学好Python不加班系列之SCRAPY爬虫框架的使用
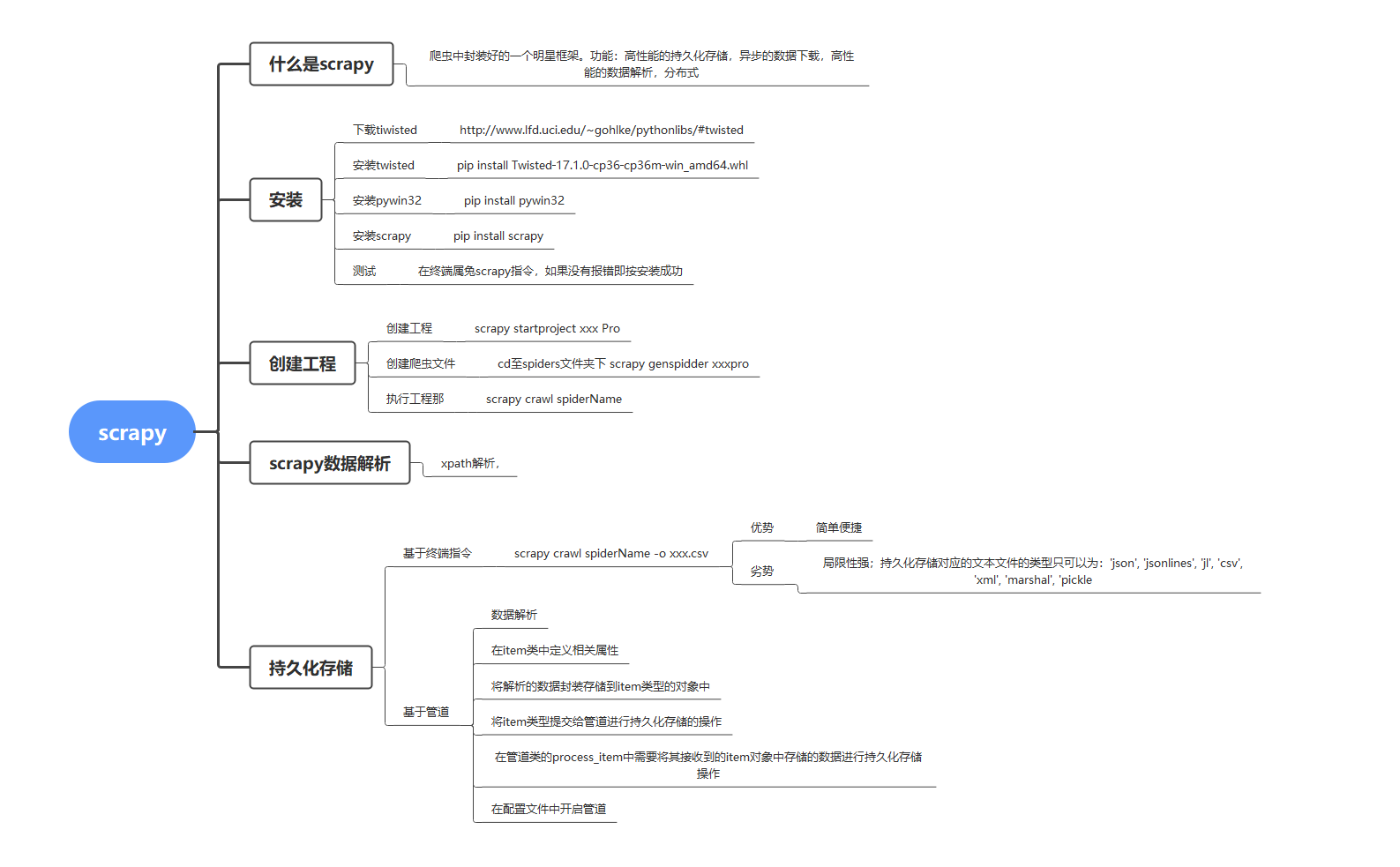
scrapy是一个爬虫中封装好的一个明星框架。具有高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
对于初学者来说还是需要有一定的基础作为铺垫的学习。我将从下方的思维导图中进行逐步的解析讲述。
实验工具即环境:
笔记本:Y9000X 2020
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
一、安装
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载好后打开终端进行安装scrapy的必要模块
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
安装scrapy:pip install scrapy
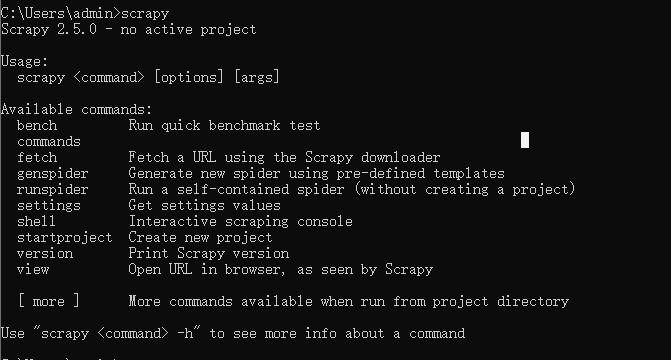
安装完成后在终端输入scrapy如果没有报错即安装成功。
二、创建scrapy的工程
在pycharm中创建好的项目中的中终端输入
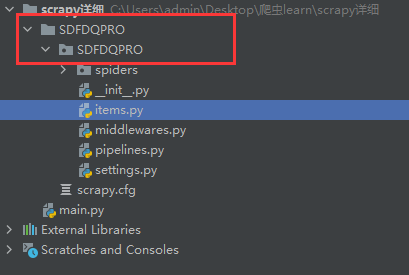
scrapy startproject SDFDQPRO

检查下项目目录即可发现多出了如下的工程目录
三、创建一个爬虫目录
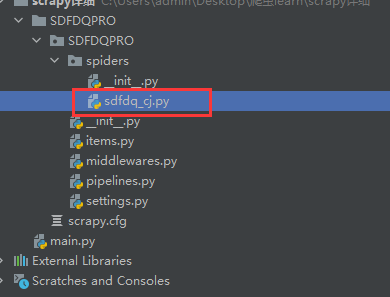
在终端找到之前所创建的工程目录,在此目录下输入scrapy genspider sdfdq_cj http://www.csrc.gov.cn/pub/shandong/
后方网站为中国证券监督管理委员会山东监管局。

运行后可发现工程目录中多出一个名为sdfdq_cj.py的爬虫文件。
进入到爬虫文件中可以看到如下代码
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
pass
接下来对网站解析选取需要获取的内容
四、数据解析
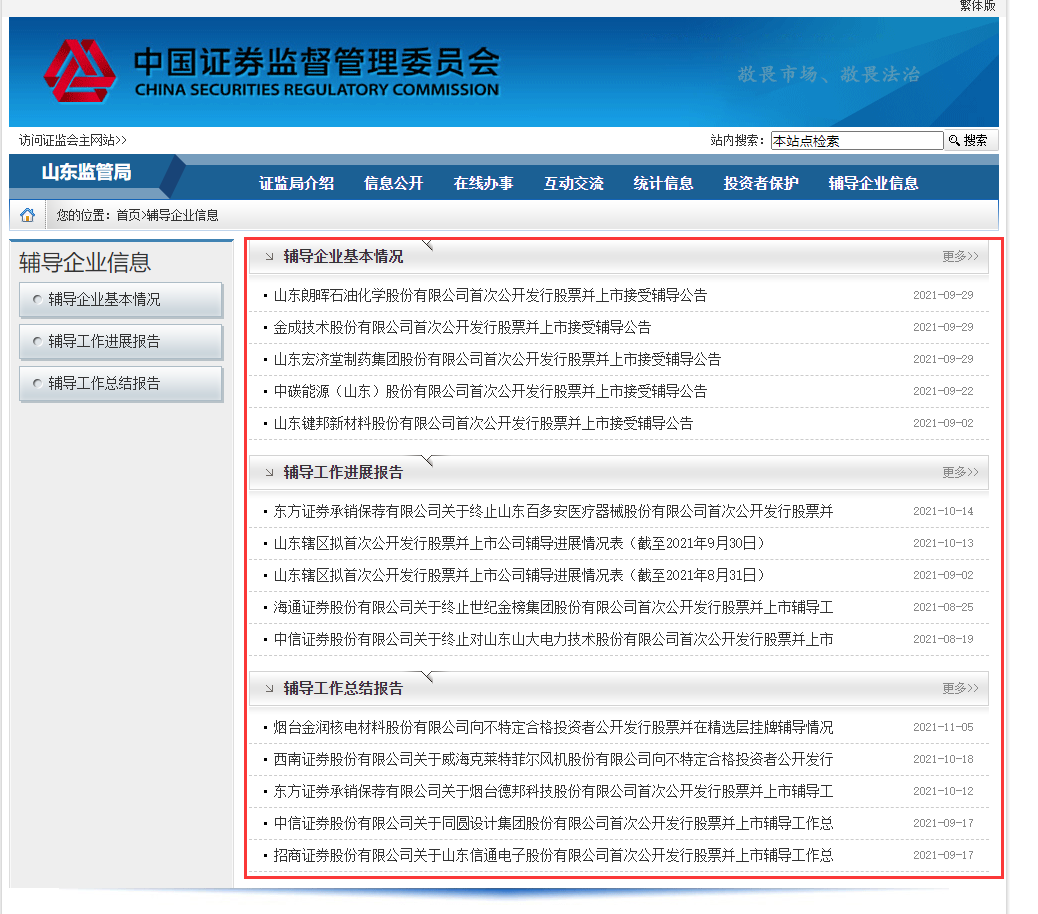
通过对网站的查看可以看出我们需要的是辅导期中的企业基本情况、工作进展报告、工作总结总的标题,日期以及链接。
scrapy对网站的解析沿用了xpath的解析方式。
