scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法
Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以从这里我们可以知道下载中间件是介于Scrapy的request/response处理的钩子,用于修改Scrapy request和response。
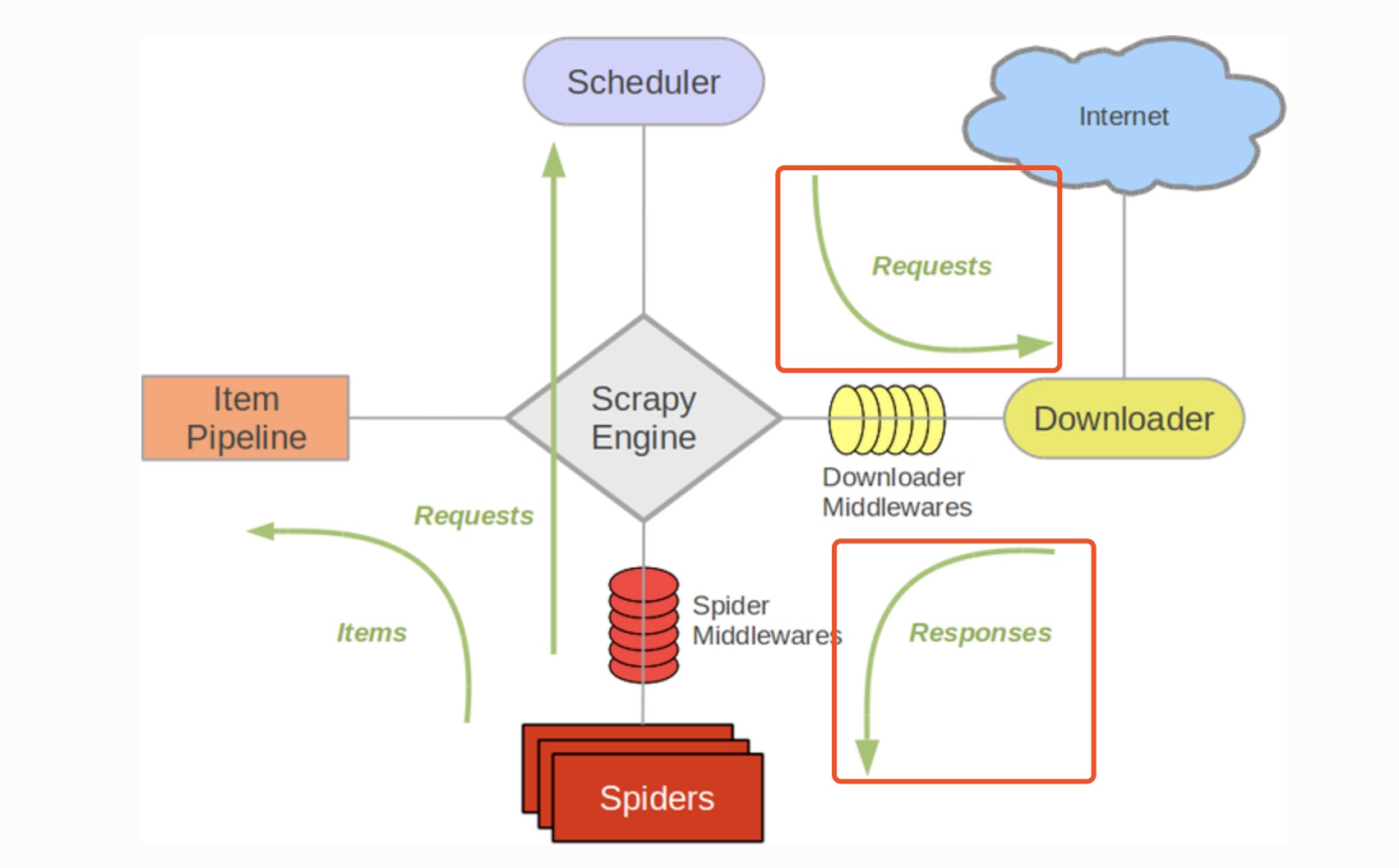
编写自己的下载器中间件
编写下载器中间件,需要定义以下一个或者多个方法的python类
为了演示这里的中间件的使用方法,这里创建一个项目作为学习,这里的项目是关于爬去httpbin.org这个网站
scrapy startproject httpbintest
cd httpbintest
scrapy genspider example example.com
创建好后的目录结构如下:
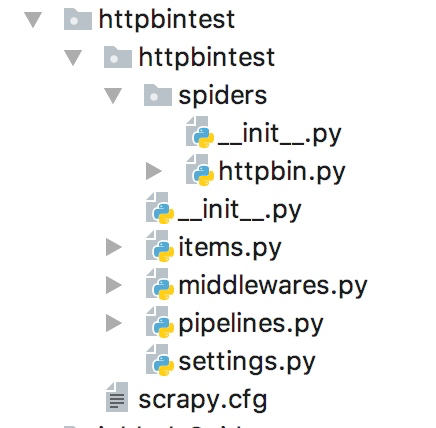
这里我们先写一个简单的代理中间件来实现ip的伪装
创建好爬虫之后我们讲httpbin.py中的parse方法改成:
def parse(self, response):
print(response.text)
然后通过命令行启动爬虫:scrapy crawl httpbin
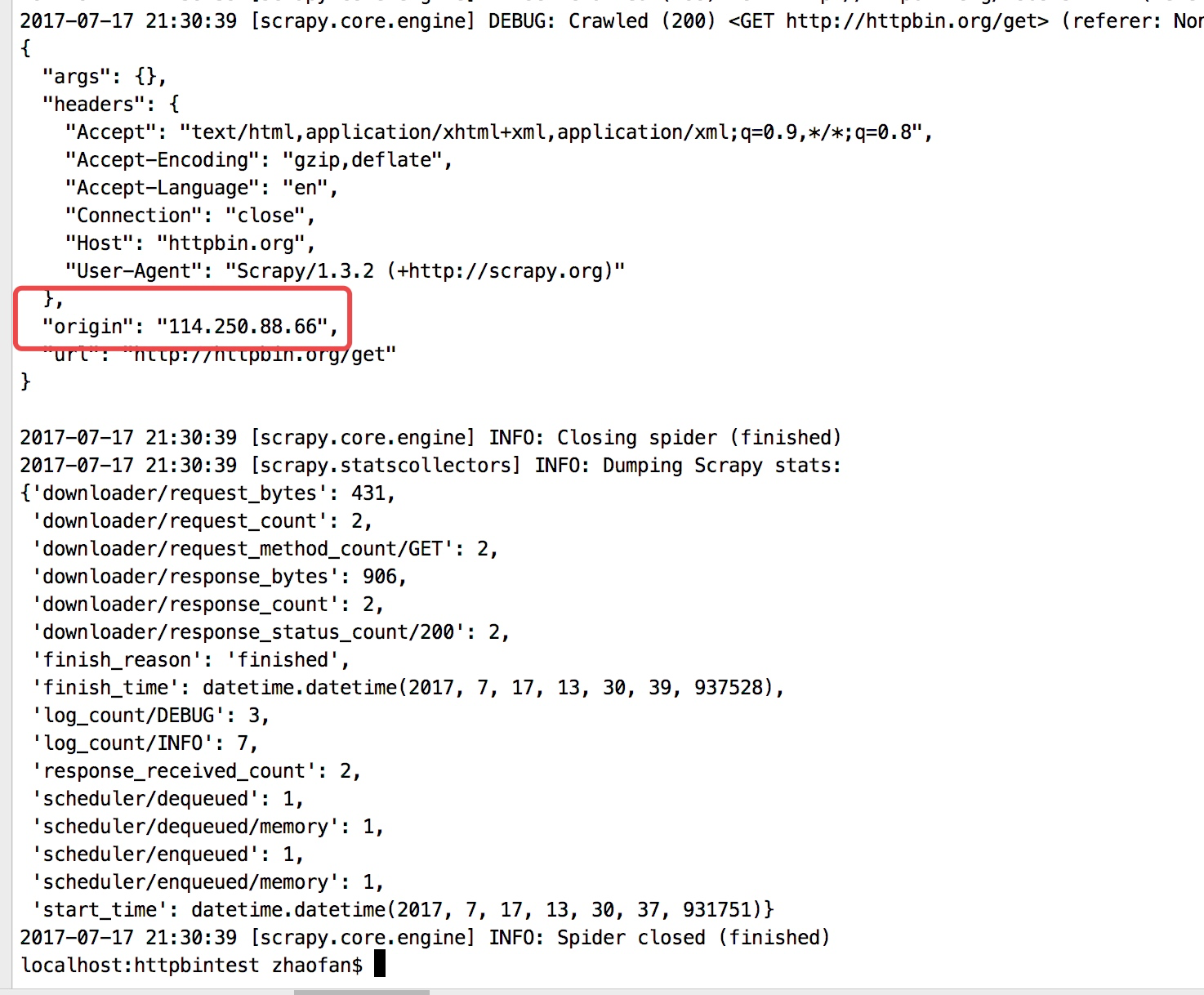
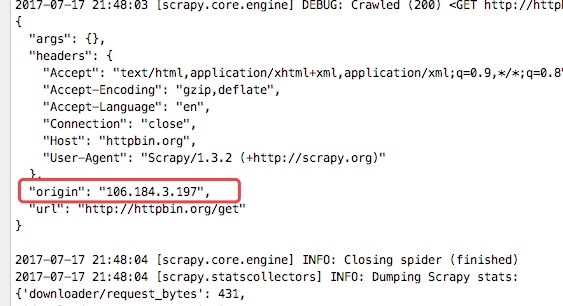
