吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包
import pandas as pd
# 导入数据
Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\11\\Knowledge.xlsx')
print(Knowledge.shape)
# 返回前5行数据
print(Knowledge.head())
# 构造训练集和测试集
# 导入第三方模块
from sklearn import model_selection
# 将数据集拆分为训练集和测试集
predictors = Knowledge.columns[:-1]
X_train, X_test, y_train, y_test = model_selection.train_test_split(Knowledge[predictors], Knowledge.UNS,
test_size = 0.25, random_state = 1234)
# 导入第三方模块
import numpy as np
from sklearn import neighbors
import matplotlib.pyplot as plt
# 设置待测试的不同k值
K = np.arange(1,np.ceil(np.log2(Knowledge.shape[0])))
k = []
for i in range(len(K)):
k.append(int(K[i]))
K = np.array(k)
# 构建空的列表,用于存储平均准确率
accuracy = []
for k in K:
# 使用10重交叉验证的方法,比对每一个k值下KNN模型的预测准确率
cv_result = model_selection.cross_val_score(neighbors.KNeighborsClassifier(n_neighbors = k, weights = 'distance'),
X_train, y_train, cv = 10, scoring='accuracy')
accuracy.append(cv_result.mean())
# 从k个平均准确率中挑选出最大值所对应的下标
arg_max = np.array(accuracy).argmax()
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制不同K值与平均预测准确率之间的折线图
plt.plot(K, accuracy)
# 添加点图
plt.scatter(K, accuracy)
# 添加文字说明
plt.text(K[arg_max], accuracy[arg_max], '最佳k值为%s' %int(K[arg_max]))
# 显示图形
plt.show()
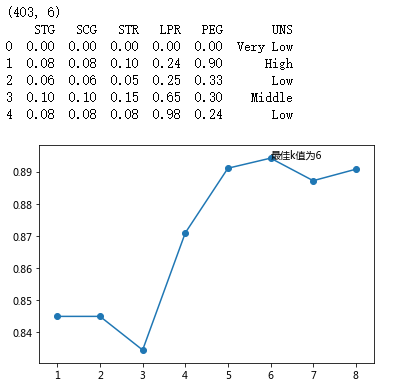
# 重新构建模型,并将最佳的近邻个数设置为6
knn_class = neighbors.KNeighborsClassifier(n_neighbors = 6, weights = 'distance')
# 模型拟合
knn_class.fit(X_train, y_train)
# 模型在测试数据集上的预测
predict = knn_class.predict(X_test)
# 构建混淆矩阵
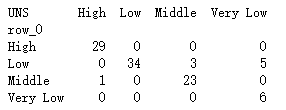
cm = pd.crosstab(predict,y_test)
print(cm)
# 导入第三方模块
import seaborn as sns
from sklearn import metrics
# 将混淆矩阵构造成数据框,并加上字段名和行名称,用于行或列的含义说明
cm = pd.DataFrame(cm)
# 绘制热力图
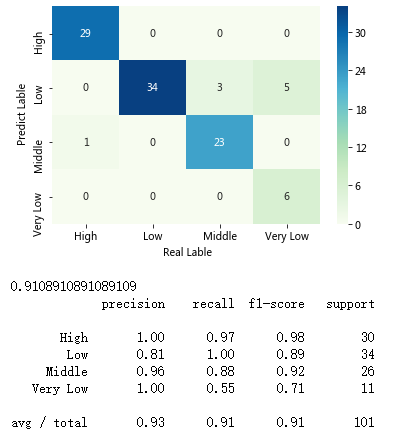
sns.heatmap(cm, annot = True,cmap = 'GnBu')
# 添加x轴和y轴的标签
plt.xlabel(' Real Lable')
plt.ylabel(' Predict Lable')
# 图形显示
plt.show()
# 模型整体的预测准确率
print(metrics.scorer.accuracy_score(y_test, predict))
# 分类模型的评估报告
print(metrics.classification_report(y_test, predict))
# 读入数据
ccpp = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\11\\CCPP.xlsx')
print(ccpp.shape)
print(ccpp.head())
# 导入第三方包
from sklearn import model_selection
from sklearn.preprocessing import minmax_scale
# 对所有自变量数据作标准化处理
predictors = ccpp.columns[:-1]
X = minmax_scale(ccpp[predictors])
print(X)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, ccpp.PE, test_size = 0.25, random_state = 1234)
# 设置待测试的不同k值
K = np.arange(1,np.ceil(np.log2(ccpp.shape[0])))
k = []
for i in range(len(K)):
k.append(int(K[i]))
K = np.array(k)
# 构建空的列表,用于存储平均MSE
mse = []
for k in K:
# 使用10重交叉验证的方法,比对每一个k值下KNN模型的计算MSE
cv_result = model_selection.cross_val_score(neighbors.KNeighborsRegressor(n_neighbors = k, weights = 'distance'),
X_train, y_train, cv = 10, scoring='neg_mean_squared_error')
mse.append((-1*cv_result).mean())
# 从k个平均MSE中挑选出最小值所对应的下标
arg_min = np.array(mse).argmin()