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response): li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
print('title',title)
print('url',url)
print('date',date)
对网站的内容解析后运行scrapy 终端输入 scrapy crawl sdfdq_cj 注意:此语句的运行目录

可以看到我们想获取的内容:
内容获取到我们必须要将其持久化存储才有意义:
五、scrapy的持久化存储
1)基于指令的持久化存储:
要求:只可以将parse的方法返回值存储到本地的文本文件中
def parse(self, response):
# 创建一个列表接收获取的数据
all_data = []
li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
# 基于终端指令的持久化存储操作
dic = {
'title':title,
'url':url,
'date':date
}
all_data.append(dic)
return all_data
接下来在终端中输入 scrapy crawl sdfdq_cj -o ./sdfdq.csv
将获取的文本内容存储到对应路径下的sdfdq.csv文本文件中

2)基于管道的持久化存储
明天更。。。。。。。。。
学好Python不加班系列之SCRAPY爬虫框架的使用的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
随机推荐
- lua自写限制并发访问模块
注意:ngx.say跟ngx.exit是不可以共存,否则会出现ngx.exit无法正常执行 1.定义lua共享内存20m lua_shared_dict ceshi 20m; 2.再location ...
- 让selenium规避网站的检测
在使用selenium对某些网站模拟访问的时候会被检测出来,检测出来之后就有可能拿不到我们想要的数据,那么我们怎么可以规避掉呢? 在使用谷歌浏览器的时候我们右键-检查-console-输入window ...
- iOS实现XMPP通讯(一)搭建Openfire