在最下面我们可以看到"origin": "114.250.88.66"
我们在查看自己的ip:
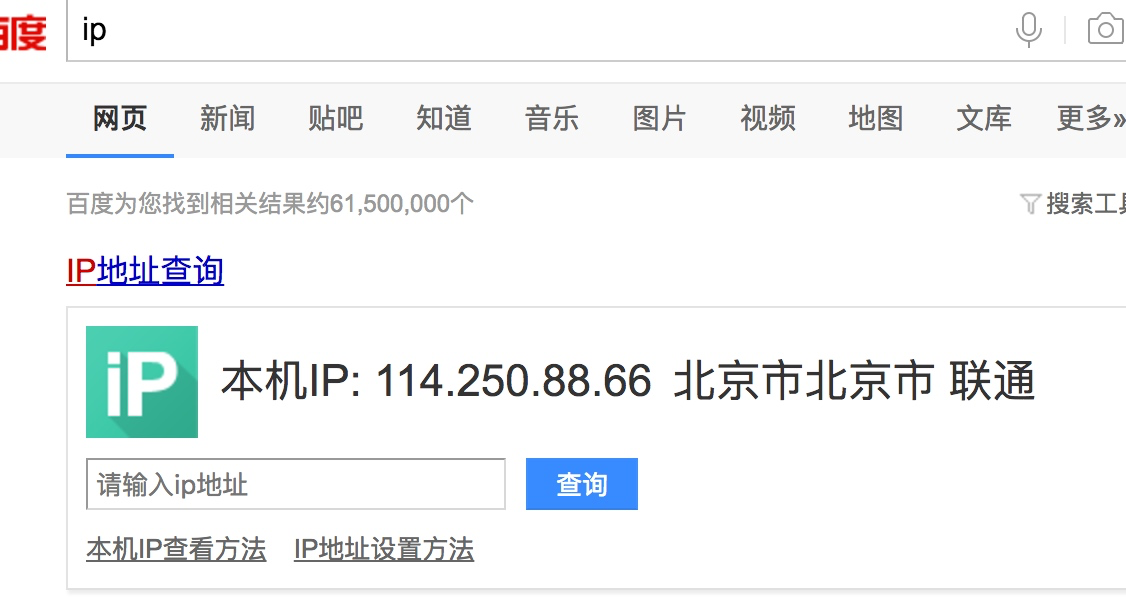
而我们要做就是通过代理中间件来实现ip的伪装,在middleares.py中写如下的中间件类:

class ProxyMiddleare(object):
logger = logging.getLogger(__name__)
def process_request(self,request, spider):
self.logger.debug("Using Proxy")
request.meta['proxy'] = 'http://127.0.0.1:9743'
return None
这里因为我本地有一个代理FQ地址为:http://127.0.0.1:9743
所以直接设置为代理用,代理的地址为日本的ip
然后在settings.py配置文件中开启下载中间件的功能,默认是关闭的
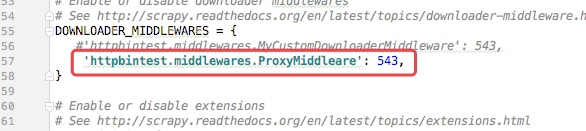
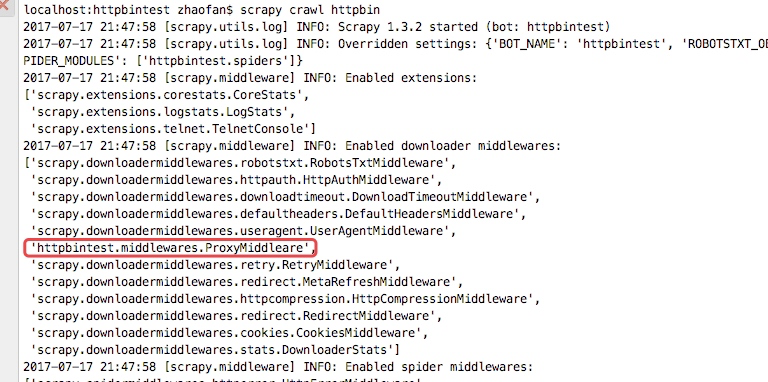
然后我们再次启动爬虫:scrapy crawl httpbin
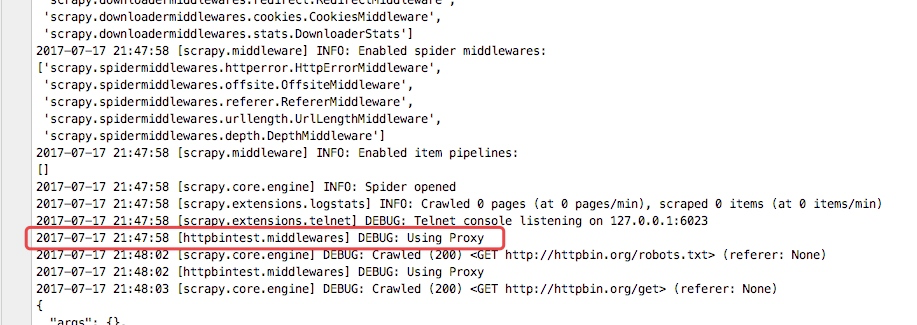
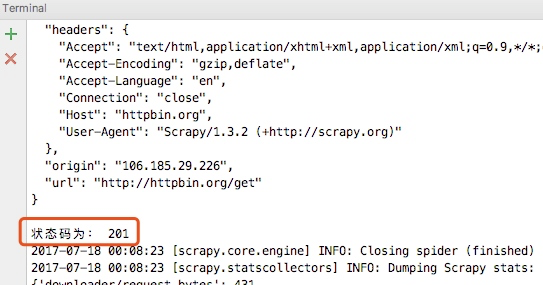
从下图的输入日志中我们可以看书我们定义的中间件已经启动,并且输入了我们打印的日志信息,并且我们查看origin的ip地址也已经成了日本的ip地址,这样我们的代理中间件成功了
