自然语言12_Tokenizing Words and Sentences with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

https://www.pythonprogramming.net/tokenizing-words-sentences-nltk-tutorial/
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016 @author: daxiong
""" from nltk.tokenize import sent_tokenize,word_tokenize example_text="Five score years ago, a great American, in whose symbolic shadow we stand today, signed the Emancipation Proclamation. This momentous decree came as a great beacon light of hope to millions of Negro slaves who had been seared in the flames of withering injustice. It came as a joyous daybreak to end the long night of bad captivity." list_sentences=sent_tokenize(example_text) list_words=word_tokenize(example_text)
代码测试

Tokenizing Words and Sentences with NLTK
Welcome to a Natural Language Processing tutorial series, using the Natural Language Toolkit, or NLTK, module with Python.
The NLTK module is a massive tool kit, aimed at helping you with
the entire Natural Language Processing (NLP) methodology. NLTK will aid
you with everything from splitting sentences from paragraphs, splitting
up words, recognizing the part of speech of those words, highlighting
the main subjects, and then even with helping your machine to understand
what the text is all about. In this series, we're going to tackle the
field of opinion mining, or sentiment analysis.
In our path to learning how to do sentiment analysis with NLTK, we're going to learn the following:
- Tokenizing - Splitting sentences and words from the body of text.
- Part of Speech tagging
- Machine Learning with the Naive Bayes classifier
- How to tie in Scikit-learn (sklearn) with NLTK
- Training classifiers with datasets
- Performing live, streaming, sentiment analysis with Twitter.
- ...and much more.
In order to get started, you are going to need the NLTK module, as well as Python.
If you do not have Python yet, go to Python.org and download the latest version of Python if you are on Windows. If you are on Mac or Linux, you should be able to run an apt-get install python3
Next, you're going to need NLTK 3. The easiest method to installing the NLTK module is going to be with pip.
For all users, that is done by opening up cmd.exe, bash, or whatever shell you use and typing:pip install nltk
Next, we need to install some of the components for NLTK. Open python via whatever means you normally do, and type:
import nltk
nltk.download()
Unless you are operating headless, a GUI will pop up like this, only probably with red instead of green:
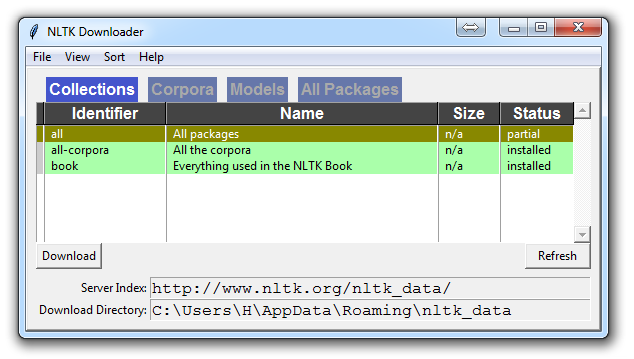
Choose to download "all" for all packages, and then click 'download.' This will give you all of the tokenizers, chunkers, other algorithms, and all of the corpora. If space is an issue, you can elect to selectively download everything manually. The NLTK module will take up about 7MB, and the entire nltk_data directory will take up about 1.8GB, which includes your chunkers, parsers, and the corpora.
If you are operating headless, like on a VPS, you can install everything by running Python and doing:
import nltk
nltk.download()
d (for download)
all (for download everything)
That will download everything for you headlessly.
Now that you have all the things that you need, let's knock out some quick vocabulary:
- Corpus - Body of text, singular. Corpora is the plural of this. Example: A collection of medical journals.
- Lexicon - Words and their meanings. Example: English dictionary. Consider, however, that various fields will have different lexicons. For example: To a financial investor, the first meaning for the word "Bull" is someone who is confident about the market, as compared to the common English lexicon, where the first meaning for the word "Bull" is an animal. As such, there is a special lexicon for financial investors, doctors, children, mechanics, and so on.
- Token - Each "entity" that is a part of whatever was split up based on rules. For examples, each word is a token when a sentence is "tokenized" into words. Each sentence can also be a token, if you tokenized the sentences out of a paragraph.
These are the words you will most commonly hear upon entering the Natural Language Processing (NLP) space, but there are many more that we will be covering in time. With that, let's show an example of how one might actually tokenize something into tokens with the NLTK module.
from nltk.tokenize import sent_tokenize, word_tokenize EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard." print(sent_tokenize(EXAMPLE_TEXT))
At first, you may think tokenizing by things like words or sentences is a rather trivial enterprise. For many sentences it can be. The first step would be likely doing a simple .split('. '), or splitting by period followed by a space. Then maybe you would bring in some regular expressions to split by period, space, and then a capital letter. The problem is that things like Mr. Smith would cause you trouble, and many other things. Splitting by word is also a challenge, especially when considering things like concatenations like we and are to we're. NLTK is going to go ahead and just save you a ton of time with this seemingly simple, yet very complex, operation.
The above code will output the sentences, split up into a list of sentences, which you can do things like iterate through with a for loop.['Hello
Mr. Smith, how are you doing today?', 'The weather is great, and Python
is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat
cardboard."]
So there, we have created tokens, which are sentences. Let's tokenize by word instead this time:
print(word_tokenize(EXAMPLE_TEXT))
Now our output is: ['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']
There are a few things to note here. First, notice that punctuation is treated as a separate token. Also, notice the separation of the word "shouldn't" into "should" and "n't." Finally, notice that "pinkish-blue" is indeed treated like the "one word" it was meant to be turned into. Pretty cool!
Now, looking at these tokenized words, we have to begin thinking about what our next step might be. We start to ponder about how might we derive meaning by looking at these words. We can clearly think of ways to put value to many words, but we also see a few words that are basically worthless. These are a form of "stop words," which we can also handle for. That is what we're going to be talking about in the next tutorial.

