#1 爬虫:豆瓣图书TOP250 「requests、BeautifulSoup」
一、项目背景
随着时代的发展,国人对于阅读的需求也是日益增长,既然要阅读,就要读好书,什么是好书呢?本项目选择以豆瓣图书网站为对象,统计其排行榜的前250本书籍。
二、项目介绍
本项目使用Python爬虫技术统计豆瓣图书网站上排名前250的书籍信息,包括书名、作者、出版社、出版日期、价格、评星、简述信息
将获取到的信息存储在Mysql数据库中
三、项目流程
3.1 分析第一页
第一页地址为:https://book.douban.com/top250,打开后页面呈现为如下:
我们需要获得的信息为每一本书的所有信息:
所以思路为:
解析这一页--->得到这一页所有图书的信息
3.2 解析第一页
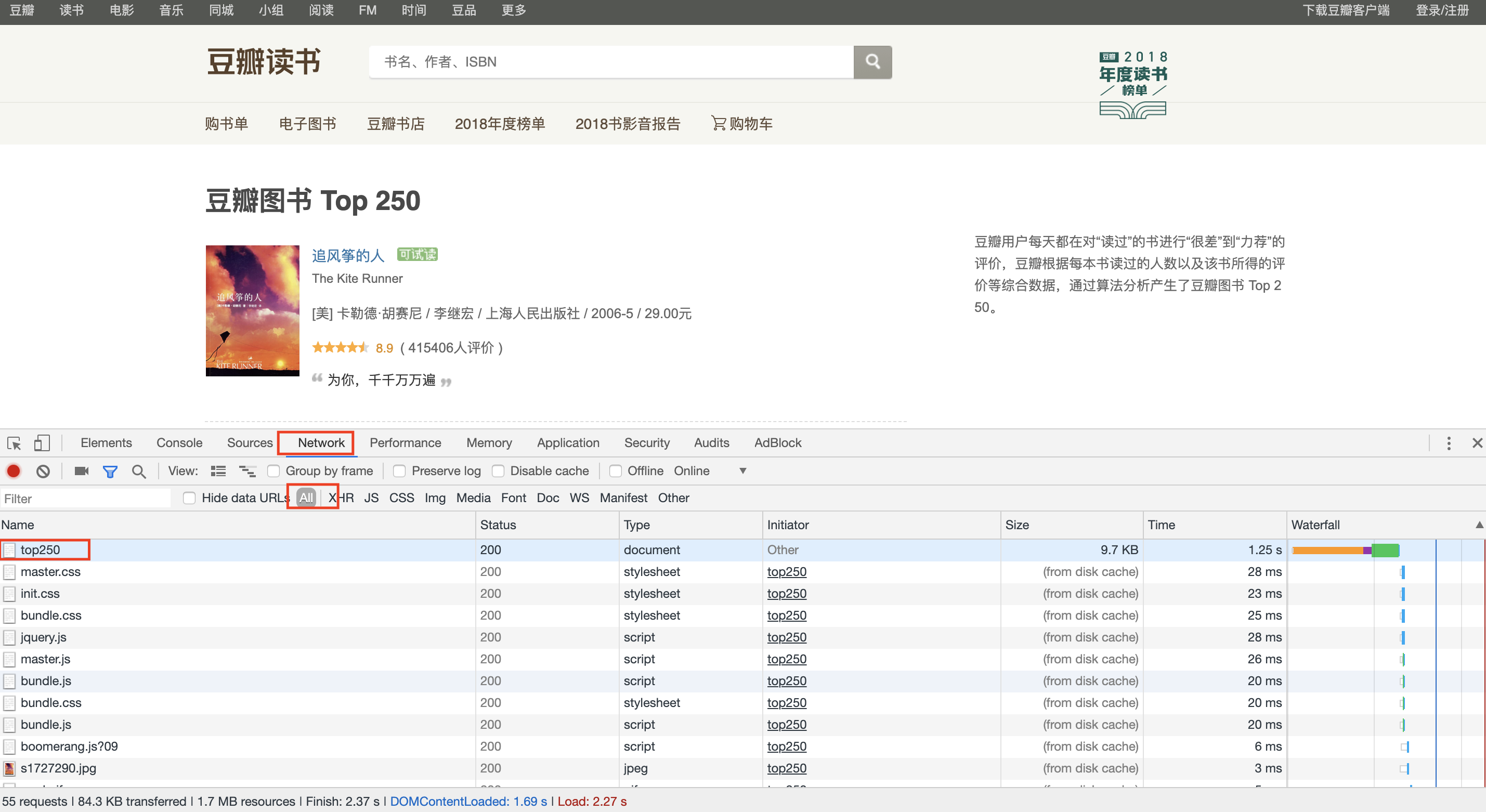
使用开发者模式查看网页源代码(Chrome浏览器按F12),选择network后,刷新网页,效果如下图:
之后点击top250--->Response,如下图:
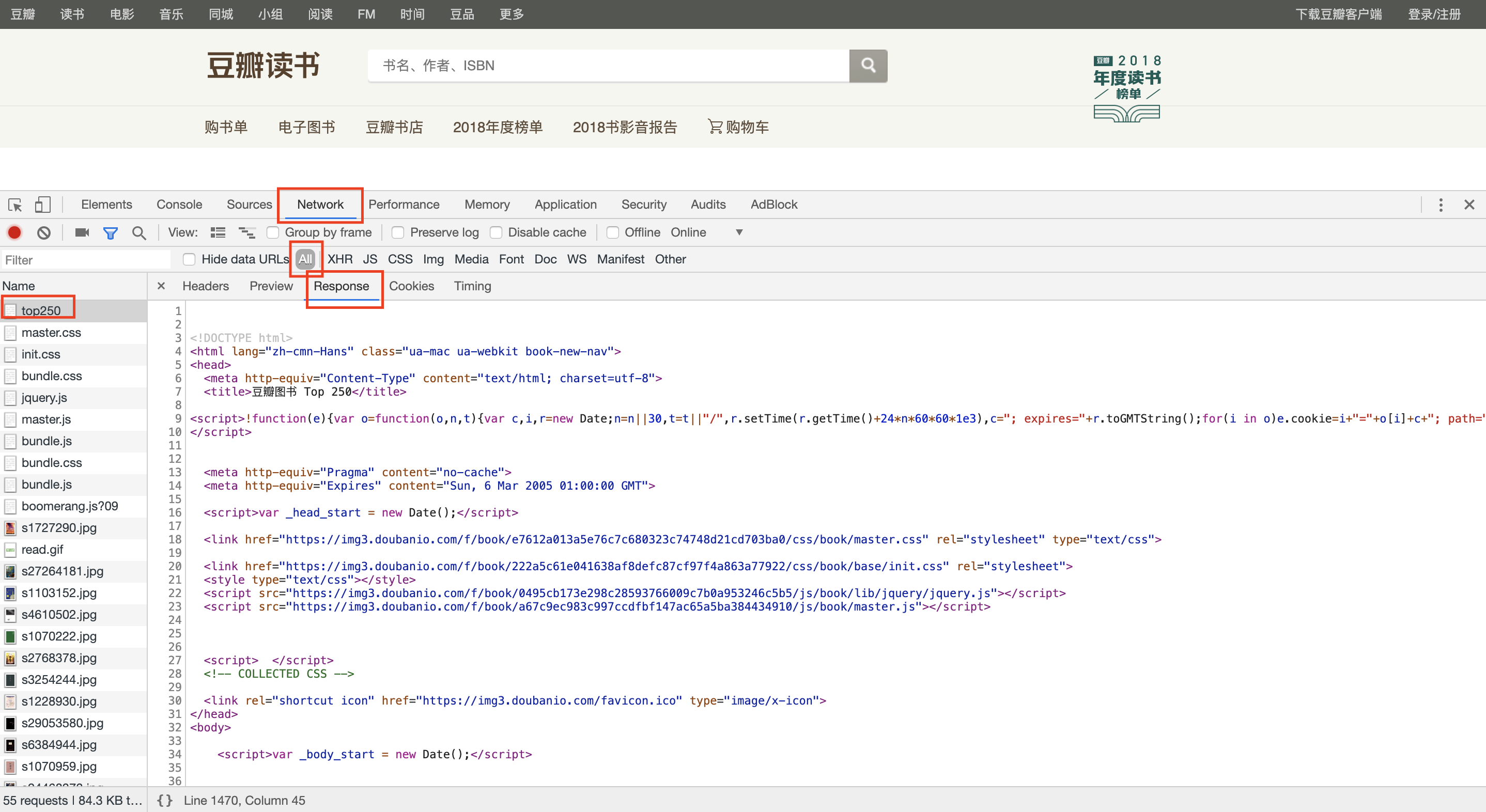
此时就会在右下方看到网页的源代码,分析源代码可知:
每一本书都是被「table标签,class=item」扩起来的,比如《追风筝的人》源代码在253-307行。
使用requests模块获取源代码,Python代码如下:
import requests def parse_index(url):
'''
解析索引页面
返回图书所有信息
'''
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except Exception as e:
print('error:', e)
『防抄袭:读者请忽略这段文字,文章作者是博客园的MinuteSheep』
3.3 解析图书详细信息
获取到页面源代码后,接下来要做的工作就是解析每一本图书的详细信息了。所以思路继续深入:
解析这一页--->得到这一页所有图书的信息--->解析一本图书--->将图书详细信息保存为字典格式
书名都是被「a标签」扩起来的,比如《追风筝的人》书名源代码在268-274行;
作者、出版社、出版日期、价格都是被「p标签,class=pl」扩起来的,比如《追风筝的人》这些信息源代码在285行;
评星都是被「span标签,class=rating_nums」扩起来的,比如《追风筝的人》评星源代码在292行;
简述信息都是被「span标签,class=inq」扩起来的,比如《追风筝的人》简述信息源代码在301行。
Python源代码如下:
from bs4 import BeautifulSoup def parse(text):
'''
解析图书详细信息
'''
soup = BeautifulSoup(text.strip(), 'lxml')
books = soup.select('.item')
info = {}
for book in books:
info.clear()
info['title'] = book.select('.pl2 a')[0].get_text(
).strip().replace(' ', '').replace('\n', '')
info['author'] = book.select(
'.pl')[0].get_text().strip().split('/')[0].strip()
info['publishers'] = book.select(
'.pl')[0].get_text().strip().split('/')[-3].strip()
info['date'] = book.select(
'.pl')[0].get_text().strip().split('/')[-2].strip()
info['price'] = book.select(
'.pl')[0].get_text().strip().split('/')[-1].strip()
info['star'] = float(book.select('.rating_nums')[0].get_text())
info['summary'] = book.select('.inq')[0].get_text(
).strip() if book.select('.inq') else ''