详细说明
class Scrapy.downloadermiddleares.DownloaderMiddleware
process_request(request,spider)
当每个request通过下载中间件时,该方法被调用,这里有一个要求,该方法必须返回以下三种中的任意一种:None,返回一个Response对象,返回一个Request对象或raise IgnoreRequest。三种返回值的作用是不同的。
None:Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该request被执行(其response被下载)。
Response对象:Scrapy将不会调用任何其他的process_request()或process_exception() 方法,或相应地下载函数;其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
Request对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
raise一个IgnoreRequest异常:则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录。
process_response(request, response, spider)
process_response的返回值也是有三种:response对象,request对象,或者raise一个IgnoreRequest异常
如果其返回一个Response(可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
这里我们写一个简单的例子还是上面的项目,我们在中间件中继续添加如下代码:
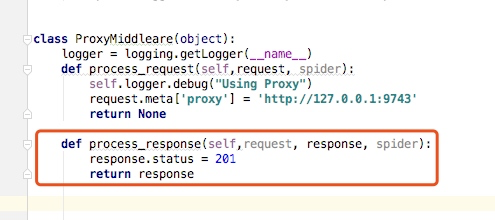
然后在spider中打印状态码:

这样当我们重新运行爬虫的时候就可以看到如下内容
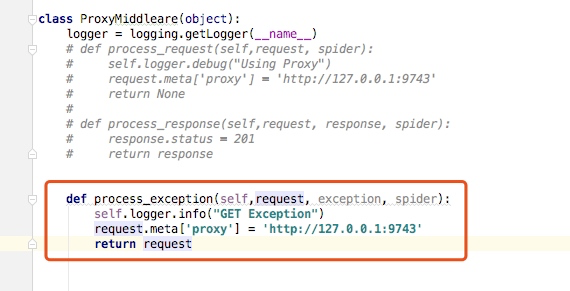
process_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时,Scrapy调用 process_exception()。
process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。 这个是非常有用的,就相当于如果我们失败了可以在这里进行一次失败的重试,例如当我们访问一个网站出现因为频繁爬取被封ip就可以在这里设置增加代理继续访问,我们通过下面一个例子演示
scrapy genspider google www.google.com 这里我们创建一个谷歌的爬虫,
然后启动scrapy crawl google,可以看到如下情况:
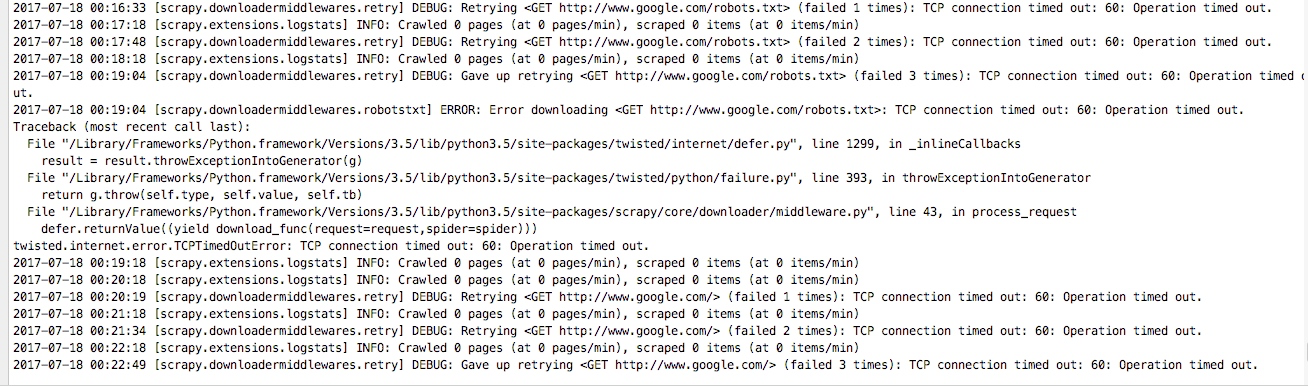
这里我们就写一个中间件,当访问失败的时候增加代理
首先我们把google.py代码进行更改,这样是白超时时间设置为10秒要不然等待太久,这个就是我们将spider里的时候的讲过的make_requests_from_url,这里我们把这个方法重写,并将等待超时时间设置为10s