安装Openfire Openfire官网下载地址:https://igniterealtime.org/downloads/ (也是Spark客户端的下载地址) Openfire下载并安装后,打开系 ...
- 9.亿级流量电商系统JVM模型参数预估方案
1. 需求分析 大促在即,拥有亿级流量的电商平台开发了一个订单系统,我们应该如何来预估其并发量?如何根据并发量来合理配置JVM参数呢? 假设,现在有一个场景,一个电商平台,比如京东,需要承担每天上亿的 ...
- vue3 element-plus 配置json快速生成table列表组件,提升生产力近500%(已在公司使用,持续优化中)
️本文为博客园首发文章,未获授权禁止转载 大家好,我是aehyok,一个住在深圳城市的佛系码农♀️,如果你喜欢我的文章,可以通过点赞帮我聚集灵力️. 个人github仓库地址: https:gith ...
- Java基础之(十三):类与对象
初识面向对象 面向对象 & 面向过程 面向过程思想 步骤清晰简单,第一步做什么,第二步做什么..... 面向过程适合处理一些较为简单的问题 面向对象思想 物以类聚,分类的思维模式,思考问题 ...
- CF49E Common ancestor(dp+dp+dp)
纪念卡常把自己卡死的一次自闭模拟赛 QWQ 一开始看这个题,以为是个图论,仔细一想,貌似可以直接dp啊. 首先,因为规则只有从两个变为1个,貌似可以用类似区间\(dp\)的方式来\(check\)一段 ...
- CF1082E Increasing Frequency (multiset+乱搞+贪心)
题目大意: \(给你n个数a_i,给定一个m,你可以选择一个区间[l,r],让他们区间加一个任意数,然后询问一次操作完之后,最多能得到多少个m\) QWQ 考场上真的** 想了好久都不会,直到考试快结 ...
- bzoj3262陌上花开 (CDQ,BIT)
题目大意 给定n朵花,每个花有三个属性,定义\(f[i]\)为满足\(a_j \le a_i\)且\(b_j \le b_i\)且\(c_j \le c_i\)的j的数量, 求\(d \in [0,n ...
- luogu1081 开车旅行2012 D1T3 (倍增,set,O2)
题目描述 小 A 和小 B 决定利用假期外出旅行,他们将想去的城市从 1 到 N 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 i 的海拔高度为Hi,城市 i ...