yield info
3.4 将信息保存在Mysql数据库
进入Mysql的交互环境,依次建立数据库、创建数据表:
create database douban;
use douban;
create table book_top250(
-> id int not null primary key auto_increment,
-> title char(100) not null unique key,
-> author char(100) not null,
-> publisher char(100),
-> date char(100),
-> price char(100)
-> star float,
-> summary char(100)
->);
之后使用Mysql官方推荐的连接库:mysql.connector
Python代码如下:
import mysql.connector def open_mysql():
'''
连接mysql
'''
cnx = mysql.connector.connect(user='minutesheep', database='douban')
cursor = cnx.cursor()
return cnx, cursor def save_to_mysql(cnx, cursor, info):
'''
将数据写入mysql
'''
add_book_top250 = ("INSERT IGNORE INTO book_top250 "
"(title,author,publishers,date,price,star,summary) "
"VALUES (%(title)s, %(author)s, %(publishers)s, %(date)s, %(price)s, %(star)s, %(summary)s)") cursor.execute(add_book_top250, info)
cnx.commit() def close_mysql(cnx, cursor):
'''
关闭mysql
'''
cursor.close()
cnx.close()
到此为止,一本图书的信息就已经保存完毕了
3.5 遍历本页面所有图书
现在只需要将本页面的所有图书遍历一遍,就完成了一个页面的抓取
『防抄袭:读者请忽略这段文字,文章作者是博客园的MinuteSheep』
3.6 遍历所有页面
最后只需要将所有页面遍历就可以抓取到250本图书了。现在观察每一页的URL变化:
第一页:https://book.douban.com/top250 或 https://book.douban.com/top250?start=0
第二页:https://book.douban.com/top250?start=25
第三页:https://book.douban.com/top250?start=50
第十页(最后一页):https://book.douban.com/top250?start=225
通过观察可知,后一页的URL只需要将前一页的URL最后的数字加25
基于此,Python代码为:
def main():
base_url = 'https://book.douban.com/top250?start='
cnx, cursor = open_mysql()
for page in range(0, 250, 25):
index_url = base_url + str(page)
text = parse_index(index_url)
info = parse(text)
for result in info:
save_to_mysql(cnx, cursor, result)
close_mysql(cnx, cursor)
四、项目流程图

五、项目源代码
import requests
from bs4 import BeautifulSoup
import mysql.connector def parse_index(url):
'''
解析索引页面
返回图书所有信息
'''
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except Exception as e:
print('error:', e) def parse(text):
