CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术
对同一个对象不去update,而且记录下每一次的不同版本的值
存在不会消失,新值并不能抹杀原先的存在
所以update操作并不是对世界的真实反映,这是一种便于应用的简化实现

MVCC的历史可以追溯到70年代,数据库的主流技术大部分都停滞在那个年代
MVCC,可以解决2PC的频繁读写冲突;使用MVCC只有写写才会存在冲突,大大降低了冲突的概率
而且MVCC还能进行time-travel


例子,DB中有Begin,End表示该version生效的时间周期,write的时候会产生新的version,同时修改上一个version的end
右图,仍然读的是A0,因为t1的ts=1,在A0的范围中

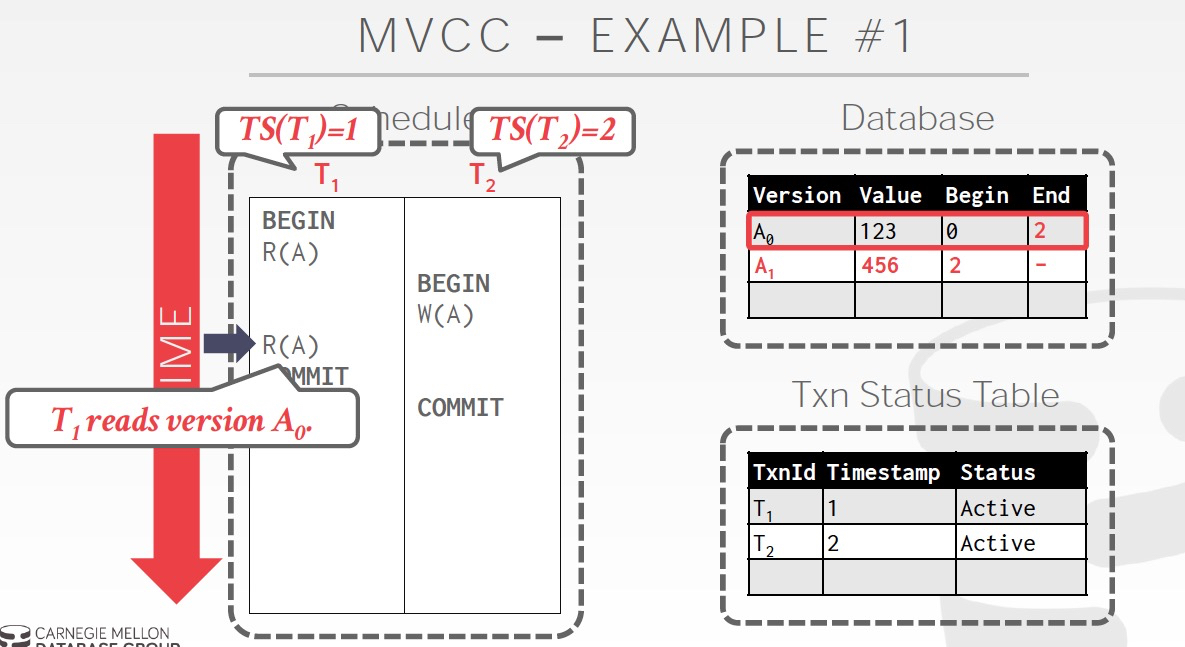
例子,
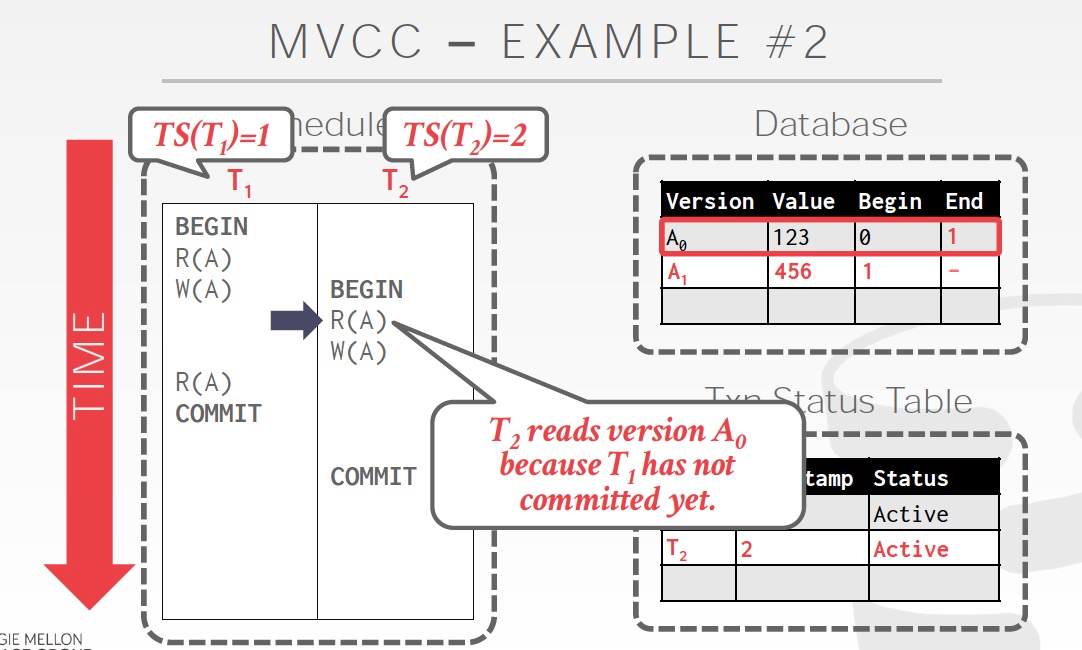
T2的R读到的是A0,因为T1还没有commit(取决于隔离程度) ;并且T2执行W的时候会锁等,因为写写发生冲突
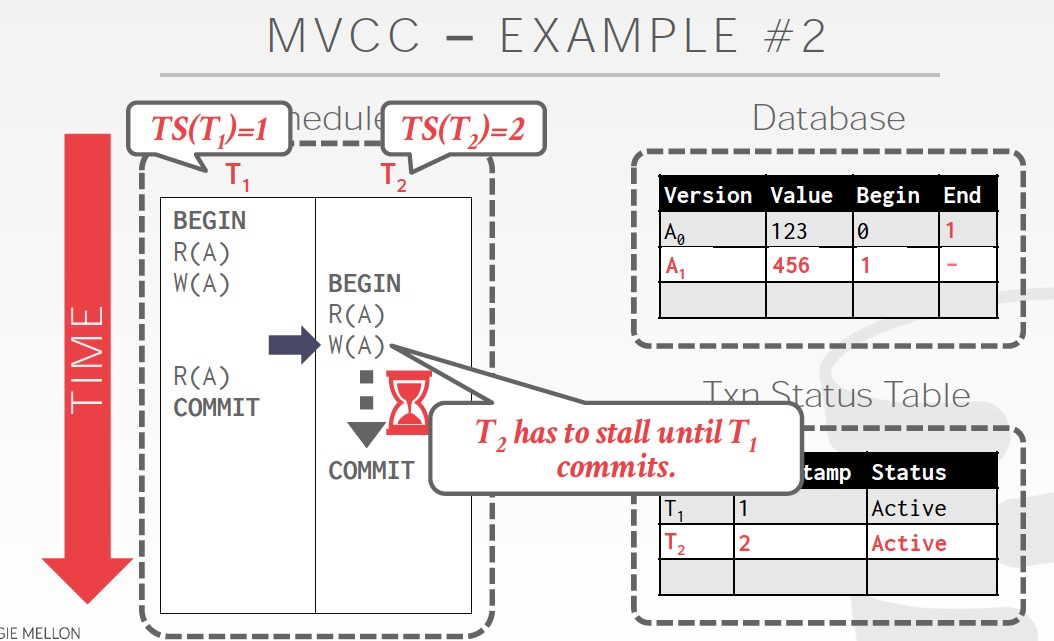
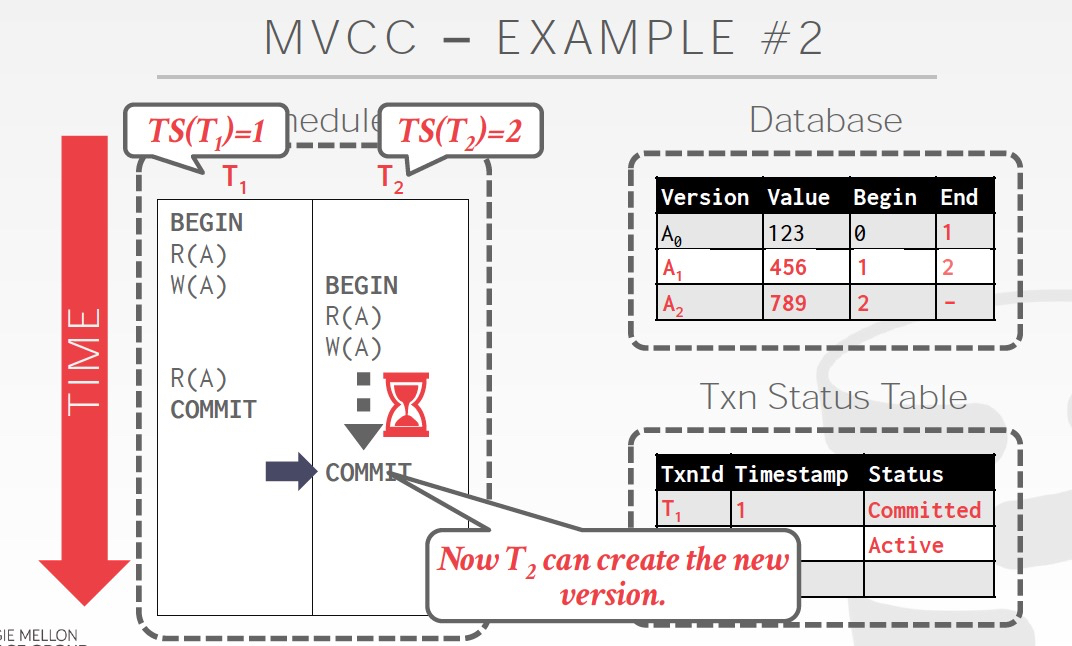
当T1 commit后,T2的锁释放,开始写入
这时候的行为取决于隔离程度,如果serializable的,那么T2会失败,因为T2读的是A0,而这时看T2应该读的是A1,所以存在不一致
下面的图表明MVCC被大量的数据库所使用,

MVCC在发生写写冲突时,仍然是需要并发控制协议,主要是之前学习的2PC或OCC

多版本的存储方式,主要有如下的方式,