# 绘制不同K值与平均MSE之间的折线图
plt.plot(K, mse)
# 添加点图
plt.scatter(K, mse)
# 添加文字说明
plt.text(K[arg_min], mse[arg_min] + 0.5, '最佳k值为%s' %int(K[arg_min]))
# 显示图形
plt.show()
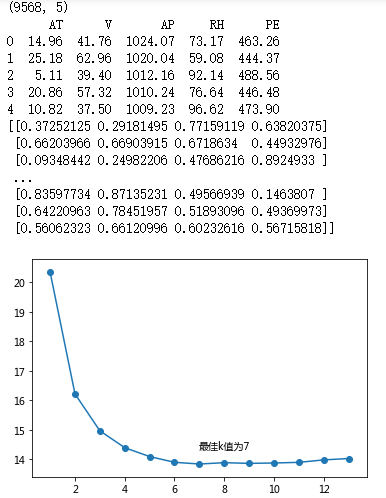
# 重新构建模型,并将最佳的近邻个数设置为7
knn_reg = neighbors.KNeighborsRegressor(n_neighbors = 7, weights = 'distance')
# 模型拟合
knn_reg.fit(X_train, y_train)
# 模型在测试集上的预测
predict = knn_reg.predict(X_test)
# 计算MSE值
a = metrics.mean_squared_error(y_test, predict)
print(a)
# 对比真实值和实际值
b = pd.DataFrame({'Real':y_test,'Predict':predict}, columns=['Real','Predict']).head(10)
print(b)
# 导入第三方模块
from sklearn import tree
# 预设各参数的不同选项值
max_depth = [19,21,23,25,27]
min_samples_split = [2,4,6,8]
min_samples_leaf = [2,4,8,10,12]
parameters = {'max_depth':max_depth, 'min_samples_split':min_samples_split, 'min_samples_leaf':min_samples_leaf}
# 网格搜索法,测试不同的参数值
grid_dtreg = model_selection.GridSearchCV(estimator = tree.DecisionTreeRegressor(), param_grid = parameters, cv=10)
# 模型拟合
grid_dtreg.fit(X_train, y_train)
# 返回最佳组合的参数值
print(grid_dtreg.best_params_)

# 构建用于回归的决策树
CART_Reg = tree.DecisionTreeRegressor(max_depth = 21, min_samples_leaf = 10, min_samples_split = 6)
# 回归树拟合
CART_Reg.fit(X_train, y_train)
# 模型在测试集上的预测
pred = CART_Reg.predict(X_test)
# 计算衡量模型好坏的MSE值
a = metrics.mean_squared_error(y_test, pred)
print(a)

吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfr ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
- 吴裕雄 数据挖掘与分析案例实战(2)——python数据结构及方法、控制流、字符串处理、自定义函数
list1 = ['张三','男',33,'江苏','硕士','已婚',['身高178','体重72']]# 取出第一个元素print(list1[0])# 取出第四个元素print(list1[3] ...
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt # 自定义绘制ks曲线的函数def plot_ks(y_tes ...
随机推荐
- php设计模式之职责链模式
<?php /** * @desc php设计模式之职责链模式(责任链模式) 定义:顾名思义,责任链模式为请求创建了一个接收者对象的链.这种模式给予请求的类型,对请求的发送者和接收者进行解耦.这 ...
- 【python】实例-把两个无规则的序列连接成一个序列,并删除重复的元素,新序列按照升序排序
list_one=[3,6,2,17,7,33,11,7] list_two=[1,2,3,7,4,2,17,33,11] list_new=list_one+list_two list=[] i=0 ...
- ComboBox智能搜索功能
cmbList.AutoCompleteSource = AutoCompleteSource.ListItems; cmbList.AutoCompleteMode = AutoCompleteMo ...
- 10个CSS+HOVER 的创意按钮
CSS hover 样式很简单,但是想创造出有意思.实用.有创意性的特效是很考验设计师的创意能力,所以设计达人每隔一段时间都会分享一些与鼠标点击.悬停的相关特效,以便大家获得更好的创造灵感. 今天我们 ...
- Redis在Windows集群中的错误
创建集群: ./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:70 ...
- 【Spring-AOP-学习笔记-6】@AfterThrowing增强处理简单示例
项目结构 业务代码 @Component("hello") public class HelloImpl implements Hello { // 定义一个简单方法,模拟 ...
- LINUX关机指令
linux下常用的关机命令有:shutdown.halt.poweroff.init:重启命令有:reboot.下面本文就主要介绍一些常用的关机命令以及各种关机命令之间的区别和具体用法. 首先来看一下 ...
- 1034 Head of a Gang (30 分)
1034 Head of a Gang (30 分) One way that the police finds the head of a gang is to check people's pho ...
- chronyd时间服务器同步时间配置
chrony是两个用来维持计算机系统时钟准确性的程序,这两个程序命名为chronyd和chronyc. chronyd是一个在系统后台运行的守护进程.他根据网络上其他时间服务器时间来测量本机时间的偏移 ...
- 第3章 文件I/O(4)_dup、dup2、fcntl和ioctl函数
5. 其它I/O系统调用 (1)dup和dup2函数 头文件 #include<unistd.h> 函数 int dup(int oldfd); int dup2(int oldfd, i ...