MindSpore 数据加载及处理
参考地址:
https://www.mindspore.cn/tutorial/zh-CN/r1.2/dataset.html
========================================================
数据集下载:
mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test
wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte
wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte
wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte
wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte
tree ./datasets/MNIST_Data
顺序读取N个样本:
import mindspore.dataset as ds
from mindspore import dtype as mstype DATA_DIR = "./datasets/MNIST_Data/train"
sampler = ds.SequentialSampler(num_samples=3)
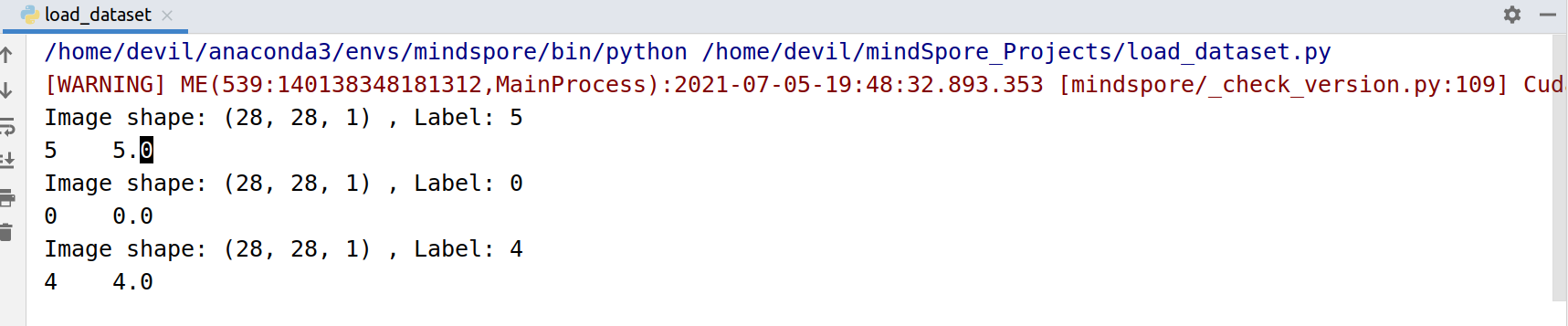
dataset = ds.MnistDataset(DATA_DIR, sampler=sampler) for data in dataset.create_dict_iterator():
print("Image shape: {}".format(data['image'].shape), ", Label: {}".format(data['label']))
print(data['label'], "\t", data['label'].astype(mstype.float32))
自定义数据集
import mindspore.dataset as ds import numpy as np np.random.seed(58) class DatasetGenerator:
def __init__(self):
self.data = np.random.sample((5, 2))
self.label = np.random.sample((5, 1)) def __getitem__(self, index):
return self.data[index], self.label[index] def __len__(self):
return len(self.data) dataset_generator = DatasetGenerator()
dataset = ds.GeneratorDataset(dataset_generator, ["data", "label"], shuffle=False) for i, data in enumerate(dataset.create_dict_iterator()):
print("第 %d 个样本"%i)
print('{}'.format(data["data"]), '{}'.format(data["label"]))

对自定义数据集进行一定预处理:
import mindspore.dataset as ds import numpy as np np.random.seed(58) class DatasetGenerator:
def __init__(self):
self.data = np.random.sample((5, 2))
self.label = np.random.sample((5, 1)) def __getitem__(self, index):
return self.data[index], self.label[index] def __len__(self):
return len(self.data) dataset_generator = DatasetGenerator()