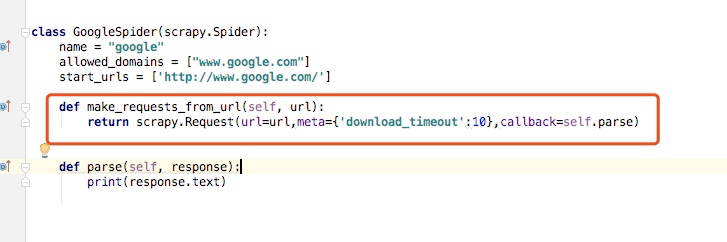
这样我重新启动爬虫:scrapy crawl google,可以看到如下:
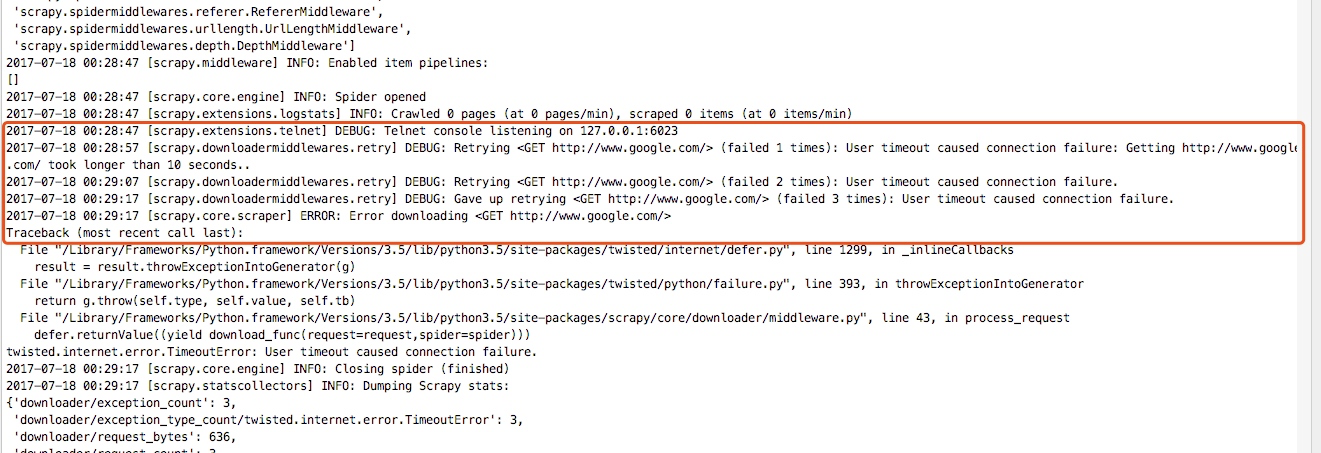
这里如果我们不想让重试,可以把重试中间件关掉:
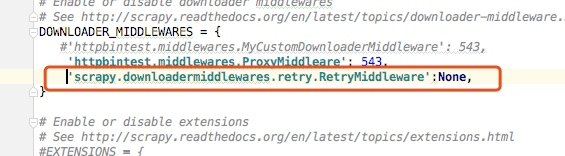
这样设置之后我们就把失败重试的中间件给关闭了,设置为None就表示关闭这个中间件,重新启动爬虫我们也可以看出没有进行重试直接报错了
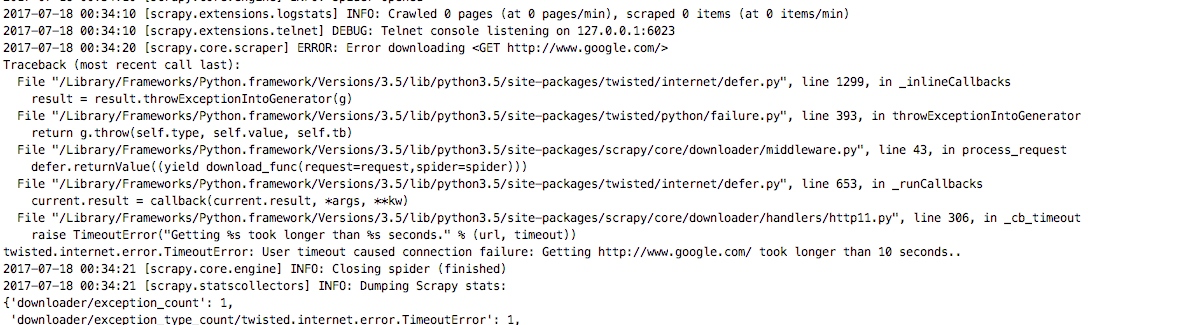
我们将代理中间件的代理改成如下,表示遇到异常的时候给请求加上代理,并返回request,这个样就会重新请求谷歌
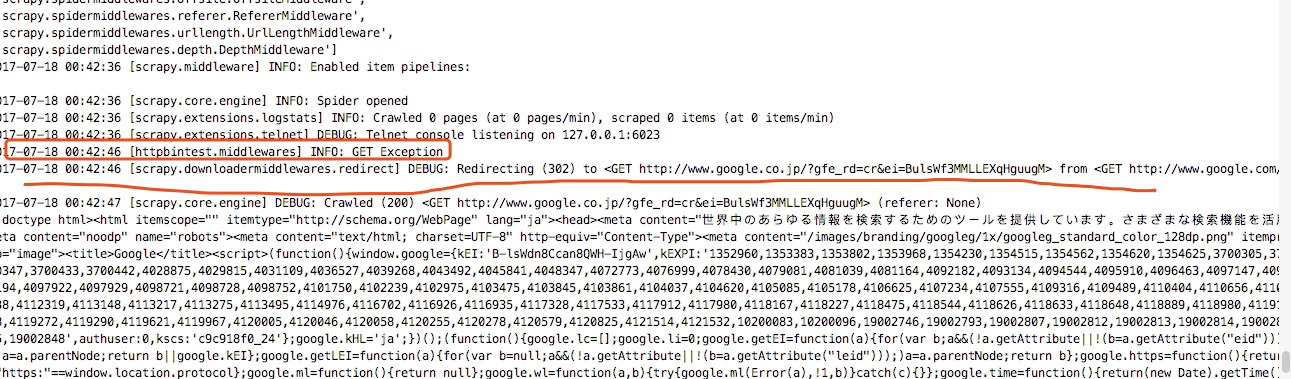
重新启动谷歌爬虫,我们可以看到,我们第一次返回我们打印的日志信息GET Exception,然后加上代理后成功访问了谷歌,这里我的代理是日本的代理节点,所以访问到的是日本的谷歌站
scrapy框架中Download Middleware用法的更多相关文章
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python之爬虫(十九) Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- 7-----Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送 