第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
PhantomJS虚拟浏览器
phantomjs 是一个基于js的webkit内核无头浏览器 也就是没有显示界面的浏览器,利用这个软件,可以获取到网址js加载的任何信息,也就是可以获取浏览器异步加载的信息
下载网址:http://phantomjs.org/download.html 下载对应系统版本
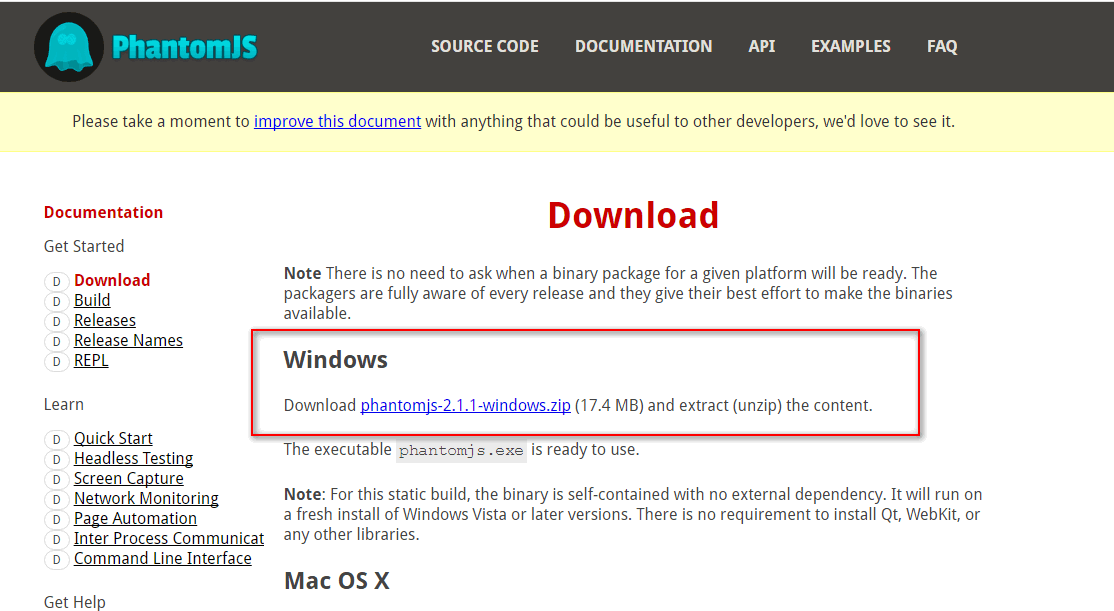
下载后解压PhantomJS文件,将解压文件夹,剪切到python安装文件夹
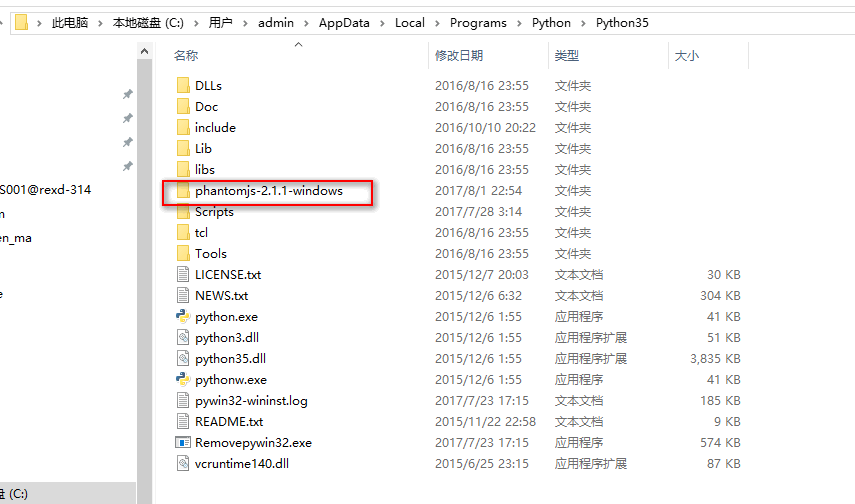
然后将PhantomJS文件夹里的bin文件夹添加系统环境变量
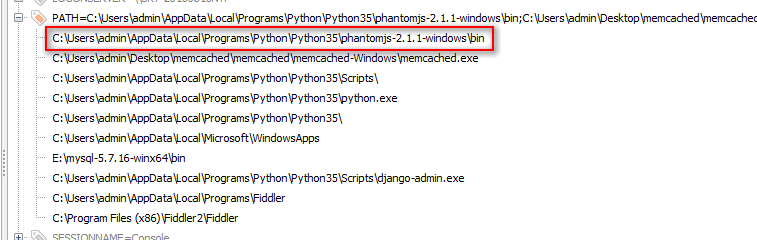
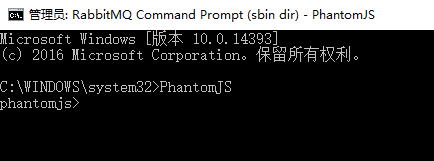
cdm 输入命令:PhantomJS 出现以下信息说明安装成功
selenium模块是一个python操作PhantomJS软件的一个模块
selenium模块PhantomJS软件
webdriver.PhantomJS()实例化PhantomJS浏览器对象
get('url')访问网站
find_element_by_xpath('xpath表达式')通过xpath表达式找对应元素
clear()清空输入框里的内容
send_keys('内容')将内容写入输入框
click()点击事件
get_screenshot_as_file('截图保存路径名称')将网页截图,保存到此目录
page_source获取网页htnl源码
quit()关闭PhantomJS浏览器
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
import os
import time
import re llqdx = webdriver.PhantomJS() #实例化PhantomJS浏览器对象
llqdx.get("https://www.baidu.com/") #访问网址 # time.sleep(3) #等待3秒
# llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图保存到此目录 #模拟用户操作
llqdx.find_element_by_xpath('//*[@id="kw"]').clear() #通过xpath表达式找到输入框,clear()清空输入框里的内容
llqdx.find_element_by_xpath('//*[@id="kw"]').send_keys('叫卖录音网') #通过xpath表达式找到输入框,send_keys()将内容写入输入框
llqdx.find_element_by_xpath('//*[@id="su"]').click() #通过xpath表达式找到搜索按钮,click()点击事件 time.sleep(3) #等待3秒
