使用 reshape2 重塑数据框
我们已经学习了如何筛选、排序、合并和汇总数据框。这些操作只适用于行和列,然
而有时候我们需要做一些更复杂的事情。
例如,下面这段代码读取了一个数据集,包含了两种产品不同日期的质量和耐久性的
测试结果:
toy_tests <- read_ _csv("data/product-toy-tests.csv")
toy_tests
## id date sample quality durability
## 1 T01 20160201 100 9 9
## 2 T01 20160302 150 10 9
## 3 T01 20160405 180 9 10
## 4 T01 20160502 140 9 9
## 5 T02 20160201 70 7 9
## 6 T02 20160303 75 8 8
## 7 T02 20160403 90 9 8
## 8 T02 20160502 85 10 9
上述数据框的每一行都表示一个特定产品(id)在一个特定日期(date)的测试记录。
如果需要同时比较两种产品的质量和耐久性,这种数据格式可能比较麻烦。相反,如果将
数据转换为下面这样,就可以很方便地比较两种产品的值:
date T01 T02
20160201 9 9
20160301 10 9
reshape2 扩展包就是用来完成这种转换的。若还没有安装,请运行以下命令:
install.packages("reshape2")
一旦安装成功,就可以使用 reshape2::dcast( ) 来转换数据,以便于比较相同日
期不同产品的质量(quality)。更确切地说,它重塑了 toy_test 使得 date 列被共享,id 的
值被分割成列,每个 date 和 id 下的值都是 quality 数据:
library(reshape2)
toy_quality <- dcast(toy_tests, date ~ id, value.var = "quality")
toy_quality
## date T01 T02
## 1 20160201 9 7
## 2 20160302 10 NA
## 3 20160303 NA 8
## 4 20160403 NA 9
## 5 20160405 9 NA
## 6 20160502 9 10
如你所见,toy_tests 立即被转换了。两种产品的 quality 值都以 date 对齐。尽
管两种产品每个月都要进行一次测试,它们的日期却不一定会完全匹配。如果一种产品在
某一天有值,另一个产品在同一天没有对应值,结果就会产生缺失值。
一种填补缺失值的方法称为末次观测值结转法(Last Observation Carried Forward,
LOCF),当非缺失值后面紧跟着一个缺失值时,就用该非缺失值填补后面的缺失值,直到
所有的缺失值都被填补完成。zoo 包提供了 LOCF 的一个实现。如果你还没有安装这个包,
请运行以下代码安装:
install.packages("zoo")
为了演示它的工作方式,我们在一个非常简单的带缺失值的数值向量上调用 zoo::
na.locf( ):
zoo::na.locf(c(1, 2, NA, NA, 3, 1, NA, 2, NA))
## [1] 1 2 2 2 3 1 1 2 2
显然,所有的缺失值都被它前面的非缺失值替换了。为了对 toy_quality 的 T01
和 T02 两列进行相同的处理,我们可以将处理后的向量分别赋值到对应列中:
toy_quality$T01 <- zoo::na.locf(toy_quality$T01)
toy_quality$T02 <- zoo::na.locf(toy_quality$T02)
然而,如果 toy_tests 包含了成百上千种产品,我们也相应地写出上千行代码来完
成类似工作的话,就有点荒唐了。一个更好的做法是使用子分配:
toy_quality[-1] <- lapply(toy_quality[-1], zoo::na.locf)
toy_quality
## date T01 T02
## 1 20160201 9 7
## 2 20160302 10 7
## 3 20160303 10 8
## 4 20160403 10 9
## 5 20160405 9 9
## 6 20160502 9 10
我们使用 lapply( ) 对 toy_quality 中除了 date 外的所有列都进行了 LOCF 处
理,并将结果赋值给对应的列。这里,数据框的子分配可以接收列表输入,返回结果也保
留了数据框的类。
但是,虽然数据中没有包含任何缺失值,每一行的含义却发生了变化。原始数据中产
品 T01 在 20160303 这天并没有测试。所以这一天的值应该被解释为在此之前的最后一次
quality 的测试值。另一个缺点是原始数据中,两种产品都是按月测试的,但是重塑后的
数据框并没有以固定频率对齐 date。
