爬虫(十):AJAX、爬取AJAX数据
1. AJAX
1.1 什么是AJAX
AJAX即“Asynchronous JavaScript And XML”(异步JavaScript和XML)可以使网页实现异步更新,就是不重新加载整个网页的情况下,对网页的某部分进行更新(局部刷新)。传统的网页(不使用AJAX)如果需要更新内容,必须重载整个网页页面。
AJAX = 异步JavaScript和XML,是一种新的思想,整合之前的多种技术,用于创建快速交互式网页应用的页面开发技术。
1.2 同步和异步
同步现象:客户端发送请求到服务器端,当服务器返回响应之前,客户端都处于等待卡死状态。
异步现象:客户端发送请求到服务器端,无论服务器是否返回响应,客户端都可以随意做其他事情,不会被卡死。
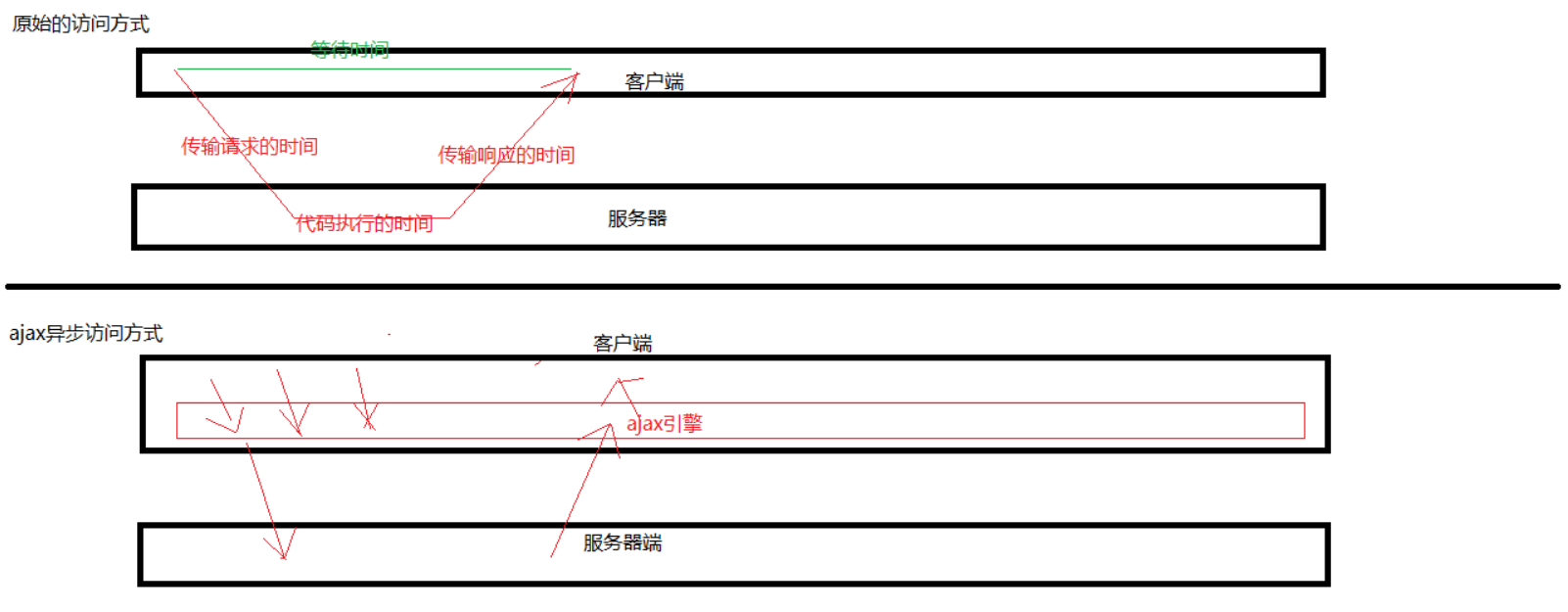
1.3 AJAX原理分析
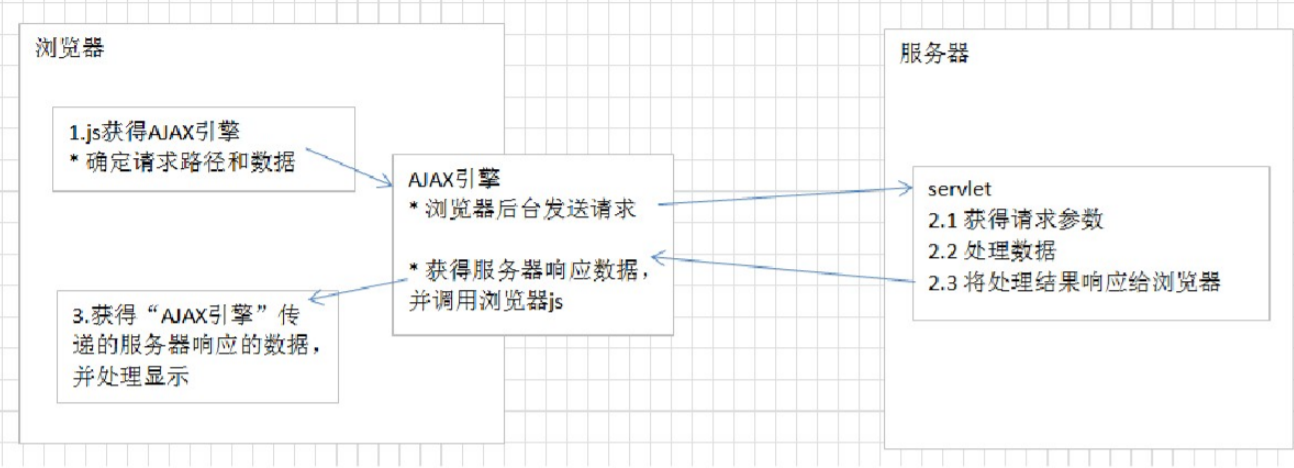
1.1使用JavaScript获得浏览器内置的AJAX引擎(XMIHttpRequest对象)
1.2通过AJAX引擎确定请求路径和请求参数
1.3通知AJAX引擎发送请求
AJAX引擎会在不刷新浏览器地址栏的情况下,发送请求
2.1服务器获得请求参数
2.2服务器处理请求参数(添加、查询等操作)
2.3服务器响应数据给浏览器
AJAX引擎获得服务器响应的数据,通过执行JavaScript的回调函数将数据传递给浏览器页面。
3.1通过设置给AJAX引擎的回调函数获得服务器响应的数据
3.2使用JavaScript在指定的位置,显示响应数据,从而局部修改页面的数据,达到局部刷新目。
2. 爬取AJAX数据
2.1 查看AJAX数据
目前很多网站都使用ajax技术动态加载数据,和常规的网站不一样,数据时动态加载的,如果我们使用常规的方法爬取网页,得到的只是一堆html代码,没有任何的数据。
import requests
from urllib.parse import urlencode url = 'http://www.baidu.com/'
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
