爬虫---Beautiful Soup 通过添加不同的IP请求
上一篇爬虫写了如何应付反爬的一些策略也简单的举了根据UA的例子,今天写一篇如何根据不同IP进行访问豆瓣网获取排行版
requests添加IP代理
如果使用代理的话可以通过requests中的方法proxies
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy. 太多了,删除了一些留下了主要
会有人问,这么多代理去哪里找?小编百度了找了一些发现西刺代理挺好用的。
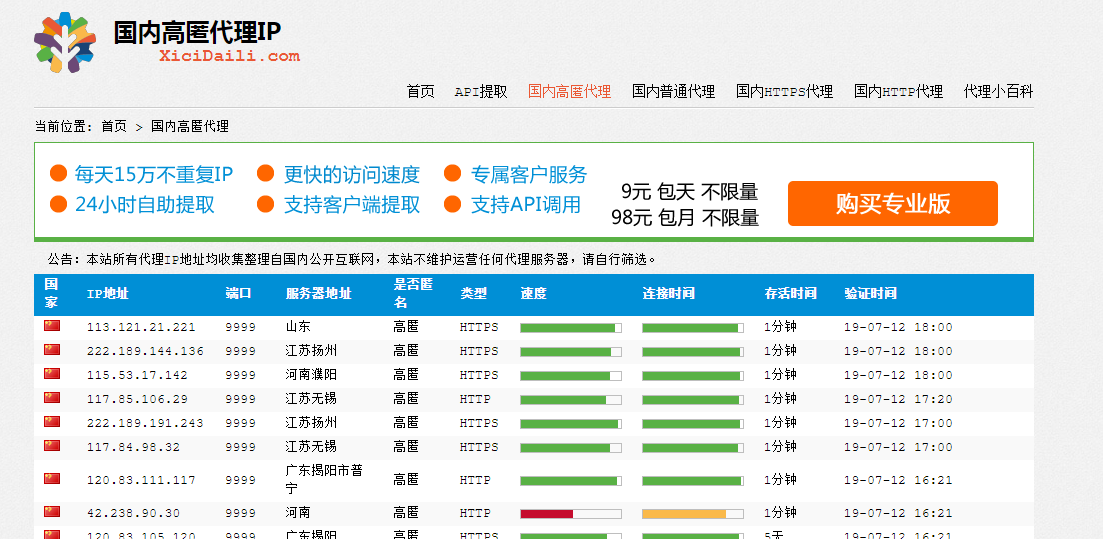
随便从里面找1个进行发请求
# coding:utf-8
import requests
url ="http://httpbin.org/get"
proxy = '117.191.11.73:80'
proxies = {
'http':'http://'+proxy,
'https':'https://'+ proxy
}
r =requests.get(url,proxies=proxies)
print(r.text) 代码结果:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0",
"X-Via": "Cache-363"
},
"origin": "117.191.11.73, 117.191.11.73",
"url": "https://httpbin.org/get"
}
通过代理抓取豆瓣网
1.通过requests请求地址:https://movie.douban.com/top250
2.添加代理IP
3.通过Beautiful Soup获取Html页面
4.进行分析Html页面,完成对导演,电影名称,评分的抓取
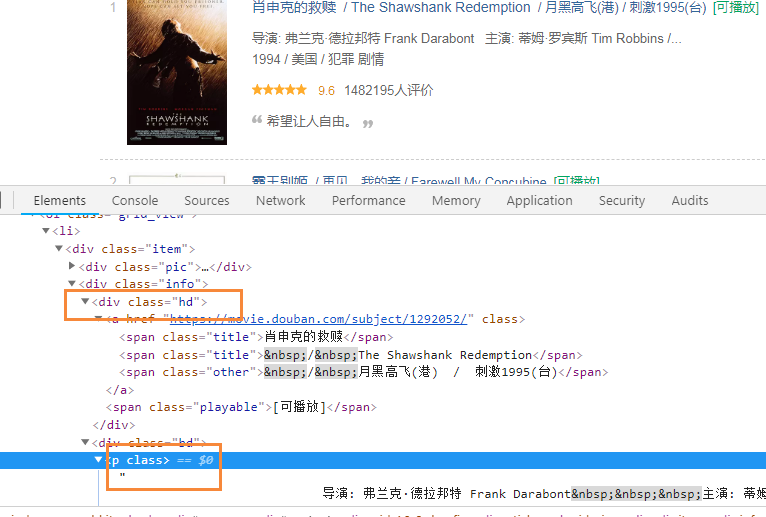
代码结果:
import requests
from bs4 import BeautifulSoup
import re
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2372.400 QQBrowser/9.5.10548.400'
}
# 添加代理
proxies = {
'http':'http://113.121.22.92:808',}
r = requests.get(url,headers=headers,proxies=proxies)
html = r.content.decode('utf-8')
blog = BeautifulSoup(html,'html.parser')
daoyan = blog.find_all('p',class_='') # 导演
titles = blog.find_all('div',class_='hd') # 电影名称
pingfen = blog.find_all('span',class_='rating_num') # 评分
for title,daoya, pingfe in zip(titles,daoyan,pingfen):
m = title.get_text().split('\n')[2]
x = daoya.get_text().strip()
x1 = re.findall(r'导演: (.*?)\xa0',x)
cc = pingfe.get_text()
print(m)
print(x1)
print(cc)
代码执行完后发现只抓取了第一页的数据,而我们想要的时候全部数据,那么我们就继续分析URL路径