这里有一种修正方法,就是使用年-月数据而不是一个确定的日期。在接下来的代码中,
我们会创造一个新列 ym,也就是 toy_tests 的日期值中的前 6 个字符。例如,
substr (20160101, 1, 6) 将会返回 201601:
toy_tests$ym <- substr(toy_tests$date, 1, 6)
toy_tests
## id date sample quality durability ym
## 1 T01 20160201 100 9 9 201602
## 2 T01 20160302 150 10 9 201603
## 3 T01 20160405 180 9 10 201604
## 4 T01 20160502 140 9 9 201605
## 5 T02 20160201 70 7 9 201602
## 6 T02 20160303 75 8 8 201603
## 7 T02 20160403 90 9 8 201604
## 8 T02 20160502 85 10 9 201605
这次,我们按 ym 列对齐,而不是 date:
toy_quality <- dcast(toy_tests, ym ~ id,
value.var = "quality")
toy_quality
## ym T01 T02
## 1 201602 9 7
## 2 201603 10 8
## 3 201604 9 9
## 4 201605 9 10
现在,缺失值消失了,并且两种产品每月的质量得分都被自然地表示出来了。
有时候,我们需要将许多列合并为一列,用于表示被测量的对象,另一列则存储对应
的值。例如,以下代码使用 reshape2::melt( ) 组合原始数据的两种测量(quality 和
durability),并生成一个名为 measure 的列和一个度量值列:
toy_tests2 <- melt(toy_tests, id.vars = c("id", "ym"),
measure.vars = c("quality", "durability"),
variable.name = "measure")
toy_tests2
## id ym measure value
## 1 T01 201602 quality 9
## 2 T01 201603 quality 10
## 3 T01 201604 quality 9
## 4 T01 201605 quality 9
## 5 T02 201602 quality 7
## 6 T02 201603 quality 8
## 7 T02 201604 quality 9
## 8 T02 201605 quality 10
## 9 T01 201602 durability 9
## 10 T01 201603 durability 9
## 11 T01 201604 durability 10
## 12 T01 201605 durability 9
## 13 T02 201602 durability 9
## 14 T02 201603 durability 8
## 15 T02 201604 durability 8
## 16 T02 201605 durability 9
现在,变量名就出现在数据中了,可以被扩展包直接使用。例如,针对这种格式的数据,
我们使用 ggplot2 扩展包来画图。以下代码先对不同的因子组合进行分面,然后绘制散点图:
library(ggplot2)
ggplot(toy_tests2, aes(x = ym, y = value)) +
geom_ _point() +
facet_ _grid(id ~ measure)
这样,我们便得到了一个按照产品 id 和 measure 分组,并以 ym 为 x 轴,以 value
为 y 轴的散点图,如图 12-1 所示。
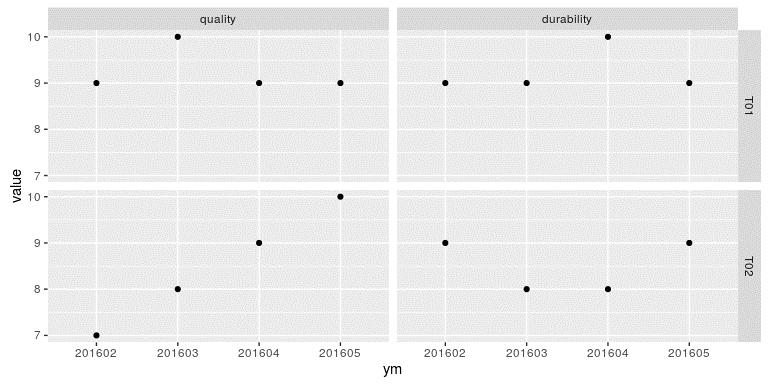
图 12-1
因为分组因子包含在数据中,而不是列名,因此可以很方便地通过透视图将其表示出来。
这次,我们用两种不同颜色的点表示两种产品,如图 12-2 所示。
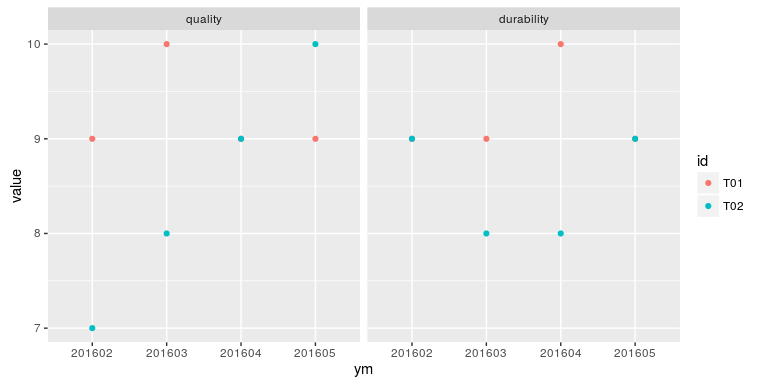
图 12-2
ggplot(toy_tests2, aes(x = ym, y = value, color = id)) +
geom_ _point() +
facet_ _grid(. ~ measure)
使用 reshape2 重塑数据框的更多相关文章
- R实战 第八篇:重塑数据(reshape2)
数据重塑通常使用reshape2包,reshape2包用于实现对宽数据及长数据之间的相互转换,由于reshape2包不在R的默认安装包列表中,在第一次使用之前,需要安装和引用: install.pac ...
