Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据、文本、图像。 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法。这个过程被叫做向量化。把任意格式的数据 转换成具有良好特性的向量形式。
分类特征
比如房屋数据: 房价、面积、地点信息。
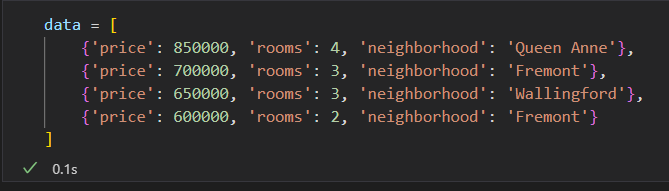
方案1:把分类特征用映射关系 编码成 整数 。
{'Queen Anne': 1, 'Fremont': 2, 'Wallingford': 3};
在scikit-learn中并不好,数值特征可以反映代数量。会产生 1<2<3的
方案2:使用独热编码
有效增加额外的类,让0和1 出现在对应的列分别表示 每个分类值 的有 或 无。
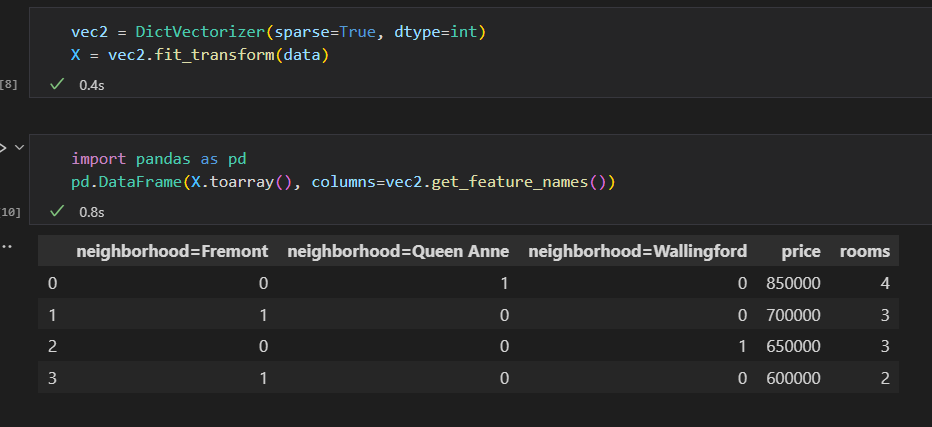
使用scikit-learn的DictVectorizer类就可以实现。
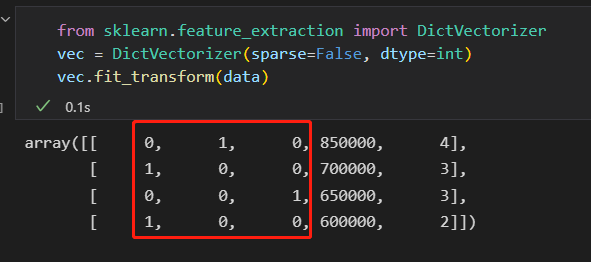
neighborhood字段转换成三列表示三个地点标签。 每一行中用1所在的列对应一个地点。
当这些分类特征编码之后,就可以和之前一样拟合 Scikit-Learn模型了
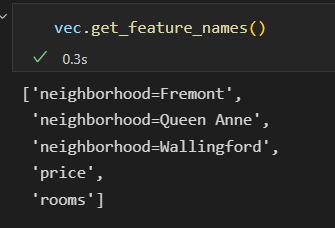
如果要看每一列的含义,使用get_feature_names()
缺陷:分类特征有许多枚举值,维度就会急剧增加。 由于被编码的数据中有许多0,因此用稀疏矩阵 会非常高效
文本特征
将文本转换成一组数值, 最简单的编码方法之一就是 单词统计
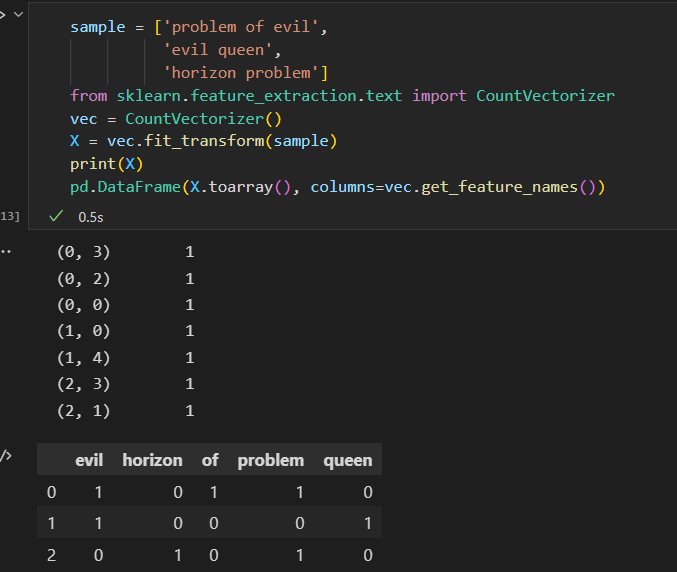
这样统计有一些问题,就是常用词聚集太高的权重,不合理。
解决方案:使用TF-IDF term requency-inverse document frequency 词频逆文档评率。 通过单词在文档中出现的评率来衡量器权重。
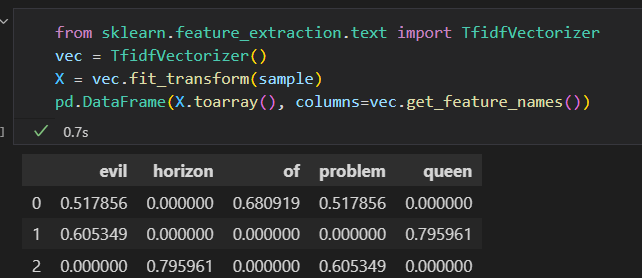
图像特征
对图像进行编码,最简单的就是:用像素表示图像。 后面详细介绍。 Scikit-Learn Scikit-Image