# 第一页的URL地址
https://movie.douban.com/top250 # 第二页的URL地址
https://movie.douban.com/top250?start=25&filter= # 第三页的URL地址
https://movie.douban.com/top250?start=50&filter=
经过观察我们可以发现后面唯一变得数据就是start,那么我们可以通过拼接URL获取全部数据,并且把这么数据写入到TXT文件中
import requests
from bs4 import BeautifulSoup
import re
page = 0
base_url = 'https://movie.douban.com/top250?start='
# 通过循环拼接URL
while page<10:
url = base_url + str(25*page)
page += 1
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'/Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2372.400 QQBrowser/9.5.10548.400'
}
# IP代理
proxies = {
'http':'http://113.121.22.92:808',}
r = requests.get(url,headers=headers,proxies=proxies)
html = r.content.decode('utf-8')
blog = BeautifulSoup(html,'html.parser')
daoyan = blog.find_all('p',class_='') # 导演
titles = blog.find_all('div',class_='hd') # 电影名称
pingfen = blog.find_all('span',class_='rating_num') # 评分
for title,daoya, pingfe in zip(titles,daoyan,pingfen):
m = title.get_text().split('\n')[2]
x = daoya.get_text().strip()
x1 = re.findall(r'导演: (.*?)\xa0',x)
cc = pingfe.get_text()
# 写入到txt文件中
with open('123.txt','a+',encoding='utf-8')as f :
f.write('{m}\t{x1}\t{cc}\n'.format(m=m,x1=x1,cc=cc))
通过查看TXT文件,发现已经成功的获取到了豆瓣网的电影信息。

这个案例只是简单的表达我们可以通过IP代理的方式进行来完成爬虫(当然不用代理一样可以请求成功,只是简单的表达下思想,思想学会了,其他的都是简单的问题了)
以后我们如果遇到了封IP的网站都可以通过添加IP代理的方式进行爬取数据;
如果感觉安静写的内容对你有帮助,请点击个关注,内容持续更新中~~~~~
爬虫---Beautiful Soup 通过添加不同的IP请求的更多相关文章
- 爬虫---Beautiful Soup 反反爬虫事例
前两章简单的讲了Beautiful Soup的用法,在爬虫的过程中相信都遇到过一些反爬虫,如何跳过这些反爬虫呢?今天通过知乎网写一个简单的反爬中 什么是反爬虫 简单的说就是使用任何技术手段,阻止别人批 ...