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录 neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器 pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
PhantomJS浏览器伪装,和滚动滚动条加载数据
有些网站是动态加载数据的,需要滚动条滚动加载数据
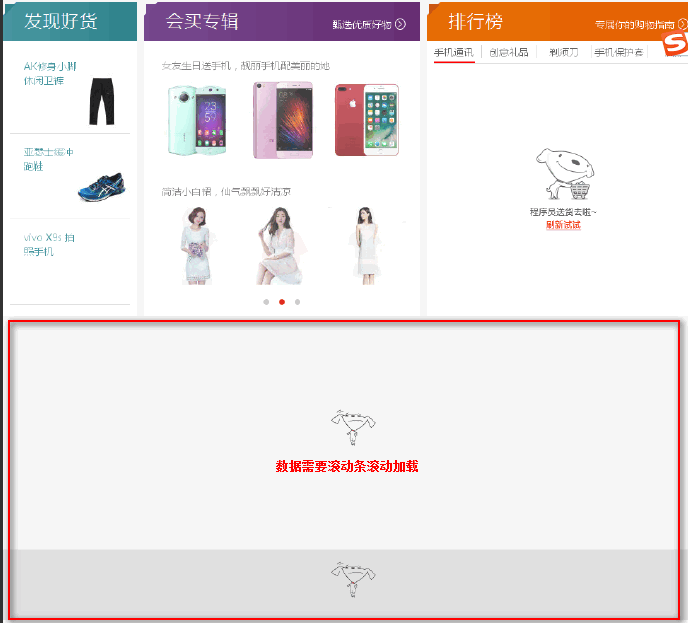
实现代码
DesiredCapabilities 伪装浏览器对象
execute_script()执行js代码
current_url获取当前的url
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #导入浏览器伪装模块
import os
import time
import re dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
print(dcap)
llqdx = webdriver.PhantomJS(desired_capabilities=dcap) #实例化PhantomJS浏览器对象 llqdx.get("https://www.jd.com/") #访问网址 #模拟用户操作
for j in range(20):
js3 = 'window.scrollTo('+str(j*1280)+','+str((j+1)*1280)+')'
llqdx.execute_script(js3) #执行js语言滚动滚动条
time.sleep(1) llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录 url = llqdx.current_url
print(url) neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器 pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS的更多相关文章
- 十六 web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
PhantomJS虚拟浏览器 phantomjs 是一个基于js的webkit内核无头浏览器 也就是没有显示界面的浏览器,利用这个软件,可以获取到网址js加载的任何信息,也就是可以获取浏览器异步加载的 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置
第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置 主题设置是在xadmin\plugins\themes.py这个文件 默认xadmin是通过下面这 ...