Append Only,比较直接的方式,HBase,PG都是采用这种方式
为了快速找到同一个对象的多个版本,可以用链表来组织,那么旧的放前面,还是新的放见面,完全是看场景
新的放前面比较直觉,因为一般都是需要读最新的数据,但是这样每次新增都需要更新head指针
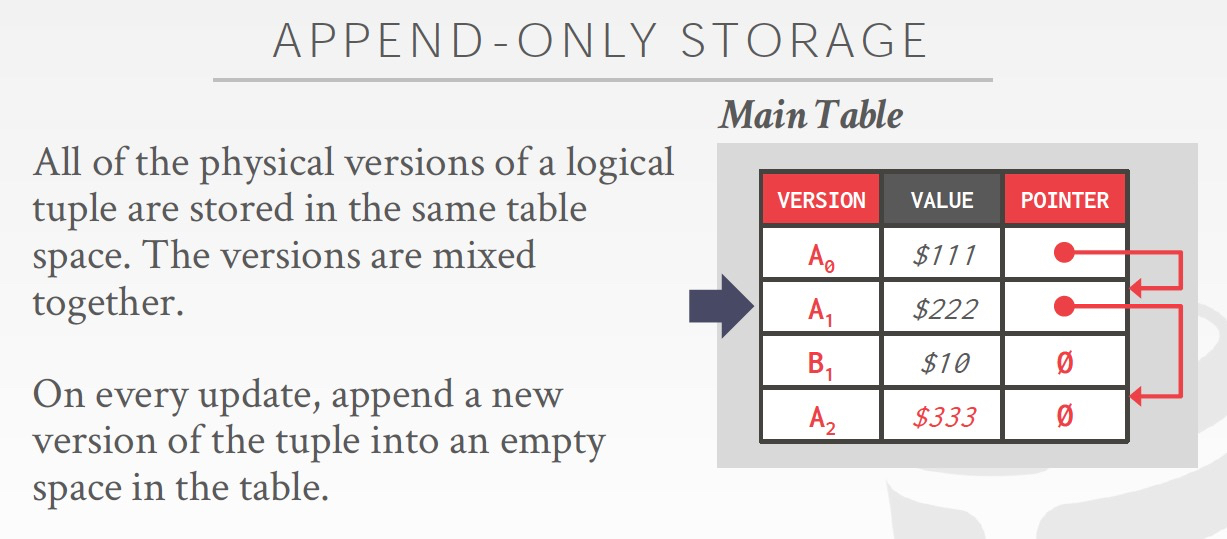

Time travel就是把最新的table和历史table分离
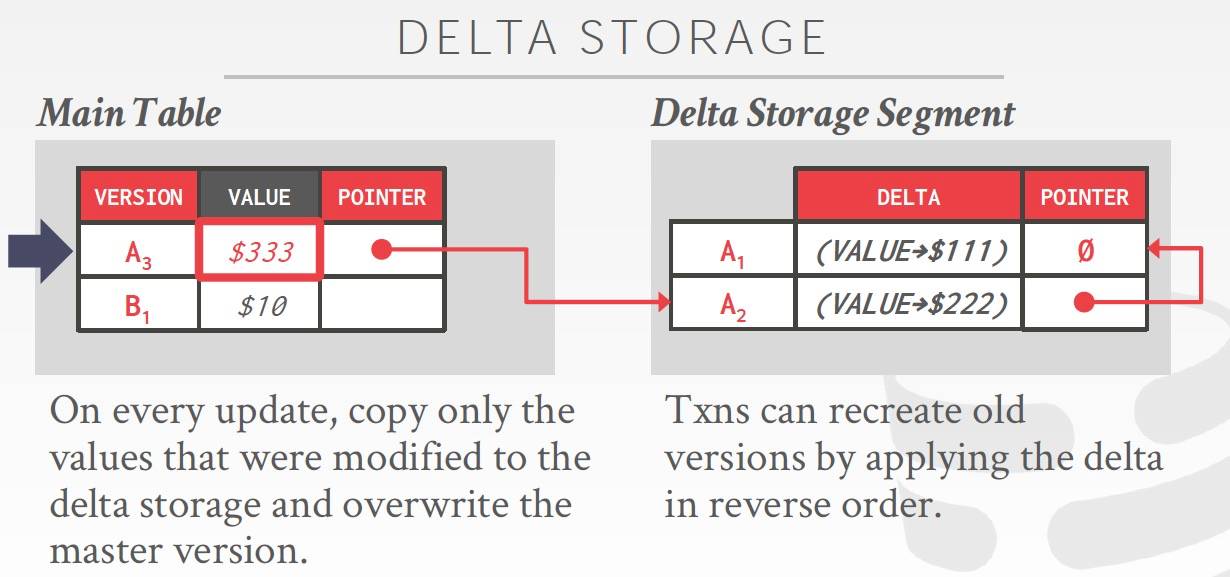
Delta只记录差值

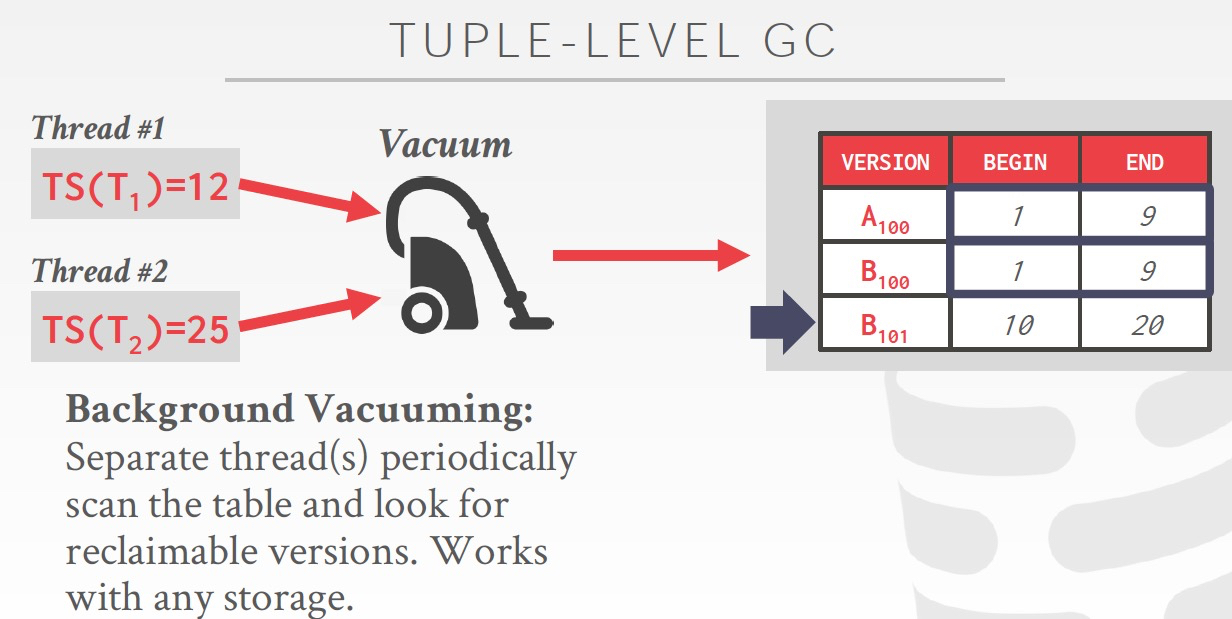
垃圾回收,纯粹是工程实践,


定期过期活跃thread已经不用时间段的数据,这里有个设计是,加上Bitmap来表示这个page是否有更新,这样Vacumm不用去检查每个page,没更新的就不用检查