requests请求的时候以及网页将 response结果返回给 spiders的时候 ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
随机推荐
- VVDocument+Appledoc生成文档
在写代码的时候写上适当的注释是一种良好的习惯,方便自己或者别人阅读的方便. **VVDocument**:(Github地址:[VVDocument](https://github.com/onevc ...
- Safair浏览器 时间戳转化兼容性问题。
chrome 等浏览器支持 yyyy-MM-dd hh:mm:ss 格式,使用 Date.parse()进行转化 safair 浏览器不知道这种格式,需要将格式设置为 yyyy/MM/dd hh:mm ...
- Linux随笔-鸟哥Linux基础篇学习总结(全)
Linux随笔-鸟哥Linux基础篇学习总结(全) 修改Linux系统语系:LANG-en_US,如果我们想让系统默认的语系变成英文的话我们可以修改系统配置文件:/etc/sysconfig/i18n ...
- cygwin使用笔记
1.在cygwin里访问Windows盘 cd /cygdrive/c cd c: 2.整合cygwin命令到Windows中 假设cygwin安装在d:/develop/cygwin,则将d:/de ...
- 关于lock锁
在 jdk1.5 之后,并发包中新增了 Lock 接口(以及相关实现类)用来实现锁功能,Lock 接口提供了与 synchronized 关键字类似的同步功能,但需要在使用时手动获取锁和释放锁. lo ...