} response = requests.get(url,headers=headers)
print(response.text)
上面的代码是爬取百度首页,并打印出get方法返回的文本内容如下图所示,只有一堆网页代码,没有任何新闻信息。


内容过多,只截取部分内容,有兴趣的朋友可以执行上面的代码看下效果。
对于使用ajax动态加载数据的网页要怎么爬取呢?我们先看下百度是如何使用ajax加载数据的。通过chrome的开发者工具来看数据加载过程。
首先打开chrome浏览器,打开开发者工具,点击Network选项,点击XHR选项,然后输入网址:https://www.baidu.com/,点击Preview选项卡,就会看到通过ajax请求返回的数据,Name那一栏就是ajax请求,当鼠标向下滑动时,就会出现多条ajax请求:
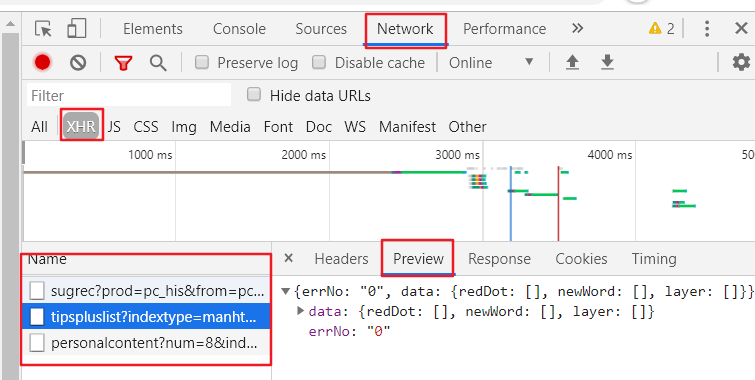

通过上图我们知道ajax请求返回的是json数据。
2.2 爬取AJAX数据
爬取AJAX有两种方式:
1.直接分析AJAX调用的接口。然后通过代码请求这个接口。
2.使用selenium+浏览器驱动模拟浏览器行为获取数据。
分析接口:
优点:直接可以请求到数据。不需要做一些解析工作。代码量少,性能高。
缺点:分析接口比较负责,特别是一些通过JS混淆的接口,要有一定的JS功底。容易被发现是爬虫。
selenium:
优点:直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到。爬虫更稳定。
缺点:代码量多。性能低。
分析接口的案例呢,就找了下大佬写的案例了。
selenium案例我会在下一章写出来的。
爬虫(十):AJAX、爬取AJAX数据的更多相关文章
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- Ajax爬取动态数据和HTTPS自动默认证书
Ajax数据爬取 在spider爬取数据的过程中,有些网页的数据是利用Ajax动态加载出来的,所以,在网页源代码中可能不会看到这一部分的数据,因此,我们需要使用另外的方式进行数据多爬取. 以豆瓣电影的 ...