- 爬虫---Beautiful Soup 初始
我们在工作中,都会听说过爬虫,那么什么是爬虫呢? 什么是网络爬虫 爬虫基本原理 所谓网络爬虫就是一个自动化数据采集工具,你只要告诉它要采集哪些数据,丢给它一个 URL,就能自动地抓取数据了.其背后的基 ...
- 爬虫-Beautiful Soup模块
阅读目录 一 介绍 二 基本使用 三 遍历文档树 四 搜索文档树 五 修改文档树 六 总结 一 介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通 ...
- 爬虫---Beautiful Soup 爬取图片
上一篇简单的介绍Beautiful Soup 的基本用法,这一篇写下如何爬取网站上的图片,并保存下来 爬取图片 1.找到一个福利网站:http://www.xiaohuar.com/list-1-1. ...
- Python爬虫利器:Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.使用它来处理HTML页面就像JavaScript代码操作HTML DOM树一样方便.官方中文文档地址 1. 安 ...
- python爬虫之解析库Beautiful Soup
为何要用Beautiful Soup Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式, 是一个 ...
- python 爬虫利器 Beautiful Soup
python 爬虫利器 Beautiful Soup Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文 ...
- 使用Beautiful Soup编写一个爬虫 系列随笔汇总
这几篇博文只是为了记录学习Beautiful Soup的过程,不仅方便自己以后查看,也许能帮到同样在学习这个技术的朋友.通过学习Beautiful Soup基础知识 完成了一个简单的爬虫服务:从all ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
随机推荐
- client-go集群外认证k8s
除了认证外,还判断了操作系统. 且根据不同的系统,生成不同的文件. 在集群外认证时,使用的是k8s官方的方式, 而不是第三方库. package main import ( "flag&qu ...
- vue-router 之 keep-alive路由缓存处理include+exclude
keep-alive 简介 keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,或避免重新渲染. 用法也很简单: <keep-alive> <compone ...
- 并发编程学习笔记(七、Thread源码分析)
目录: 常见属性 构造函数 start() run() 常见属性: /** * 线程名称 */ private volatile String name; /** * 线程优先级 */ private ...
- MongoDB高级知识(六)
1. document的关系 多个文档之间在逻辑上可以相互联系,可以通过嵌入和引用来建立联系. 文档之间的关系可以有: 1对1 1对多 多对1 多对多 一个用户可以有多个地址,所以是一对多的关系. # ...
- MongoDB介绍(一)
MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功 ...
- 第九周周四计划&&周三总结
今天由于自己的原因进度不是很大,今天整理了一下全网关联的思路流程(个人可能就是那种没自信,在思路不知道对不对的情况下不敢下手那种渣渣),和之前的一个学长讨论了一下大概思路流程,如下: (1)使用LDA ...
- 高性能MySQL count(1)与count(*)的差别
-------------------------------------------------------------------------------------------------第一篇 ...
- 群体遗传之ped格式
1.PED简介 PED文件格式是广泛使用的用于连锁系谱数据分析的格式,并用作plink程序的输入.PLINK是一个免费的,开源的全基因组关联分析工集,旨在以高计算效率的方式执行一系列基本的,大规模的分 ...
- oracle序列相关
一. oracle中如何实现一列的规律增长呢(通常是指number类型的列)? 这就需要借助序列来实现了; 1. 什么是序列? 可以理解为序列是一组sql语法创建出来的函数, 该函数中定义 好 ...
- 我的周记13——”离开,是为了更好的回来"
一点分享 生存是一种即时策略游戏,所有的人都是这场游戏的玩家.财务自由了,就是游戏赢家. 具体来说,又分成两种游戏:财富游戏和地位游戏.财富游戏的玩家追求更多的财富,地位游戏的玩家追求更高的地位. 古 ...