dataset = ds.GeneratorDataset(dataset_generator, ["data", "label"], shuffle=False) # 随机打乱数据顺序
dataset = dataset.shuffle(buffer_size=10)
# 对数据集进行分批
dataset = dataset.batch(batch_size=2) for i, data in enumerate(dataset.create_dict_iterator()):
print("第 %d 次选取样本"%i)
print("data: \n{}".format(data["data"]))
print("label: \n{}".format(data["label"]))

数据处理及增强
import matplotlib.pyplot as plt import mindspore.dataset as ds
from mindspore.dataset.vision import Inter
import mindspore.dataset.vision.c_transforms as c_vision DATA_DIR = './datasets/MNIST_Data/train'
_number_samples = 3 mnist_dataset = ds.MnistDataset(DATA_DIR, num_samples=_number_samples, shuffle=False) resize_op = c_vision.Resize(size=(200,200), interpolation=Inter.LINEAR)
crop_op = c_vision.RandomCrop(150) # 随机将图像裁剪成150尺寸
transforms_list = [resize_op, crop_op]
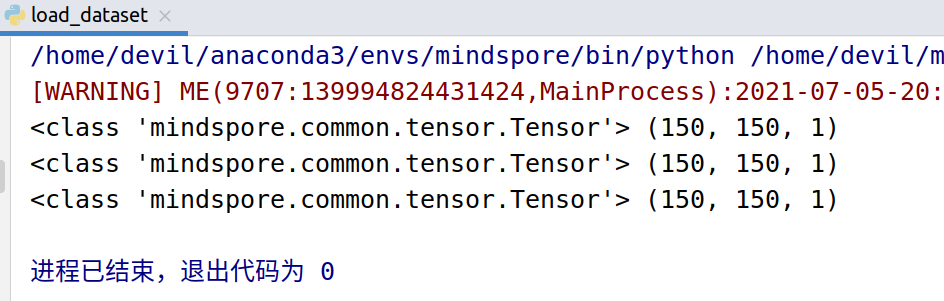
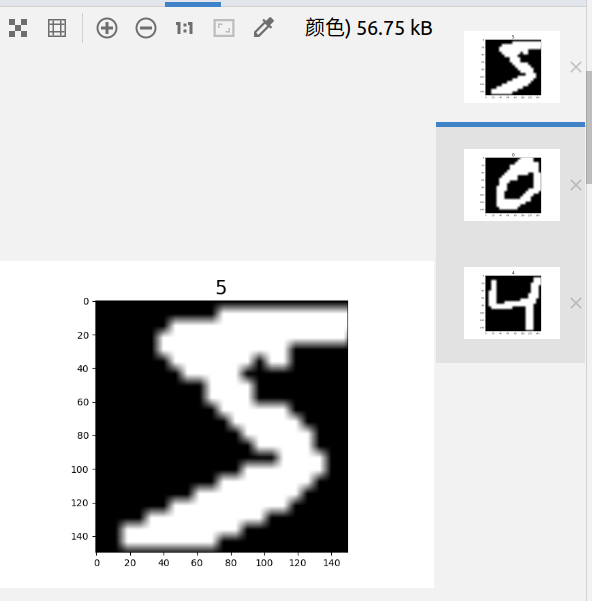
mnist_dataset = mnist_dataset.map(operations=transforms_list, input_columns=["image"]) # 查看数据原图
mnist_it = mnist_dataset.create_dict_iterator() for _ in range(_number_samples):
data = next(mnist_it)
print(type(data['image']), data['image'].shape) plt.imshow(data['image'].asnumpy().squeeze(), cmap=plt.cm.gray)
plt.title(data['label'].asnumpy(), fontsize=20)
plt.show()
MindSpore 数据加载及处理的更多相关文章
- ScrollView嵌套ListView,GridView数据加载不全问题的解决
我们大家都知道ListView,GridView加载数据项,如果数据项过多时,就会显示滚动条.ScrollView组件里面只能包含一个组件,当ScrollView里面嵌套listView,GridVi ...
- python多种格式数据加载、处理与存储
多种格式数据加载.处理与存储 实际的场景中,我们会在不同的地方遇到各种不同的数据格式(比如大家熟悉的csv与txt,比如网页HTML格式,比如XML格式),我们来一起看看python如何和这些格式的数 ...
- flask+sqlite3+echarts3+ajax 异步数据加载
结构: /www | |-- /static |....|-- jquery-3.1.1.js |....|-- echarts.js(echarts3是单文件!!) | |-- /templates ...
- Entity Framework关联查询以及数据加载(延迟加载,预加载)
数据加载分为延迟加载和预加载 EF的关联实体加载有三种方式:Lazy Loading,Eager Loading,Explicit Loading,其中Lazy Loading和Explicit Lo ...