自然语言12_Tokenizing Words and Sentences with NLTK的更多相关文章
- 自然语言27_Converting words to Features with NLTK
https://www.pythonprogramming.net/words-as-features-nltk-tutorial/ Converting words to Features with ...
- 自然语言18.1_Named Entity Recognition with NLTK
QQ:231469242 欢迎nltk爱好者交流 https://www.pythonprogramming.net/named-entity-recognition-nltk-tutorial/?c ...
- 自然语言15_Part of Speech Tagging with NLTK
https://www.pythonprogramming.net/part-of-speech-tagging-nltk-tutorial/?completed=/stemming-nltk-tut ...
- 自然语言处理NLP程序包(NLTK/spaCy)使用总结
NLTK和SpaCy是NLP的Python应用,提供了一些现成的处理工具和数据接口.下面介绍它们的一些常用功能和特性,便于对NLP研究的组成形式有一个基本的了解. NLTK Natural Langu ...
- 初识NLTK
需要用处理英文文本,于是用到python中nltk这个包 f = open(r"D:\Postgraduate\Python\Python爬取美国商标局专利\s_exp.txt") ...
- Python 自然语言处理(1) 计数词汇
Python有一个自然语言处理的工具包,叫做NLTK(Natural Language ToolKit),可以帮助你实现自然语言挖掘,语言建模等等工作.但是没有NLTK,也一样可以实现简单的词类统计. ...
- 【Python自然语言处理】第一章学习笔记——搜索文本、计数统计和字符串链表
这本书主要是基于Python和一个自然语言工具包(Natural Language Toolkit, NLTK)的开源库进行讲解 NLTK 介绍:NLTK是一个构建Python程序以处理人类语言数据的 ...
- python笔记10-----便捷网络数据NLTK语料库
1.NLTK的概念 NLTK:Natural language toolkit,是一套基于python的自然语言处理工具. 2.NLTK中集成了语料与模型等的包管理器,通过在python编辑器中执行. ...
- python机器学习——分词
使用jieba库进行分词 安装jieba就不说了,自行百度! import jieba 将标题分词,并转为list seg_list = list(jieba.cut(result.get(" ...
随机推荐
- jq实现登陆页面的拖拽功能
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <script src ...
- centos 7 下进入单用户模式修改root密码
centos7进入单用户模式修改root用户密码 在工作中可能会遇到root密码忘记,那么这里就要进入单用户模式下了. 在重启电脑之后 时间:2015-05-13 10:42来源:blog.51cto ...
- Android判断当前系统时间是否在指定时间的范围内(免消息打扰)
/** * 判断当前系统时间是否在指定时间的范围内 * * @param beginHour * 开始小时,例如22 * @param beginMin * 开始小时的分钟数,例如30 * @para ...
- shell中substr总结
(1)awk中函数substr substr(源字符串,开始索引,长度) 开始索引以0开始 示例: awk '{$a=substr($0,0,2);print $a;}' filename 假设文 ...
- 从CIO、CEO、CFO、COO...到CVO 这22个你了解几个? (史上最完整版)
1.CEO:是Chief Executive Officer的缩写,即首席执行官. 由于市场风云变幻,决策的速度和执行的力度比以往任何时候都更加重要.传统的“董事会决策.经理层执行”的公司体制已经难以 ...
- R语言快速入门上手
导言: 较早之前就听说R是一门便捷的数据分析工具,但由于课程设计的原因,一直没有空出足够时间来进行学习.最近自从决定本科毕业出来找工作之后,渐渐开始接触大数据行业的技术,现在觉得是时候把R拿下 ...
- 【BZOJ-1336&1337】Alie最小圆覆盖 最小圆覆盖(随机增量法)
1336: [Balkan2002]Alien最小圆覆盖 Time Limit: 1 Sec Memory Limit: 162 MBSec Special JudgeSubmit: 1573 ...
- Python:Sqlmap源码精读之解析xml
XML <?xml version="1.0" encoding="UTF-8"?> <root> <!-- MySQL --&g ...
- 【poj2774】 Long Long Message
http://poj.org/problem?id=2774 (题目链接) 题意 给出两个只包含小写字母的字符串,求出最长连续公共子串. solution 第一次用后缀数组,感觉有点神...才发现原来 ...
- Stream篇
本文转自: http://www.cnblogs.com/JimmyZheng/archive/2012/03/17/2402814.html 什么是Stream? 什么是字节序列? Stream的构 ...