吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
import numpy as np from matplotlib import pyplot as plt
from sklearn import neighbors, datasets
from matplotlib.colors import ListedColormap
from sklearn.neural_network import MLPClassifier ## 加载数据集
np.random.seed(0)
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
# 使用前两个特征,方便绘图
X=iris.data[:,0:2]
# 标记值
Y=iris.target
data=np.hstack((X,Y.reshape(Y.size,1)))
# 混洗数据。因为默认的iris 数据集:前50个数据是类别0,中间50个数据是类别1,末尾50个数据是类别2.混洗将打乱这个顺序
np.random.shuffle(data)
X=data[:,:-1]
Y=data[:,-1]
train_x=X[:-30]
train_y=Y[:-30]
# 最后30个样本作为测试集
test_x=X[-30:]
test_y=Y[-30:] def plot_classifier_predict_meshgrid(ax,clf,x_min,x_max,y_min,y_max):
'''
绘制 MLPClassifier 的分类结果 :param ax: Axes 实例,用于绘图
:param clf: MLPClassifier 实例
:param x_min: 第一维特征的最小值
:param x_max: 第一维特征的最大值
:param y_min: 第二维特征的最小值
:param y_max: 第二维特征的最大值
:return: None
'''
plot_step = 0.02 # 步长
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),np.arange(y_min, y_max, plot_step))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘图
ax.contourf(xx, yy, Z, cmap=plt.cm.Paired) def plot_samples(ax,x,y):
'''
绘制二维数据集 :param ax: Axes 实例,用于绘图
:param x: 第一维特征
:param y: 第二维特征
:return: None
'''
n_classes = 3
# 颜色数组。每个类别的样本使用一种颜色
plot_colors = "bry"
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
# 绘图
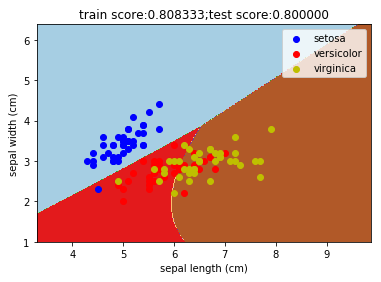
ax.scatter(x[idx, 0], x[idx, 1], c=color,label=iris.target_names[i], cmap=plt.cm.Paired) def mlpclassifier_iris():
'''
使用 MLPClassifier 预测调整后的 iris 数据集
'''
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
classifier=MLPClassifier(activation='logistic',max_iter=10000,hidden_layer_sizes=(30,))
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("train score:%f;test score:%f"%(train_score,test_score))
plt.show() mlpclassifier_iris()
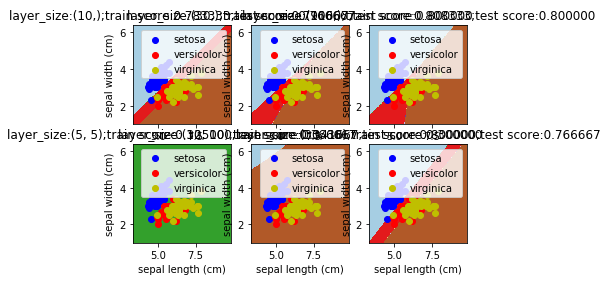
def mlpclassifier_iris_hidden_layer_sizes():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 hidden_layer_sizes 的影响 :return: None
'''
fig=plt.figure()
# 候选的 hidden_layer_sizes 参数值组成的数组
hidden_layer_sizes=[(10,),(30,),(100,),(5,5),(10,10),(30,30)]
for itx,size in enumerate(hidden_layer_sizes):
ax=fig.add_subplot(2,3,itx+1)
classifier=MLPClassifier(activation='logistic',max_iter=10000,hidden_layer_sizes=size)
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("layer_size:%s;train score:%f;test score:%f"%(size,train_score,test_score))
plt.show() mlpclassifier_iris_hidden_layer_sizes()
def mlpclassifier_iris_ativations():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 activation 的影响
'''
fig=plt.figure()
# 候选的激活函数字符串组成的列表
ativations=["logistic","tanh","relu"]
for itx,act in enumerate(ativations):
ax=fig.add_subplot(1,3,itx+1)
classifier=MLPClassifier(activation=act,max_iter=10000,hidden_layer_sizes=(30,))
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("activation:%s;train score:%f;test score:%f"%(act,train_score,test_score))