'''
解析图书详细信息
'''
soup = BeautifulSoup(text.strip(), 'lxml')
books = soup.select('.item')
info = {}
for book in books:
info.clear()
info['title'] = book.select('.pl2 a')[0].get_text(
).strip().replace(' ', '').replace('\n', '')
info['author'] = book.select(
'.pl')[0].get_text().strip().split('/')[0].strip()
info['publishers'] = book.select(
'.pl')[0].get_text().strip().split('/')[-3].strip()
info['date'] = book.select(
'.pl')[0].get_text().strip().split('/')[-2].strip()
info['price'] = book.select(
'.pl')[0].get_text().strip().split('/')[-1].strip()
info['star'] = float(book.select('.rating_nums')[0].get_text())
info['summary'] = book.select('.inq')[0].get_text(
).strip() if book.select('.inq') else ''
yield info def open_mysql():
'''
连接mysql
'''
cnx = mysql.connector.connect(user='minutesheep', database='douban')
cursor = cnx.cursor()
return cnx, cursor def save_to_mysql(cnx, cursor, info):
'''
将数据写入mysql
'''
add_book_top250 = ("INSERT IGNORE INTO book_top250 "
"(title,author,publishers,date,price,star,summary) "
"VALUES (%(title)s, %(author)s, %(publishers)s, %(date)s, %(price)s, %(star)s, %(summary)s)") cursor.execute(add_book_top250, info)
cnx.commit() def close_mysql(cnx, cursor):
'''
关闭mysql
'''
cursor.close()
cnx.close() def main():
base_url = 'https://book.douban.com/top250?start='
cnx, cursor = open_mysql()
for page in range(0, 250, 25):
index_url = base_url + str(page)
text = parse_index(index_url)
info = parse(text)
for result in info:
save_to_mysql(cnx, cursor, result)
close_mysql(cnx, cursor) if __name__ == '__main__':
main()
源代码
整个项目地址:https://github.com/MinuteSheep/DoubanBookTop250
六、项目结果展示
Mysql部分数据如下图:

提醒:仅供学习使用,商用后果自负
#1 爬虫:豆瓣图书TOP250 「requests、BeautifulSoup」的更多相关文章
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- 【Python数据分析】Python3操作Excel-以豆瓣图书Top250为例
本文利用Python3爬虫抓取豆瓣图书Top250,并利用xlwt模块将其存储至excel文件,图片下载到相应目录.旨在进行更多的爬虫实践练习以及模块学习. 工具 1.Python 3.5 2.Bea ...