- 第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示
第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示 首先了解一下static静态文件与上传资源的区别,static静态文件里面一般防止的我们网站样式的文件, ...
- 第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成
第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成 apps目录建立 我们创建一个apps目录,将所有的app放到apps目录里去,这样方便管理,也 ...
- 第三百二十二节,web爬虫,requests请求
第三百二十二节,web爬虫,requests请求 requests请求,就是用yhthon的requests模块模拟浏览器请求,返回html源码 模拟浏览器请求有两种,一种是不需要用户登录或者验证的请 ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
随机推荐
- 探寻main函数的“标准”写法,以及获取main函数的参数、返回值
main函数表示法 很多同学在初学C或者C++时,都见过各种各样的main函数表示法: main(){/*...*/} void main(){/*...*/} int main(){/ ...
- .NET MVC+ EF+调用存储过程 多表联查以及VIEW列表显示
直接上干活,至于网上的一大堆处理方式不予评论,做好自己的就是最好的,供大家不走弯路 1.view页面 <link href="~/Content/bootstrap.css" ...
- 聊聊javascript的null和undefined
只要是说到js的变量和数据类型,就脱不开null和undefined,这兄弟俩就是js的重要基础,不可不察,无数的同学们都用过放大镜多角度多批次地研究过这兄弟俩,真是深受欢迎.^-^ js也真是怪异, ...
- 每日英语:China's Wistful Wen Gets His Wish
As his term as premier was drawing to a close, Wen Jiabao reflected wistfully on some of the goals h ...
- Windows系统盘瘦身指南
[本文出自天外归云的博客园] Windows系统的C盘空间越来越小,按以下四步进行清理,还你6个G: 1.开启腾讯管家之类的软件进行第一轮垃圾清理: 2.删除以下文件夹,"C:\Progra ...
- zoj 3761(并查集+搜索)
题意:在一个平面上,有若干个球,给出球的坐标,每次可以将一个球朝另一个球打过去(只有上下左右),碰到下一个球之后原先的球停下来,然后被撞的球朝这个方向移动,直到有一个球再也撞不到下一个球后,这个球飞出 ...
- keepalived+nginx双机热备+负载均衡
Reference: http://blog.csdn.net/e421083458/article/details/30092795 keepalived+nginx双机热备+负载均衡 最近因业务扩 ...
- Oracle数据库密码过期
按照如下步骤进行操作:1.查看用户的proifle是哪个,一般是default: SQL>SELECT USERNAME,PROFILE FROM DBA_USERS; 2.查看指定概要文件(如 ...
- Android TabHost的使用 顶部选项卡
用TabHost 来实现顶部选项卡,上代码:activity_main.xml <?xml version="1.0" encoding="utf-8"? ...
- iOS five years[转]
原文链接:http://blog.ayaka.me/post/127980091987/5-years This morning, I got a push notification from Tim ...