scrapy基础
scrapy
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
安装
- Linux:
pip install scrapy
- Windows:
1. pip install wheel
2. 下载twisted
http://www.lfd.uci.edu/-gohlke/pythonlibs/#twisted
3. 安装twisted
进入到下载目录,pip install Twisted-xxx.whl
4. pip install pywin32
5. pip install scrapy
Scrapy结构,执行流程
架构图
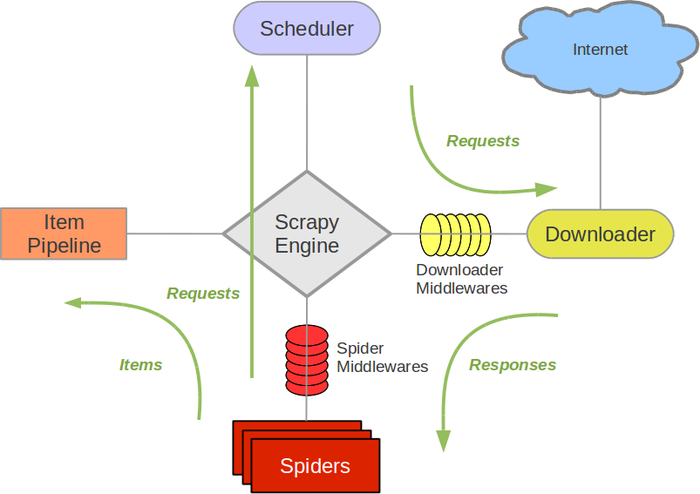
各部分作用
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
执行流程图
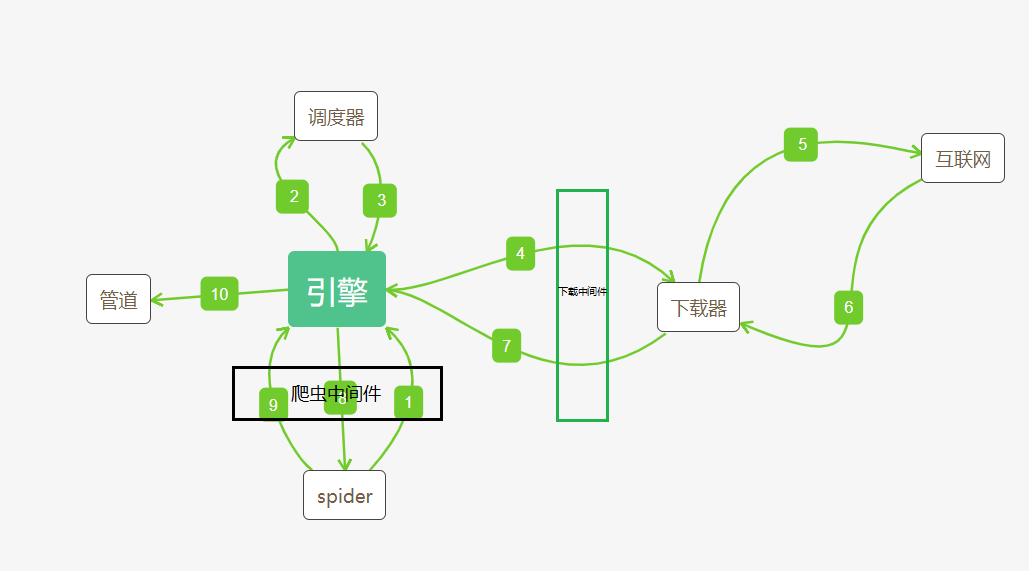
起始url被封装成request请求对象,经引擎传给调度器,存放在队列中且会对重复的请求对象进行过滤,之后经引擎传递给下载器去下载数据得到响应对象,响应对象经引擎返回给spider进行解析并封装到item对象中,用yield将item对象经引擎传给管道进行持久化处理,若spider中解析到新的url,重复上述操作。
请求传参
当爬取的数据不在同一页面中时,要进行请求传参,不然持久化的数据结果会出错。
- 使用meta进行传参,如下:
def parse(self, response):
...
yield scrapy.Request(url, callback=self.detail, meta={"item": item})
def detail(self, response):
item = response.meta['item']
...
如何提高scrapy爬取效率
- 增大并发数
默认情况下scrapy没有开启线程并发,需在settings.py中手动开启。CONCURRENT_REQUESTS=32,但是并不是只能设置不超过32,可以适度增加并发数。 - 降低日志等级
减少日志信息的输出会降低CPU的使用率。
如:LOG_LEVEL = 'INFO'
LOG_FILE = 'path' 将日志输出到指定文件中 - 禁用cookie
除非真的需要cookie,否则请关闭以提升爬取效率。
COOKIES_ENABLED = False - 限制重试
重新请求爬取失败的url会减慢爬取速度。
RETRY_ENABLED= False - 缩减下载超时
放弃请求响应慢的url,可以提高爬取效率。
DOWNLOAD_TIMEOUT = 10 (单位是秒)
如何设置代理池和UA池
ua_list = [
]
ip_list = [
]
# 在下载中间件中
import random
def process_request(self, request, spider):
request.meta['proxy'] = random.choice(ip_list)
request.headers['User-Agent'] = random.choice(ua_list)
...