衍生特征
输入特征进过数学变换 衍生出来的新特征。 通过改变输入数据。 这种处理方式 又被称为 基函数回归。
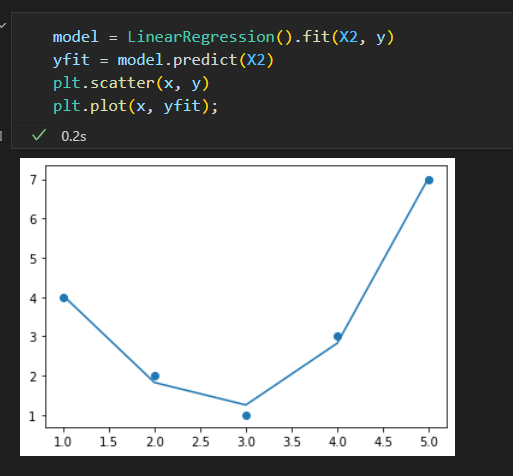
不能用直线拟合的数据
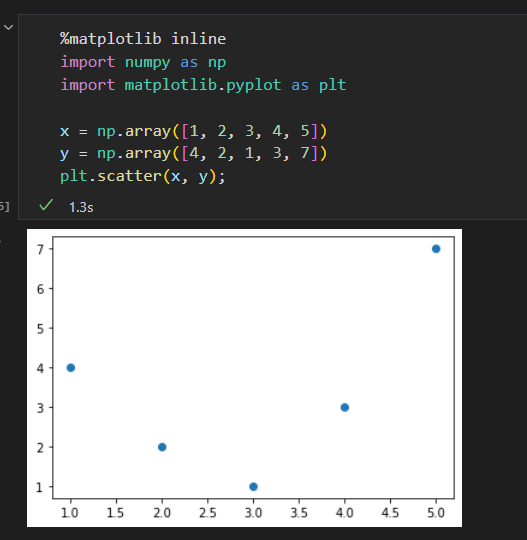
如果按照直线拟合取得最优解如下
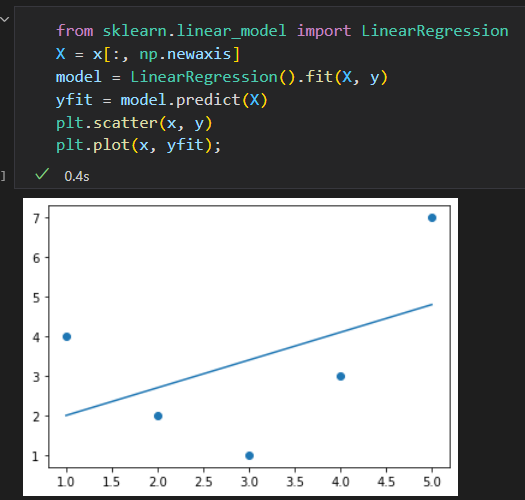
我们需要一个更复杂的模型来描述 x 与 y的关系,可以对数据进行变换,蹦增加额外的特征来提升模型 的复杂度。
比如:增加多项式特征。
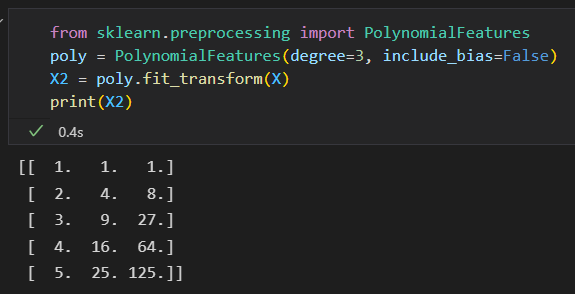
第一列表示x,
第二列表示x^2
第三列表示x^3
重新拟合。
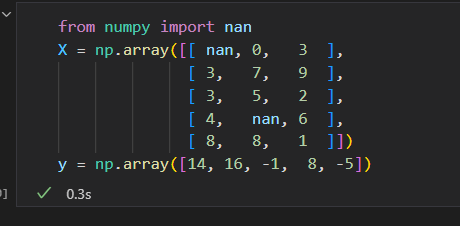
缺失值填充
原始数据如下
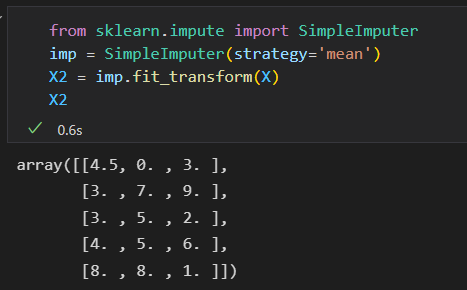
首先需要适当的值替换这些缺失数据。
方案1: 用列均值替换缺失值,中位数、众数。 SciKit-Learn 有Imputer类可以实现。
方案2:用矩阵填充或其他模型来处理缺失值,复杂。
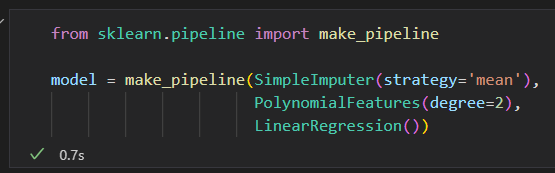
特征管道
如果经常需要手动应用以上任意一种方法,你就会感到厌倦。尤其是多个步骤串起来使用。
1)用均值填充缺失值
2)将衍生特征转换为二次方
3)拟合线性回归模型
SciKit提供了一个管道对象。
Python数据科学手册-机器学习之特征工程的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
随机推荐
- shell 同时执行多任务下载视频
本文为博主原创,转载请注明出处: shell 脚本不支持多线程,但我们需要用shell 脚本同时跑多个任务时怎么让这些任务并发同时进行,可以采用在每个任务 后面 添加一个 & ,让其在后台运 ...
- NC224938 加减
NC224938 加减 题目 题目描述 小红拿到了一个长度为 \(n\) 的数组.她每次操作可以让某个数加 \(1\) 或者某个数减 \(1\) . 小红最多能进行 \(k\) 次操作.她希望操作结束 ...