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
- 豆瓣图书Top250
从豆瓣图书Top250抓取数据,并通过词云图展示 导入库 from lxml import etree #解析库 import time #时间 import random #随机函数 import ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 爬虫初体验:Python+Requests+BeautifulSoup抓取广播剧
可以看到一个DIV下放一个广播剧的信息,包括名称和地址,第一步我们先收集所有广播剧的收听地址: # 用requests的get方法访问novel_list_resp = requests.get(&q ...
- 爬去豆瓣图书top250数据存储到csv中
from lxml import etree import requests import csv fp=open('C://Users/Administrator/Desktop/lianxi/do ...
随机推荐
- 七牛云音频转码准备工作之如何创建音视频处理私有队列pipeline
如何创建音视频处理私有队列 最近更新时间:2017-08-28 15:54:45 在七牛进行音视频处理,推荐使用私有队列(pipeline). 创建私有队列方法如下: 第一步 登录七牛开发者平台 ht ...
- 如何把if-else代码重构成高质量代码
原文:https://blog.csdn.net/qq_35440678/article/details/77939999 本文提纲: 为什么我们写的代码都是if-else? 这样的代码有什么缺点? ...
- centos7 ping不通 name or service not known
最近打算为centos安装一个界面时,发现不能上网.ping www.baidu.com 报name or service not known. 原来网络配置没设好. 一.选择VMWare的NAT模式 ...
- [Lyft Level 5 Challenge 2018 - Elimination Round][Codeforces 1033D. Divisors]
题目链接:1033D - Divisors 题目大意:给定\(n\)个数\(a_i\),每个数的约数个数为3到5个,求\(\prod_{i=1}^{n}a_i\)的约数个数.其中\(1 \leq n ...
- Meltdown Attack
1. 引言 2018年1月3日,Google Project Zero(GPZ)团队安全研究员Jann Horn在其团队博客中爆出CPU芯片的两组漏洞,分别是Meltdown与Spectre. Mel ...
- Ajax级联选择框
Ajax级联选择框 级联选择框常用与比较负责的网页开发,例如实现的商品添加页面中,需要选择商品的分类,而分类信息又有层次,例如大分类和小分类就是两层级联,在用户选择商品所属大类时,所属小类的内容需要根 ...
- ubuntu 修改系统时间无效
用root用户修改服务器时间无效:使用hwclock -w也不行 解决方法: 需要取消自动从互联网同步时间才可以的 timedatectl set-ntp 0 上面的命令可以关闭自动同步,然后你再设置 ...
- live555工程建立与调试
Live555是一款开源的RTSP服务器,下载地址http://www.live555.com/liveMedia/public/ 下载下来的代码只有源文件,没有工程文件.那么如何使用VS 调试liv ...
- MongoDB 错误汇总
错误1. ERROR: child process failed, exited with error number 100 可能原因: 1.没有正确关闭服务 2.服务已经启动 3.conf文件的参数 ...
- 浏览器本地数据库 IndexedDB 基础详解
一.概述 随着浏览器的功能不断增强,越来越多的网站开始考虑,将大量数据储存在客户端,这样可以减少从服务器获取数据,直接从本地获取数据. 现有的浏览器数据储存方案,都不适合储存大量数据:Cookie 的 ...