使用管道进行持久化存储的流程
- 在items中定义字段
- 获取解析后的数据值
- 将解析后的数据值存储到item对象中
- 通过yield将item对象提交到管道
- 管道中持久化存储代码的编写
- settings.py中开启管道, 并设置优先级
在scrapy中使用selenium
- 在spider的__init__方法中实现浏览器
- 在spider的closed方法中关闭浏览器
- 在下载中间件的响应中使用spider.browser获取浏览器对象,并得到需要的网页源码,实例化一个新的响应对象,之后将浏览器获取的页面源码加载到该对象中,返回这个新的响应对象。
# spider.py
def __init__(self):
self.browser = webdriver.Firefox()
def closed(self,spider):
print("spider closed")
self.browser.close()
# middlewares.py
def process_request(self, request, spider):
if spider.name == 'xxx':
try:
spider.browser.get(request.url)
spider.browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
except TimeoutException as e:
print('超时')
spider.browser.execute_script('window.stop()')
time.sleep(2)
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source,
encoding="utf-8", request=request)
其他知识点
- scrapy为什么要把持久化操作放到管道中, 而不是在爬虫文件中?
- 放到管道中进行持久化操作的效率会更高
- spider参数是干嘛用的?
- 用来传递除了item对象之外的其他属性等
- 管道文件中return item的作用?
- 为了让优先级低于本管道类的能拿到item对象
- 在scrapy框架中不需要考虑cookie
- 原始的scrapy为啥不能进行分布式爬虫?
- 原生scrapy的调度器、管道不能共享。
scrapy基础的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- scrapy 基础
安装略过 创建一个项目 scrapy startproject MySpider #或者创建时存储日志scrapy startproject --logfile='../logf.log' MySpi ...
- Scrapy基础(十三)————ItemLoader的简单使用
ItemLoader的简单使用:目的是解决在爬虫文件中代码结构杂乱,无序,可读性差的缺点 经过之前的基础,我们可以爬取一些不用登录,没有Ajax的,等等其他的简单的爬虫回顾我们的代码,是不是有点冗长, ...
- Scrapy基础(一) ------学习Scrapy之前所要了解的
技术选型: Scrapy vs requsts+beautifulsoup 1,reqests,beautifulsoup都是库,Scrapy是框架 2,Scrapy中可以加入reques ...
- scrapy基础教程
1. 安装Scrapy包 pip install scrapy, 安装教程 Mac下可能会出现:OSError: [Errno 13] Permission denied: '/Library/Pyt ...
- python scrapy 基础
scrapy是用python写的一个库,使用它可以方便的抓取网页. 主页地址http://scrapy.org/ 文档 http://doc.scrapy.org/en/latest/index.ht ...
- Scrapy基础(十四)————Scrapy实现知乎模拟登陆
模拟登陆大体思路见此博文,本篇文章只是将登陆在scrapy中实现而已 之前介绍过通过requests的session 会话模拟登陆:必须是session,涉及到验证码和xsrf的写入cookie验证的 ...
- 【Python】Scrapy基础
一.Scrapy 架构 Engine(引擎):负责 Spider(爬虫).Item Pipeline(管道).Downloader(下载器).Scheduler(调度器)中的通讯和数据传递. Sche ...
- scrapy基础二
应对反爬虫机制 ①.禁止cookie :有的网站会通过用户的cookie信息对用户进行识别和分析,此时可以通过禁用本地cookies信息让对方网站无法识别我们的会话信息 settings.py里开启禁 ...
随机推荐
- UC 优视发布“UC+”开放平台
7月5日消息,以浏览器起家的UC优视今天在2013移动互联网创新大会上正式发布“UC+”开放平台战略. UC优视公司总裁何小鹏同时表示:通过“UC+”开放平台,UC将UC浏览器全球四亿用户与移动端巨大 ...
- 封装网络请求并在wxml调用
https://blog.csdn.net/qq_35713752/article/details/78109084 // url:网络请求的url method:网络请求方式 data:请求参数 m ...
- Navicat for mysql 导出导入的问题
问题现象 1:使用navicat 导出5.6.20版本数据库,然后导入到5.7.19mysql出现错误:
- Linux入门-8 Linux系统启动详解
系统启动流程 BIOS MBR GRUB KERNEL INIT 单用户修改root密码 GRUB加密 系统启动流程 BIOS MBR: Boot Code 执行引导程序 - GRUB 加载内核 执行 ...
- 企业级Nginx增加日志选项
日志介绍 目的:将用户的访问信息记录到指定的文件中由ngx_http_log_module模块负责 访问日志参数: access_log:指定日志文件的路径和使用何种日志格式记录日志 log_form ...
- Analysis of Algorithms
算法分析 Introduction 有各种原因要求我们分析算法,像预测算法性能,比较不同算法优劣等,其中很实际的一条原因是为了避免性能错误,要对自己算法的性能有个概念. 科学方法(scientific ...
- c++计算器后续(4)
自娱自乐: 大概是终于做到没做完的部分了,第三步助教学长的评论还没去改,感觉那个把读取文件放到Scan里面比较麻烦,其他大概还好.以上. 文件读写: 先是原来的残留问题,都是和fstream :: o ...
- 001Java输入、eclipse快捷键
内容:Java实现键盘输入,eclipse常用快捷键 ######################################################################### ...
- java基础易混点
1.进制转换由低到高:byte<short(char)<int<long<float<double 2.java八种基本数据类型(存在栈里): 整数类型 byte,s ...
- (转)Win10下PostgreSQL10与PostGIS安装
版权声明:本文为博主原创文章,欢迎转载. https://blog.csdn.net/LWJ285149763/article/details/79380643 最近在使用矢量数据,因此需要用空间数据 ...