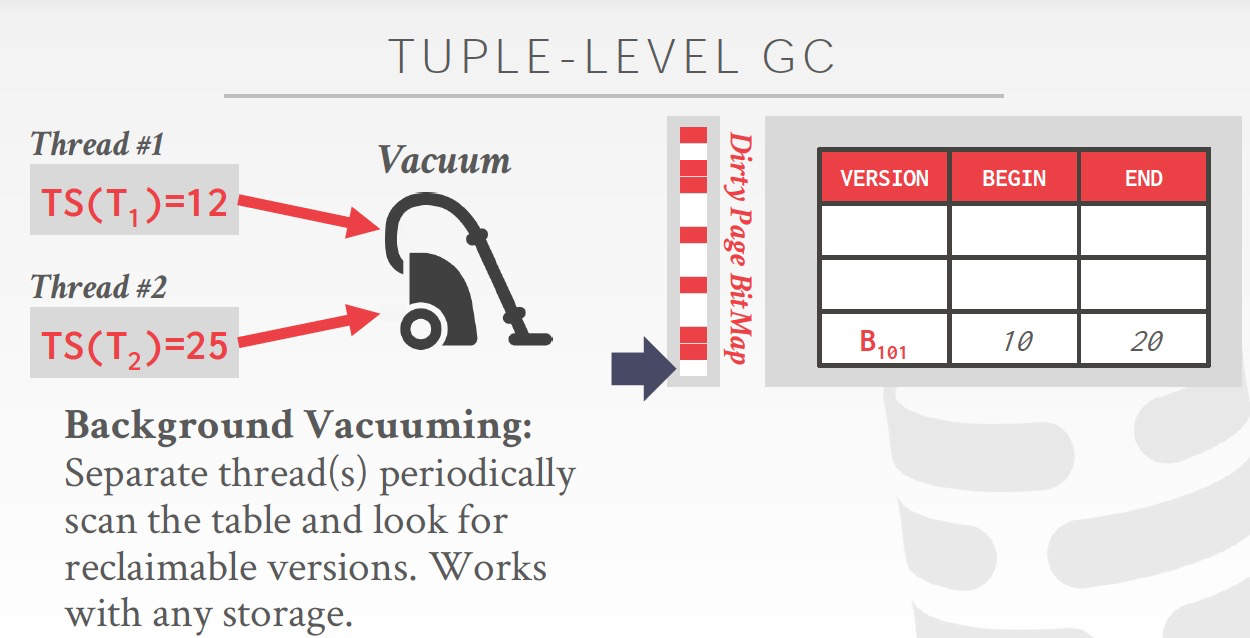
Worker thread在遍历的时候,随便找到过期的

如果用MVCC,那么index就需要指向chain head
可以看到对于secondary index,如果有很多,每次head变化都要更新很多,非常低效


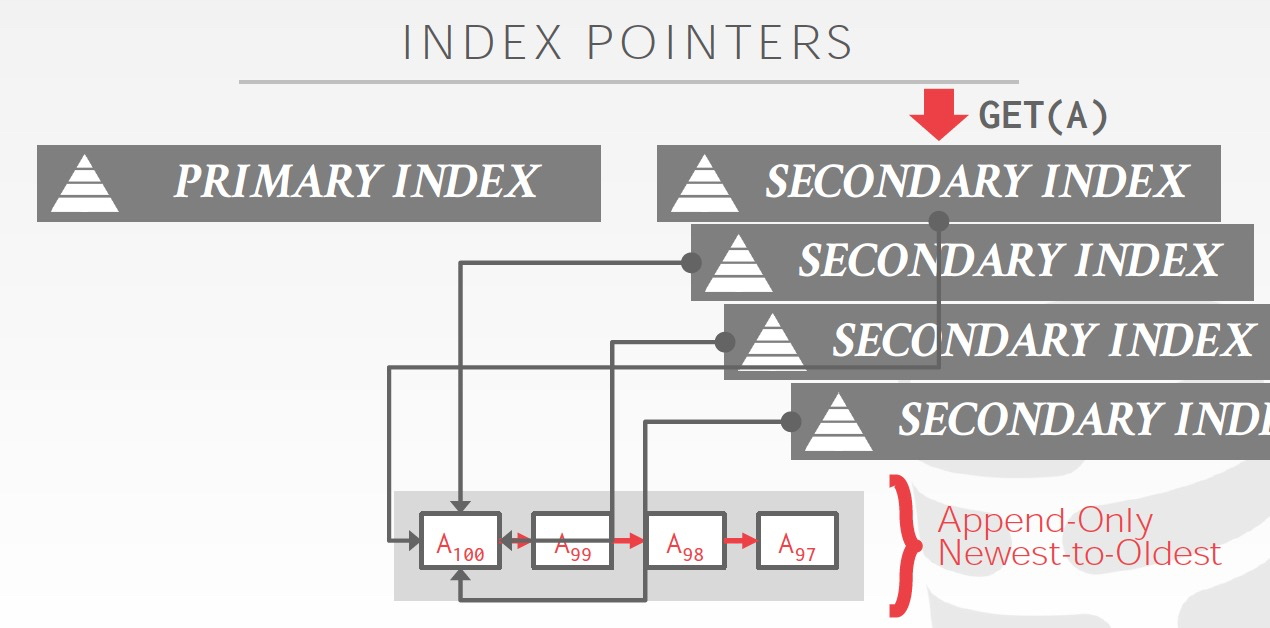
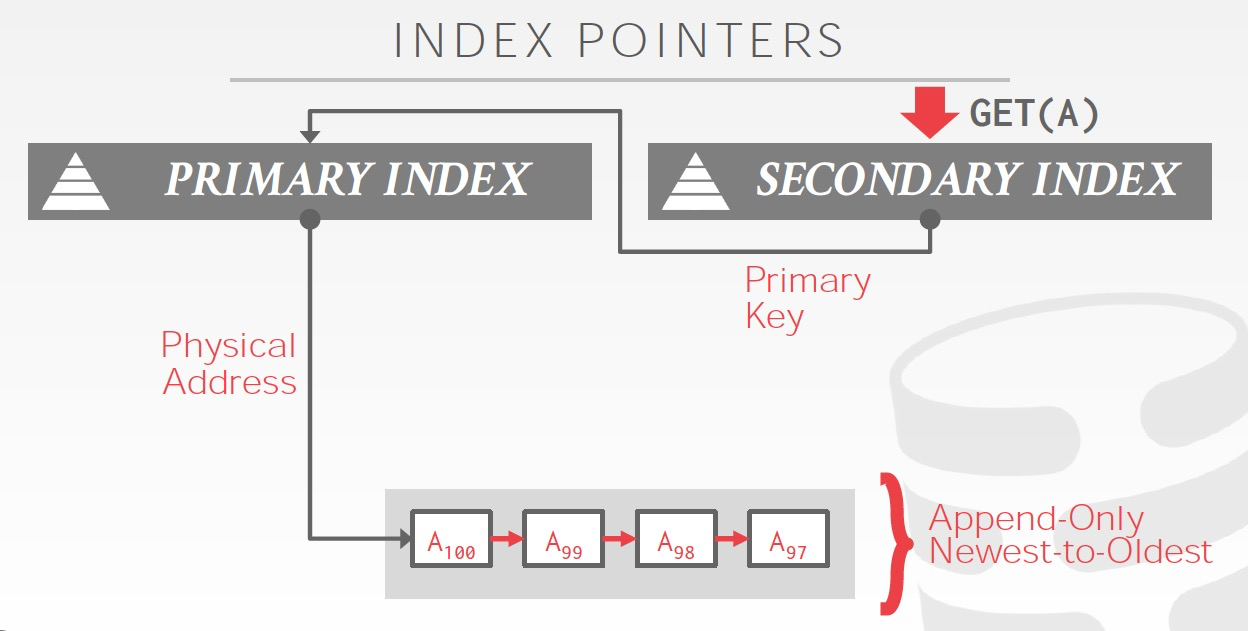
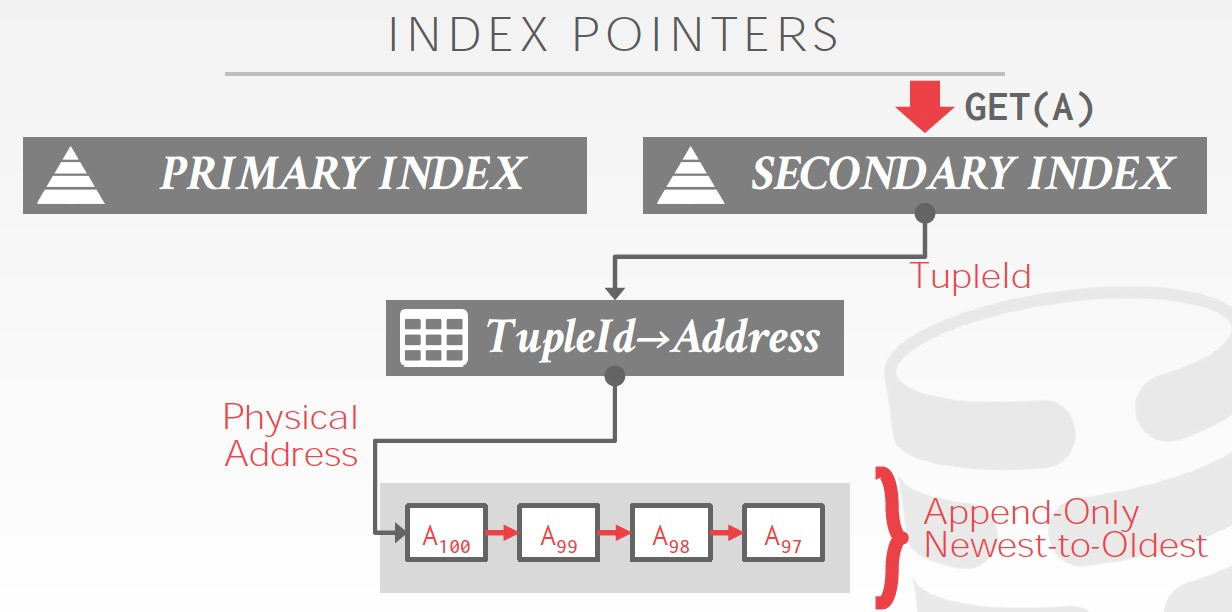
所以有两种方式,
思路都是,通过逻辑id,间接的指向Physical address,这样只需要改一个地方
这里列出所有数据库在MVCC上的实现方式