- Python爬虫:如何爬取分页数据?
上一篇文章<Python爬虫:爬取人人都是产品经理的数据>中说了爬取单页数据的方法,这篇文章详细解释如何爬取多页数据. 爬取对象: 有融网理财项目列表页[履约中]状态下的前10页数据,地址 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息, ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- Python 爬虫 ajax爬取马云爸爸微博内容
ajax爬取情况 有时候我们在用 Requests 抓取页面的时候,得到的结果可能和在浏览器中看到的是不一样的,在浏览器中可以看到正常显示的页面数据,但是使用 Requests 得到的结果并没有,这其 ...
- node.js爬取ajax接口数据
爬取页面数据与爬取接口数据,我还是觉得爬取接口数据更加简单一点,主要爬取一些分页的数据. 爬取步骤: 1.明确目标接口地址,举个例子 : https://www.vcg.com/api/common/ ...
随机推荐
- <编译原理 - 函数绘图语言解释器(2)语法分析器 - python>
<编译原理 - 函数绘图语言解释器(2)语法分析器 - python> 背景 编译原理上机实现一个对函数绘图语言的解释器 - 用除C外的不同种语言实现 设计思路: 设计函数绘图语言的文法, ...
- Socket 实现简单的多线程服务器程序
**********服务器端************* public class ServerSocket{ public static void main(String[] args) throws ...
- 解决Debina系统自动更新软件包的问题
不知从何时开始,我的电脑每天开机连接上网络之后,不断的在下载数据,状态栏显示网速达到每秒1到2兆.开始我还不太在意,不过后来由于带宽全部被这种莫名其奥妙的下载占据了,我连网页都无否正常浏览了,所以我决 ...
- .net反编译原理
目录 目录 前言 ILdasm ILasm 结语 推荐文献 目录 NLog日志框架使用探究-1 NLog日志框架使用探究-2 科学使用Log4View2 前言 本来没有想写反编译相关的文章,但是写着写 ...
- 【翻译】.NET Core3.1发布
.NET Core3.1发布 我们很高兴宣布.NET Core 3.1的发布.实际上,这只是对我们两个多月前发布的.NET Core 3.0的一小部分修复和完善.最重要的是.NET Core 3.1是 ...
- [转]Xtrabackup 的 xtrabackup_binlog_pos_innodb和xtrabackup_binlog_info 文件区别
[转自] http://julyclyde.org/?p=403 在操作 innobackupex 的时候,执行 change master to 的时候发现 xtrabackup_binlog_po ...
- 如何提高 PHP 代码的质量?第二部分 单元测试
在“如何提高 PHP 代码的质量?”的前一部分中:我们设置了一些自动化工具来自动检查我们的代码.这很有帮助,但关于我们的代码如何满足业务需求并没有给我们留下任何印象.我们现在需要创建特定代码域的测试. ...
- 【w、vmstat、top、sar、nload】各个命令 使用介绍
第7周第1次课(5月7日) 课程内容: 10.1 使用w查看系统负载10.2 vmstat命令10.3 top命令10.4 sar命令10.5 nload命令 10.1 使用w查看系统负载 w命令查看 ...
- Python开发GUI工具介绍,实战:将图片转化为素描画!【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- Plugin execution not covered by lifecycle configuration: org.codehaus.mojo:build-helper-maven-plugin:1.8:add-test-source (execution: add-functional-source, phase: generate-sources)
在maven项目中使用add-source时,pom.xml报如下错误: Plugin execution not covered by lifecycle configuration: org.co ...