- string的底层实现
String底层实现 string在C++也是一个重要的知识,但是想要用好它,就要知道它的底层是如何写的,才能更好的用好这个string,那么这次就来实现string的底层,但是string的接口功能 ...
- Oracle查看所有用户及其权限
Oracle查看所有用户及其权限:Oracle数据字典视图的种类分别为:USER,ALL 和 DBA. USER_*:有关用户所拥有的对象信息,即用户自己创建的对象信息 ALL_*:有关用户可以访问的 ...
- JDBC: ThreadLocal 类
1.ThreadLocal ThreadLocal用于保存某个线程共享变量.在Java中,每个线程对象都有一个ThreadLocal<ThreadLocal,Object>,其中key就是 ...
- APISpace 成语大全API接口 免费好用
成语有一个很大一部分是从古代相承沿用下来的,在用词方面往往不同于现代汉语,它代表一个故事或者典故.成语又是一种现成的话,跟习用语.谚语相近,但是也略有区别.成语是中华文化中的一颗璀璨的明珠. 成语 ...
- 注解_概念和注解_JDK内置注解
注解: 概念:说明程序的,给计算机看的 注解:用文字描述程序的,给程序员看的 定义:注解(Annotation),也叫元数据.一种代码级别的说明.他是JDK1.5及以后的版本引入的一个特性,与类,接口 ...
- python--函数--参数传入分类
1. 位置参数 调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致. 2. 关键字参数 好处:不用记住形参位置. 所谓关键字就是"键-值"绑定,调用函数时,进行传递. 特 ...
- odoo 14 python 单元测试步骤
# odoo 14 python 单元测试步骤 # 一.在模块根目录创建tests目录 # 二.在tests目录下创建__init__.py文件 # 三.继承TransactionCase(Singl ...
- MySQL之JDBC编程增删改查
MySQL之JDBC 一.JDBC是什么 Java DatabaseConnectivity (java语言连接数据库) 二.JDBC的本质 JDBC是SUN公司制定的一套接口(interface). ...