- R语言学习4:函数,流程控制,数据框重塑
本系列是一个新的系列,在此系列中,我将和大家共同学习R语言.由于我对R语言的了解也甚少,所以本系列更多以一个学习者的视角来完成. 参考教材:<R语言实战>第二版(Robert I.Kaba ...
- R语言Data Frame数据框常用操作
Data Frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成,与Matrix不同的是,每个列可以是不同的数据类型,而Matrix是必须相同的. Data Frame每一列有列名,每一行也可 ...
- R语言基础:数组&列表&向量&矩阵&因子&数据框
R语言基础:数组和列表 数组(array) 一维数据是向量,二维数据是矩阵,数组是向量和矩阵的直接推广,是由三维或三维以上的数据构成的. 数组函数是array(),语法是:array(dadta, d ...
- R语言数据框行转列实例
目的:须要把数据框的行列进行转置 方法: # 原始数据框 > hrl_jd_mon 年份 一月 二月 三月 四月 五月 六月 七月 八月 九月 十月 十一月 十二月 1 2010年 51 ...
- R语言笔记1--向量、数组、矩阵、数据框、列表
注释:R语言是区分大小写的 1.向量 R语言中可以将各种向量赋值为一个变量,这种赋值操作符就是等号“=”,也可以使用“<-”. 1)产生向量 (1)函数c() 例如:x1=c(2,4,6,8,0 ...
- R语言数据分析利器data.table包 —— 数据框结构处理精讲
R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代码简洁,只要一行命令就可以完成诸多任务,另一方面是处理 ...
- R学习笔记 第三篇:数据框
数据框(data.frame)用于存储二维表(即关系表)的数据,每一列存储的数据类型必须相同,不同的数据列的数据类型可以相同,也可以不同,但是,每列的长度必须相同.数据框的每列可以有唯一的命名,在已创 ...
- R语言数据框中,用0替代NA缺失值
1.用0替代数据框中的缺失值NA 生成数据框: > m <- matrix(sample(c(NA, :), , replace = TRUE), ) > d <- as.da ...
随机推荐
- linux的~和/的区别
转自:https://zhidao.baidu.com/question/166486946.html /是目录层的分隔.表示符.只有一个/表明是root,/etc/表明是根目录下面的etc目录(当然 ...
- oracle的with as用法
转自:https://www.cnblogs.com/linjiqin/archive/2013/06/24/3152667.html with as语法–针对一个别名with tmp as (sel ...
- 微信小程序 --- loading提示框
loading:提示框: 效果: loading和toast和像,只不过 toast 是设置结束时间,时间到了去触发bindchange事件,进行隐藏. 但是 loading 是没有办法设置事件让其隐 ...
- 百度地图API开发----手机地图做导航功能
第一种方式:手机网页点击打开直接进百度地图APP <a href="baidumap://map/direction?mode=[transit:公交,driving:驾车]& ...
- wampserver3 集成环境 启动Apache失败
前提:安装完成后,原先是能够启动服务,但是按照网上教程修改conf文件后就不能启动Apache, 方法: 1.查看Apache错误日志(无奈的是看不懂) 2.在cmd命令行中查看,(打开cmd,输入: ...
- pta 习题集5-19 列车厢调度
1 ====== <--移动方向 / 3 ===== \ 2 ====== -->移动方向 大家或许在某些数据结构教材上见到过"列车厢调度问题"(当然没见过也不要紧). ...
- MongoDB Windows环境安装及配置( 一)
原文http://www.cnblogs.com/lzrabbit/p/3682510.html MongoDB一般安装 1.首先到官网 (http://www.mongodb.org/downloa ...
- 自己主动检測&后台复制光盘内容
原理:利用python的win32模块,注冊服务,让代码在后台执行,检測光盘并复制文件 启动的方法就是直接在cmd下,main.py install ,然后去windows 的服务下就能够看到The ...
- nodejs中Async详解之一:流程控制
为了适应异步编程,减少回调的嵌套,我尝试了很多库.最终觉得还是async最靠谱. 地址:https://github.com/caolan/async Async的内容分为三部分: 流程控制:简化十种 ...
- Windows上的巧克力味Chocolatey详解
Chocolatey是什么?很简单,Chocolatey就是Windows系统的yum或apt-get. 一.Chocolatey介绍 Chocolatey是一款专为Windows系统开发的.基于Nu ...