python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务。其工作流程为:
1)先产生一组“个体学习器”。在分类问题中,个体学习器也称为基类分类器
2)再使用某种策略将它们结合起来。
通常使用一种或者多种已有的学习算法从训练数据中产生个体学习器。通常选取个体学习器的准则是:
1)个体学习器要有一定的准确性,预测能力不能太差
2)个体学习器之间要有多样性,即学习器之间要有差异
根据个体学习器的生成方式,目前的集成学习方法大概可以分为以下两类:
1)Boosting算法:在Boosting算法中,个体学习器之间存在强依赖关系、必须串行生成
2)Bagging算法:在Bagging算法中,个体学习器之间不存在强依赖关系、可同时生成。
1、Boosting(提升)算法
Boosting就是一族可以将弱学习器提升为强学习器的算法。其工作原理类似,工作步骤如下:
1)先从初始训练集训练出一个基学习器
2)再根据基学习器的表现对训练样本权重进行调整,使得被先前的基学习器误判的训练样本在后续受到更多关注
3)然后基于调整后的样本权重来训练下一个基学习器
4)如此重复,直到基学习器数量达到给定的值M为止
5)最终将这M个基学习器进行加权组合得到集成学习器
2、AdaBoost(适应的提升)算法
AdaBoost算法具有自适应性,即它能够适应弱分类器各自的训练误差率。这也是它名字的由来。从偏差-方差分解的角度来看,AdaBoost主要关注降低偏差,因此AdaBoost能基于弱学习器构建出很强的集成学习器
输入:训练数据集T,弱学习算法
输出:集成分类器H(x)
算法步骤:
1)初始化训练数据的权重向量W<1>
2)对m=1,2,...,M
*使用权重向量W<m>的训练数据集学习,得到基分类器(根据输入的弱学习算法)
*计算基分类器在训练数据集上的分类误差率em
*若em>=1/2,算法终止,构建失败!
*计算基分类器的系数αm
*更新训练数据集的权重向量W<m+1>
3)构建基于分类器的线性组合
#AdaBoost多类分类
标准的AdaBoost算法仅能解决二分类问题,稍加改进后,也可解决多分类问题
实验代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble def load_data_regression():
diabetes=datasets.load_diabetes()
return cross_validation.train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) def load_data_classification():
digits=datasets.load_digits()
return cross_validation.train_test_split(digits.data,digits.target,test_size=0.25,random_state=0) def test_AdaBoostClassifier(*data):
x_train,x_test,y_train,y_test=data
cls=ensemble.AdaBoostClassifier(learning_rate=0.1)
cls.fit(x_train,y_train)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators=len(cls.estimators_)
X=range(1,estimators+1)
ax.plot(list(X),list(cls.staged_score(x_train,y_train)),label="Traing score")
ax.plot(list(X),list(cls.staged_score(x_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() def test_AdaBoostRegressor(*data):
x_train,x_test,y_train,y_test=data
regr=ensemble.AdaBoostRegressor()
regr.fit(x_train,y_train)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(x_train,y_train)),label="Traing score")
ax.plot(list(X),list(regr.staged_score(x_test,y_test)),label="Testing score") ax.set_xlabel("estimators num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostRegressor")
plt.show() x_train,x_test,y_train,y_test=load_data_classification()
test_AdaBoostClassifier(x_train,x_test,y_train,y_test)
x_train,x_test,y_train,y_test=load_data_regression()
test_AdaBoostRegressor(x_train,x_test,y_train,y_test)
实验结果:
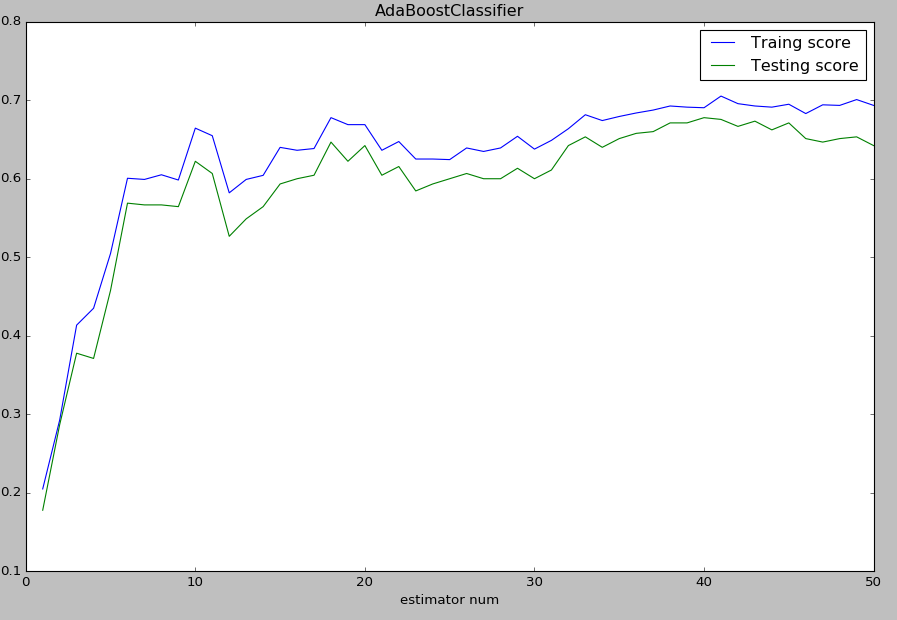

3、AdaBoost与加法模型
AdaBoost算法可以认为是:模型为加法模型,损失函数为指数函数,学习算法为前向分步算法时的二分类学习方法
4、提升树
提升树是以决策树为基本分类器的提升方法,其预测性能相当优异。
对分类问题,决策树是二叉决策树;对回归问题,决策树是二叉回归树