CMU Database Systems - MVCC的更多相关文章
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
随机推荐
- POSIX多线程之创建线程pthread_create && 线程清理pthread_cleanup
多线程之pthread_create创建线程 pthreads定义了一套C程序语言类型.函数.与常量.以pthread.h和一个线程库实现. 数据类型: pthread_t:线程句柄 pthread_ ...
- 编译 Unity 4.3.1 引擎源码
引言 Unity 官方从 Unity 2017.1 版本开始,开源了引擎和编辑器的C#源码(源码地址:UnityCsReference),但核心的 C/C++ 部分源码并未开源. 编译环境 网上主要的 ...
- SQL SERVER升级2017
SQL SERVER升级2017 摘要 本文只介绍了SQL SERVER升级到2017(在简单环境下),分为开始升级前的检查事项,升级操作步骤,升级后对新实例的配置. 检查事项 1.检查当前版本是否可 ...
- java验证邮件正则
这里,本人从commons-validator包中源码,拷出部分内容,如下: private static final String EMAIL_REGEX = "^\\s*?(.+)@(. ...
- 【原创】python+selenium,用xlrd,读取excel数据,执行测试用例
# -*- coding: utf-8 -*- import unittest import time from selenium import webdriver import xlrd,xlwt ...
- WinForm 捕获异常 Application.ThreadException + AppDomain.CurrentDomain.UnhandledException
WinForm 捕获未处理的异常,可以使用Application.ThreadException 和AppDomain.CurrentDomain.UnhandledException事件 WinF ...
- 关于jsp页面中name=“username”与name=“username ”的区别
我们可以仔细的观察一下,上面的name属性都等于username,但是确实存在大同小异的差距,为什么这样说呢,因为,第二个比第一个多了一个空格,在jsp中,我曾经遇到过一个情况就是两个单选按钮用同一个 ...
- HDU - 5823:color II (状压DP 反演DP)
题意:给定连通图,求出连通图的所有子图的颜色数. 一个图的颜色数,指最少的颜色数,给图染色,使得有边相邻的点之间颜色不同. 思路:首先想法是DFS枚举,然后计算颜色,发现对于给定图,求颜色不会求? 毕 ...
- python 中的tile函数,shape函数,sum函数
1.tile函数: tile函数是模板numpy.lib.shape_base中的函数.函数的形式是tile(A,reps) A的类型几乎所有类型都可以:array, list, tuple, dic ...
- pandas 常用方法使用示例
from pandas import DataFrame import numpy as np import pandas as pd t={ , , np.nan, , np.nan, ], &qu ...