xpath+多进程爬取全书网纯爱耽美类别的所有小说。
# 需要的库
import requests
from lxml import etree
from multiprocessing import Pool
import os
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 创建存储路径
pathname = './全书网/'
if not os.path.exists(pathname):
os.mkdir(pathname)
# 获取书籍列表
def get_booklist(url):
try:
response = requests.get(url=url,headers=headers)
etrees = etree.HTML(response.text)
sum = etrees.xpath('//a[@class="last"]/text()')[0]
booklist = etrees.xpath('//ul[@class="seeWell cf"]/li')
book_list = []
for books in booklist:
book = books.xpath('./a/@href')[0]
book_list.append(book)
pool.map(get_book,book_list)
urls = ['http://www.quanshuwang.com/list/3_{}.html'.format(i) for i in range(2,int(sum)+1)]
pool.map(get_booklist,urls)
except Exception:
print('get_booklist failed')
# 获取具体书籍
def get_book(url):
try:
response = requests.get(url=url, headers=headers)
etrees = etree.HTML(response.content.decode("gb18030"))
book_name = etrees.xpath('//div[@class="b-info"]/h1/text()')[0]
if os.path.exists(pathname+book_name+'.txt'):
print(book_name+'.书籍已存在,如需重新下载请删除原文件')
return None
book = etrees.xpath('//div[@class="b-oper"]/a/@href')[0]
get_mulu(book)
except Exception:
print('get_book failed')
# 获取书籍目录
def get_mulu(url):
try:
response = requests.get(url=url, headers=headers)
etrees = etree.HTML(response.text)
book = etrees.xpath('//div[@class="clearfix dirconone"]/li')
for i in book:
book = i.xpath('./a/@href')[0]
get_content(book)
except Exception:
print('get_mulu failed')
# 获取并写入书籍内容
def get_content(url):
try:
response = requests.get(url=url, headers=headers)
etrees = etree.HTML(response.content.decode("gb18030"))
title = etrees.xpath('//a[@class="article_title"]/text()')[0]
zhangjie = etrees.xpath('//strong[@class="l jieqi_title"]/text()')[0]
contents = etrees.xpath('//div[@class="mainContenr"]/text()')
content = ''.join(contents)
with open(pathname+title+'.txt','a+',encoding='utf-8') as f:
f.write(zhangjie+'\n\n'+content+'\n\n')
print('正在下载:',zhangjie)
except Exception:
print('get_content failed')
# 程序入口
if __name__ == '__main__':
url = 'http://www.quanshuwang.com/list/3_1.html'
# 创建进程池
pool = Pool()
# 启动程序
get_booklist(url)
控制台输出
正在下载: 章 节目录 第三十四章 不眠的天堂
正在下载: 章 节目录 第四十四章 :耳光
正在下载: 章 节目录 第046章 找到变异元晶
正在下载: 章节目录 第二十八章 修路优惠
正在下载: 章 节目录 第四十五章 :憋屈
正在下载: 章 节目录 第047章 至宝得手
正在下载: 章节目录 第二十九章 猜鱼
正在下载: 章 节目录 第048章 凤凰涅槃,浴火重生。
正在下载: 章节目录 第三十章 养猪场
正在下载: 章 节目录 第四十六章 :酣畅淋漓
正在下载: 章 节目录 第049章 上等天赋资质
正在下载: 章节目录 第三十一章 上鬼身
正在下载: 章 节目录 第050章 元力神兵