提升树模型可以表示为决策树为基本分类器的加法模型
(1)GradientBoostingClassifier梯度提升决策树
实验代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble def load_data_classification():
digits = datasets.load_digits()
return cross_validation.train_test_split(digits.data, digits.target, test_size=0.25, random_state=0) def test_GradientBoostingClassifier(*data):
x_train,x_test,y_train,y_test=data
clf=ensemble.GradientBoostingClassifier()
clf.fit(x_train,y_train)
print("Training score:%f"%clf.score(x_train,y_train))
print("Tesing score:%f"%clf.score(x_test,y_test)) x_train,x_test,y_train,y_test=load_data_classification()
test_GradientBoostingClassifier(x_train,x_test,y_train,y_test)
实验结果:

从结果可以看出梯度提升决策树对于分类问题,有一个很好的预测性能。尤其是当适当调整个体决策树的个数时,可以取得一个更佳的取值。同时树的深度对预测性能也会有影响,因此在面对具体的数据时,也需要通过调参找到一个合适的深度。该方法还有一个subsample参数,这个参数指定了提取原始训练集中的一个子集用于训练基础决策树。该参数就是子集占原始训练集的大小,大于0,小于1。如果sample小于1,则梯度提升决策树模型就是随机梯度提升决策树,此时会减少方差但是提高了偏差,它会影响n_estimators参数。
(2)GradientBoostingRegressor梯度提升回归树
实验代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble def load_data_regression():
diabetes=datasets.load_diabetes()
return cross_validation.train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) def test_GradientBoostingRegressor(*data):
x_train,x_test,y_train,y_test=data
regr=ensemble.GradientBoostingRegressor()
regr.fit(x_train,y_train)
print("Training score:%f"%regr.score(x_train,y_train))
print("Testing score:%f"%regr.score(x_test,y_test)) x_train,x_test,y_train,y_test=load_data_regression()
test_GradientBoostingRegressor(x_train,x_test,y_train,y_test)
实验结果:
 似乎所有的模型对于回归问题的预测性能都不怎么好。当慢慢调整模型的个体回归树的数量时,会发现GBRT对于训练集的拟合一直在提高,但是对于测试集的预测得分先快速上升后基本上缓缓下降。
似乎所有的模型对于回归问题的预测性能都不怎么好。当慢慢调整模型的个体回归树的数量时,会发现GBRT对于训练集的拟合一直在提高,但是对于测试集的预测得分先快速上升后基本上缓缓下降。
5、Bagging算法
Bagging基于自助采样法。Bagging首先采用M轮自助采样法,获得M个包含N个训练样本的采样集。然后,基于这些采样集训练出一个基学习器。最后将这M个基学习器进行组合。组合策略为:
1)分类任务采取简单投票法,即每个基学习器一票
2)回归任务采用简单平均法,即每个基学习器的预测值取平均值
从偏差-方差分解的角度来看,Bagging主要关注降低方差。因此它在不剪枝决策树、神经网络等容易受到样本扰动的学习器上效果更为明显
*随机森林(Random Forest,RF):RF是一种以决策树为基学习器的Bagging算法,但是RF在决策树的训练过程中引入了随机属性选择。RF的训练效率搞,因为RF使用的决策树只需要考虑一个属性的子集。另外,RF简单、容易实现、计算开销小,而且它在很多现实任务中展现出强大的性能
(1)RandomForestClassifier随机森林分类器
实验代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble def load_data_classification():
digits = datasets.load_digits()
return cross_validation.train_test_split(digits.data, digits.target, test_size=0.25, random_state=0) def test_RandomForestClassifier(*data):
x_train,x_test,y_train,y_test=data
clf=ensemble.RandomForestClassifier()
clf.fit(x_train,y_train)
print("Training score:%f"%clf.score(x_train,y_train))