plt.show() mlpclassifier_iris_ativations()

def mlpclassifier_iris_algorithms():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 algorithm 的影响 :return: None
'''
fig=plt.figure()
algorithms=["lbfgs","sgd","adam"] # 候选的算法字符串组成的列表
for itx,algo in enumerate(algorithms):
ax=fig.add_subplot(1,3,itx+1)
classifier=MLPClassifier(activation="tanh",max_iter=10000,hidden_layer_sizes=(30,),solver=algo)
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("algorithm:%s;train score:%f;test score:%f"%(algo,train_score,test_score))
plt.show() mlpclassifier_iris_algorithms()

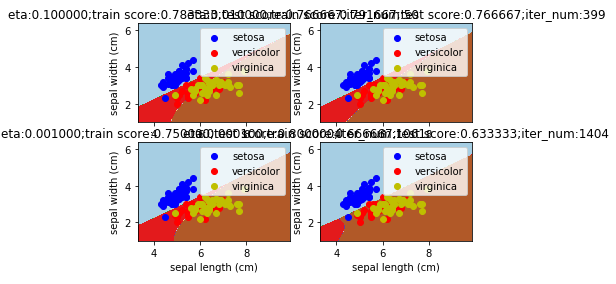
def mlpclassifier_iris_eta():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的学习率的影响
'''
fig=plt.figure()
etas=[0.1,0.01,0.001,0.0001] # 候选的学习率值组成的列表
for itx,eta in enumerate(etas):
ax=fig.add_subplot(2,2,itx+1)
classifier=MLPClassifier(activation="tanh",max_iter=1000000,
hidden_layer_sizes=(30,),solver='sgd',learning_rate_init=eta)
classifier.fit(train_x,train_y)
iter_num=classifier.n_iter_
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("eta:%f;train score:%f;test score:%f;iter_num:%d"%(eta,train_score,test_score,iter_num))
plt.show() mlpclassifier_iris_eta()
吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用的更多相关文章
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 人工智能——基于神经网络算法在智能医疗诊断中的应用探索代码简要展示
#K-NN分类 import os import sys import time import operator import cx_Oracle import numpy as np import ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
随机推荐
- Phalanx HDU - 2859 dp
#include<cstdio> #include<cstring> #include<algorithm> #include<iostream> us ...
- 机器学习作业(七)非监督学习——Matlab实现
题目下载[传送门] 第1题 简述:实现K-means聚类,并应用到图像压缩上. 第1步:实现kMeansInitCentroids函数,初始化聚类中心: function centroids = kM ...
- Initialization of bean failed; nested exception is java.lang.NoClassDefFoundError: org/objectweb/asm/Type
问题描述 将项目挂载到 Myeclipse 的 tomcat 上,启动 tomcat ,报错“Initialization of bean failed; nested exception is ja ...
- 【转】Java Future 怎么用 才算是真正异步
接着上一篇继续并发包的学习,本篇说明的是Callable和Future,它俩很有意思的,一个产生结果,一个拿到结果. Callable接口类似于Runnable,从名字就可以看出来了,但 ...
- 转行小白成长路--java基础
每天都会发一篇,一点一滴,记录在这条路上的足迹.立个flag 2019年3月份至今已近一年,对信息技术有个大概的了解,个人认为对于这门技术更应该从最底层的原理入手,了解计算机演化的历史,从计算机语言到 ...
- 巨杉内核笔记 | 会话(Session)
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库,坚持从零开始打造分布式开源数据库引擎.“内核笔记系列”旨在分享交流 SequoiaDB 巨杉数据库引擎的设计思路和代码解析,帮助社区用户深 ...
- C++-POJ2159-Candies[spfa][栈优化][邻接表]
#include <cstdio> ,N=; struct edge{int v,w,next;}e[M];int head[N],cnt; void add(int u,int v,in ...
- java-判断年份是不是闰年
if ((year%4==0)&&(year%100!=0)||(year%400==0)) {//是闰年 leapYear = true; }
- codeforces 1284E. New Year and Castle Construction(极角排序+扫描枚举)
链接:https://codeforces.com/problemset/problem/1284/E 题意:平面上有n个点,问你存在多少组四个点围成的四边形 严格包围某个点P的情况.不存在三点共线. ...
- c++ char转换成string
第一种:利用赋值号直接赋值 ; string b = a; /* 错误.因为string是一个指针,存储的值是所指向的地址,而char型存储的是内容,所以不可以直接用赋值号赋值 */ const ch ...