- JQuery插件:遮罩+数据加载中。。。(特点:遮你想遮,罩你想罩)
在很多项目中都会涉及到数据加载.数据加载有时可能会是2-3秒,为了给一个友好的提示,一般都会给一个[数据加载中...]的提示.今天就做了一个这样的提示框. 先去jQuery官网看看怎么写jQuery插 ...
- 如何评估ETL的数据加载时间
简述如何评估大型ETL数据加载时间. 答:评估一个大型的ETL的数据加载时间是一件很复杂的事情.数据加载分为两类,一类是初次加载,另一类是增量加载. 在数据仓库正式投入使用时,需要进行一次初次加载,而 ...
- 浅谈Entity Framework中的数据加载方式
如果你还没有接触过或者根本不了解什么是Entity Framework,那么请看这里http://www.entityframeworktutorial.net/EntityFramework-Arc ...
- 实现虚拟模式的动态数据加载Windows窗体DataGridView控件 .net 4.5 (一)
实现虚拟模式的即时数据加载Windows窗体DataGridView控件 .net 4.5 原文地址 :http://msdn.microsoft.com/en-us/library/ms171624 ...
- Android Volley和Gson实现网络数据加载
Android Volley和Gson实现网络数据加载 先看接口 1 升级接口 http://s.meibeike.com/mcloud/ota/cloudService POST请求 参数列表如下 ...
- Echarts通过Ajax实现动态数据加载
Echarts(3.x版)官网实例的数据都是静态的,实际使用中往往会要求从服务器端取数据进行动态显示,官网教程里给出的异步数据加载很粗略,下面就以官网最简单的实例为例子,详细演示如下过程:1.客户端通 ...
随机推荐
- (五)基于selenium实现12306模拟登陆
这里介绍一款强大验证码识别平台:超级鹰 - 超级鹰:http://www.chaojiying.com/about.html - 注册:普通用户 - 登录:普通用户 - 题分查询:充值 - 创建一个软 ...
- star 最多的 Go 语言本地化库|GitHub 2.8K
如果你是一位 Go 用户,可以在我开源的学习仓库中,找到针对各种往期归档文章,及学习资料. B站:白泽talk,公众号[白泽talk],回复"电子书",即可获得包含<100个 ...
- 前端React的事件机制
前端React技术框架的事件机制不同于常见的事件机制--原生事件,此文将介绍React的事件机制是什么,与原生事件的区别,以及这两种事件机制是否可以混用等.希望您在阅读这篇文章之后,能够对React的 ...
- 接口签名规则及Java代码demo实现
接口签名规则及Java代码demo实现 签名规则 签名生成的通用步骤如下: 第一步,设所有发送或者接收到的数据为集合M,将集合M内非空参数值的参数按照参数名ASCII码从小到大排序(字典序),使用UR ...
- CF1523D Love-Hate
抽象化题意: 一共有 \(m\) 个元素,给定 \(n\) 个集合,每个集合的元素不超过 \(15\) 个,求出一个元素个数最多的集合 \(S\) 是至少 \(\lceil \dfrac{n}{2} ...
- go语言的基础语法
字符串数组 package main import ( "fmt" ) func main() { var str string str = "hello world&q ...
- useCookie函数:管理SSR环境下的Cookie
title: useCookie函数:管理SSR环境下的Cookie date: 2024/7/13 updated: 2024/7/13 author: cmdragon excerpt: 摘要:本 ...
- 宇宙最强开发工具VScode快速搭建前后端分离环境【VUE+Springboot】
VS Code 的全称是 Visual Studio Code,是一款开源的.免费的.跨平台的.高性能的.轻量级的代码编辑器.它在性能.语言支持.开源社区方面,都做得很不错,是这两年非常热门的一款开发 ...
- iOS开发基础135-Core Data
Objective-C (OC) 中使用 Core Data 是iOS应用开发中管理模型层对象的一种有效工具.Core Data 使用 ORM (对象关系映射) 技术来抽象化和管理数据.这不仅可以节省 ...
- GraphRAG介绍
GraphRAG GraphRAG 是一种基于图的检索增强方法,由微软开发并开源.它通过结合LLM和图机器学习的技术,从非结构化的文本中提取结构化的数据,构建知识图谱,以支持问答.摘要等多种应用场景. ...