print("Testing score:%f"%clf.score(x_test,y_test)) x_train,x_test,y_train,y_test=load_data_classification()
test_RandomForestClassifier(x_train,x_test,y_train,y_test)
实验结果:
 可以看出其对于分类问题的预测准确率还是比较可观的。调整max_depth参数,通过实验可以得知,随着树的最大深度的提高,随机森林的预测性能也在提高。这主要有两个原因:
可以看出其对于分类问题的预测准确率还是比较可观的。调整max_depth参数,通过实验可以得知,随着树的最大深度的提高,随机森林的预测性能也在提高。这主要有两个原因:
1)决策树的最大深度提高,则每棵树的预测性能也在提高 2)决策树的最大深度提高,则决策树的多样性也在增大
(2)RandomForestRegressor随机森林回归器
实验代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble def load_data_regression():
diabetes=datasets.load_diabetes()
return cross_validation.train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) def test_RandomForestRegressor(*data):
x_train,x_test,y_train,y_test=data
regr=ensemble.RandomForestRegressor()
regr.fit(x_train,y_train)
print("Training score:%f"%regr.score(x_train,y_train))
print("Testing score:%f"%regr.score(x_test,y_test)) x_train,x_test,y_train,y_test=load_data_regression()
test_RandomForestRegressor(x_train,x_test,y_train,y_test)
实验结果:
 回归问题的预测效果还是一如既往的差。。。
回归问题的预测效果还是一如既往的差。。。
python大战机器学习——集成学习的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 《机器学习Python实现_10_10_集成学习_xgboost_原理介绍及回归树的简单实现》
一.简介 xgboost在集成学习中占有重要的一席之位,通常在各大竞赛中作为杀器使用,同时它在工业落地上也很方便,目前针对大数据领域也有各种分布式实现版本,比如xgboost4j-spark,xgbo ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
随机推荐
- 1143. Lowest Common Ancestor (30)
The lowest common ancestor (LCA) of two nodes U and V in a tree is the deepest node that has both U ...
- BZOJ1033:[ZJOI2008]杀蚂蚁
我对模拟的理解:https://www.cnblogs.com/AKMer/p/9064018.html 题目传送门:https://www.lydsy.com/JudgeOnline/problem ...
- 功能强大的Northwoods GoDiagram控件库
Northwoods GoDiagram控件库用于开发图形应用 Northwoods GoDiagram控件库是付费软件,其官方网址为http://www.nwoods.com/ Northwoods ...
- MySQL Sending data导致查询很慢的问题详细分析
这两天帮忙定位一个MySQL查询很慢的问题,定位过程综合各种方法.理论.工具,很有代表性,分享给大家作为新年礼物:) [问题现象] 使用sphinx支持倒排索引,但sphinx从mysql查询源数据的 ...
- Servlet的生命周期以及简单工作原理的讲解
Servlet生命周期分为三个阶段: 1,初始化阶段 调用init()方法 2,响应客户请求阶段 调用service()方法 3,终止阶段 调用destr ...
- Go中使用动态库C/C++库
转自:http://studygolang.com/articles/1441 最近需要做一些在go中使用动态C++库的工作,经常碰到找不到动态库路径这种情况,所以就花点时间,专门做一下实验来了解Go ...
- STL string大小写 转换
std::string data = "This is a sample string."; // convert string to upper case std::for_ea ...
- VC 绘图,使用双缓冲技术实现
VC 绘图,使用双缓冲技术实现 - Cloud-Datacenter-Renewable Energy-Big Data-Model - 博客频道 - CSDN.NET VC 绘图,使用双缓冲技术实现 ...
- 在Action获取Scope对象
引言:在前面的Action操作中,关键就是Action中的exectue方法,但是此方法并没有request.session.application等对象作为参数,自然就不能利用这些对象来操作.下面我 ...
- Socket对象以及异常
1 socket构造器: public Socket() 创建一个Socket套接字 public Socket(InetAddress address,int port) 创建一个指定IP和端口的 ...