正在下载: 章 节目录 第四十七章 :舵主之位
正在下载: 章 节目录 第三十五章 黑暗
正在下载: 章节目录 第三十二章 吓死马有钱
正在下载: 章 节目录 第三十六章 商议
正在下载: 章 节目录 第051章 天级上品龙隐术
正在下载: 章 节目录 第三十七章 寻觅
正在下载: 章节目录 第三十三章 再遇李三
正在下载: 章节目录 第三十四章 借了一百万
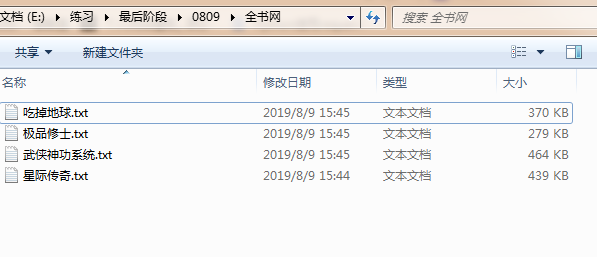
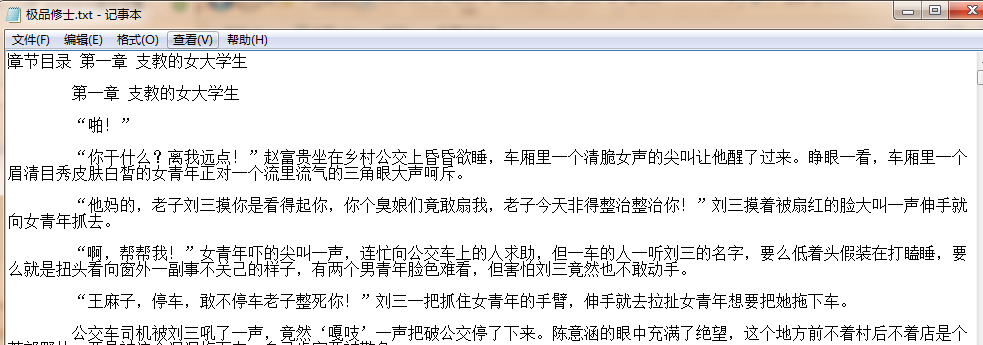
打开文件夹查看是否下载成功
done。
xpath+多进程爬取全书网纯爱耽美类别的所有小说。的更多相关文章
- xpath+多进程爬取八零电子书百合之恋分类下所有小说。
代码 # 需要的库 import requests from lxml import etree from multiprocessing import Pool import os # 请求头 he ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 使用Xpath+多进程爬取诗词名句网的史书典籍类所有文章。update~
上次写了爬取这个网站的程序,有一些地方不完善,而且爬取速度较慢,今天完善一下并开启多进程爬取,速度就像坐火箭.. # 需要的库 from lxml import etree import reques ...
- xpath+多进程爬取网易云音乐热歌榜。
用到的工具,外链转换工具 网易云网站直接打开源代码里面并没有对应的歌曲信息,需要对url做处理, 查看网站源代码路径:发现把里面的#号去掉会显示所有内容, 右键打开的源代码路径:view-source ...
- 使用scrapy框架爬取全书网书籍信息。
爬取的内容:书籍名称,作者名称,书籍简介,全书网5041页,写入mysql数据库和.txt文件 1,创建scrapy项目 scrapy startproject numberone 2,创建爬虫主程序 ...
- 利用xpath爬取招聘网的招聘信息
爬取招聘网的招聘信息: import json import random import time import pymongo import re import pandas as pd impor ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
随机推荐
- element ui + sortablejs实现表格的行列拖拽
<template> <div class="container"> <el-table :data="tableData" bo ...
- SpringBoot小技巧:Jar包换War包
SpringBoot小技巧:Jar包换War包 情景 我们都知道springBoot中已经内置了tomcat,是不需要我们额外的配置tomcat服务器的,但是有时这也可能是我们的一个瓶颈,因为如果我们 ...
- python入门和杂识
1需要理解的一些概念 1.C语言编译完就是机器码,机器码可以直接在处理器上执行. 2.CPU可以直接读取机器码. 3.Python是用C写的. 4.Python解释器会把代码内容读到内存里,通过Pyt ...
- 利用docker搭建RTMP直播流服务器实现直播
一.rtmp服务器搭建 环境: centos 7.* 1.先安装docker(省略) 2.下载docker容器 docker pull alfg/nginx-rtmp 3.运行容器(记得打开防火墙端口 ...
- B+树比B树更适合实际应用中操作系统的文件索引和数据库索引
B+树比B树更适合实际应用中操作系统的文件索引和数据库索引 为什么选择B+树作为数据库索引结构? 背景 首先,来谈谈B树.为什么要使用B树?我们需要明白以下两个事实: [事实1]不同容量的存储器, ...
- (CSDN 迁移) JAVA多线程实现-可回收缓存线程池(newCachedThreadPool)
在前两篇博客中介绍了单线程化线程池(newSingleThreadExecutor).可控最大并发数线程池(newFixedThreadPool).下面介绍的是第三种newCachedThreadPo ...
- Linux虚拟环境配置(安装python包,连接至jupyter notebook)
在Linux虚拟环境下安装python包 方法一:使用下载包 由于实验室下载速度较慢,因此采用传输下载包的形式安装包. 首先导入python包至指定文件夹(任意文件夹,记住地址即可)并解压. 进入虚拟 ...
- SQLite数据库简介和使用
一.Sqlite简介: SQLite (http://www.sqlite.org/),是一款轻型的数据库,是遵守ACID的关联式数据库管理系统,它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中 ...
- .NET Core sdk和runtime区别
SDK和runtime区别 .net core Runtime[跑netcore 程序的] (CoreCLR) .net core SDK (开发工具包 [runtime(jre) + Rolysn( ...
- spring整合mybatis报.UnsatisfiedDependencyException错误
tomcat启动报org.springframework.beans.factory.UnsatisfiedDependencyException:错误 org.springframework.bea ...