Transformer —— attention is all you need
https://www.cnblogs.com/rucwxb/p/10277217.html
Transformer —— attention is all you need
Transformer模型是2018年5月提出的,可以替代传统RNN和CNN的一种新的架构,用来实现机器翻译,论文名称是attention is all you need。无论是RNN还是CNN,在处理NLP任务时都有缺陷。CNN是其先天的卷积操作不很适合序列化的文本,RNN是其没有并行化,很容易超出内存限制(比如50tokens长度的句子就会占据很大的内存)。
下面左图是transformer模型一个结构,分成左边Nx框框的encoder和右边Nx框框的decoder,相较于RNN+attention常见的encoder-decoder之间的attention(上边的一个橙色框),还多出encoder和decoder内部的self-attention(下边的两个橙色框)。每个attention都有multi-head特征。最后,通过position encoding加入没考虑过的位置信息。 下面从multi-head attention,self-attention, position encoding几个角度介绍。
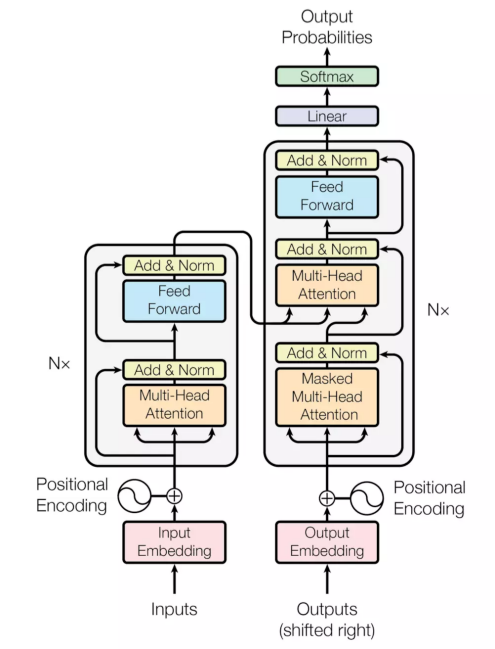
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如上面右图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。。。
position encoding:
因为transformer既没有RNN的recurrence也没有CNN的convolution,但序列顺序信息很重要,比如你欠我100万明天要还和我欠你100万明天要还的含义截然不同。。。 transformer计算token的位置信息这里使用正弦波↓,类似模拟信号传播周期性变化。这样的循环函数可以一定程度上增加模型的泛化能力。
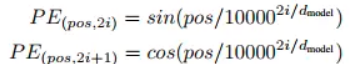
但BERT直接训练一个position embedding来保留位置信息,每个位置随机初始化一个向量,加入模型训练,最后就得到一个包含位置信息的embedding(简单粗暴。。),最后这个position embedding和word embedding的结合方式上,BERT选择直接拼接。
Transformer —— attention is all you need的更多相关文章
- Attention & Transformer
Attention & Transformer seq2seq; attention; self-attention; transformer; 1 注意力机制在NLP上的发展 Seq2Seq ...
- Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762 Motivation: The inherently sequential nature of ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- (转)How Transformers Work --- The Neural Network used by Open AI and DeepMind
How Transformers Work --- The Neural Network used by Open AI and DeepMind Original English Version l ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 【NLP】彻底搞懂BERT
# 好久没更新博客了,有时候随手在本上写写,或者Evernote上记记,零零散散的笔记带来零零散散的记忆o(╥﹏╥)o..还是整理到博客上比较有整体性,也方便查阅~ 自google在2018年10月底 ...
- CVPR2020|3D-VID:基于LiDar Video信息的3D目标检测框架
作者:蒋天园 Date:2020-04-18 来源:3D-VID:基于LiDar Video信息的3D目标检测框架|CVPR2020 Brief paper地址:https://arxiv.org/p ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
- Deformable 可变形的DETR
Deformable 可变形的DETR This repository is an official implementation of the paper Deformable DETR: Defo ...
随机推荐
- jdoj 2171: Grape
jdoj 2171: Grape 题意 题目大意 一个农场的葡萄架上挂着n串葡萄,若取一个葡萄就会获得与其相应的美味值.对于连续的k串葡萄,最多取b串,最少取a串, 问能够获得的最大美味值为多少 数据 ...
- df 查看磁盘使用情况
1.查看磁盘使用情况 2.查看boot目录详情 3.提取已使用的百分比 4.切割提取出数字
- idea之前的版本
https://www.jetbrains.com/idea/download/previous.html
- 10.python3实用编程技巧进阶(五)
5.1.如何派生内置不可变类型并修其改实例化行为 修改实例化行为 # 5.1.如何派生内置不可变类型并修其改实例化行为 #继承内置tuple, 并实现__new__,在其中修改实例化行为 class ...
- 【CF280D】k-Maximum Subsequence Sum(大码量多细节线段树)
点此看题面 大致题意: 给你一个序列,让你支持单点修改以及询问给定区间内选出至多\(k\)个不相交子区间和的最大值. 题意转换 这道题看似很不可做,实际上可以通过一个简单转换让其变可做. 考虑每次选出 ...
- A1047 Student List for Course (25 分)
一.技术总结 首先题目要看清湖,提出的条件很关键,比如for循环的终止条件,特别注意. 还有这个题目主要考虑到vector的使用,还有注意一定要加上using namespace std; 输出格式, ...
- 【目录】洛谷|CODEVS题解汇总
[动规]爱与愁的心痛 [动规]编辑距离 [动规]采药 [动规]创意吃鱼法 [动规]过河卒 [动规]开心的金明 [动规]旅行 [动规]骑士游历 [动规]数字三角形 [动规]最长连号 [动规]装箱问题 [ ...
- iOS应用卡顿分析
1.屏幕显示图像的原理 显示器按照从上到下的方式,一行行扫描,扫描完成后显示器就呈现一帧画面,随后电子枪回到初始位置继续下一次扫描.为了把显示器的显示过程和系统的视频控制器进行同步,显示器(或者其他硬 ...
- es6中reduce()方法和reduceRight()方法
es6中reduce()方法从左往右开始 参数:prev:它是上一次调用回调时返回的结果,每次调用的结果都会给prev cur:当前的元素 index:当前的索引 arr:循环的数组 返回值:函数累计 ...
- Linux 网络通信 API详解【转载】
TCP/IP分层模型 OSI协议参考模型,它是基于国际标准化组织(ISO)的建议发展起来的, 它分为7个层次:应用层.表示层.会话层.传输层.网络层.数据链路层及物理层. 这个7层的协议模型虽然规定得 ...