- wait()和notify()
从https://www.cnblogs.com/toov5/p/9837373.html 可以看到他的打印是一片一片的,这边博客介绍怎么避免掉 使用notify 和 wait的时候 要注意 是在sy ...
- 【mysql】mysql innodb 配置详解
MySQL innodb 配置详解 innodb_buffer_pool_size:这是InnoDB最重要的设置,对InnoDB性能有决定性的影响.默认的设置只有8M,所以默认的数据库设置下面Inno ...
- html5--4-1 video/视频播放
html5--4-1 video/视频播放 学习要点 掌握video元素的基本用法 直到现在,在网页中的大多数视频是通过插件(比如 Flash)来显示的.然而,并非所有浏览器都拥有同样的插件. HTM ...
- syslog格式
转自:http://wly719.iteye.com/blog/1827394 1.syslog格式介绍 在Unix类操作系统上,syslog广泛 应用于系统日志.syslog日志消息既可以记录在本地 ...
- 如何应用 AutoIt 修改本机的防火墙配置?(开启,关闭防火墙,添加程序信任到防火墙)
以前,公司的实施人员配置好项目之后,不同的机器之间经常性的无法建立链接,后来发现是防火墙的设置.虽然是个小问题,但是经常性的忘记这个配置. 现在,我决定把对防火墙的设置,加入到我给实施人员的配置工具中 ...