么它肯定允许扩展类套用这个模版,为了应对变化,那么它也一定允许扩展类做一些改变 事实就是这样,模版方 ...
- ASP.NET Core真实管道详解[1]
ASP.NET Core管道虽然在结构组成上显得非常简单,但是在具体实现上却涉及到太多的对象,所以我们在 <ASP.NET Core管道深度剖析[共4篇]> 中围绕着一个经过极度简化的模拟 ...
- IocPerformance 常见IOC 功能、性能比较
IocPerformance IocPerformance 基本功能.高级功能.启动预热三方面比较各IOC,可以用作选型参考. Lamar: StructureMap的替代品 Lamar 文档 兼容S ...
- Ruby on Rails 生成指定版本的 Rails 项目
ruby-on-rails ruby 本地 Rails 默认5.1.6 版本 $ gem list --local rails (5.1.6, 5.1.5, 5.1.4) 使用 version 生成指 ...
- Font Awesome矢量版,十六进制版,WPF字体使用
我之前在博客中介绍过几个矢量图库网站,在WPF程序中,一般接触到的矢量图标资源有XAML.SVG.字体这三种格式.XAML是标准格式就不说了,SVG并不是直接支持的,不过微软提供了Expression ...
- OSX - libc++究竟是啥?
libc++是什么? libc++是C++标准库的实现! libc++ is an implementation of the C++ standard library, targeting C++ ...
- JavaWeb -学生信息管理实践(JDBC+web+三层架构+DBUtil构造思路)
前言: 1 该程序使用动态web项目 2 该程序使用SQL server需导入对应包( 具体可看前篇----JDBC的使用) 3 三层架构思想: ①表示层 前台:jsp/html等 作为前台与用户交互 ...